21. Okt. 2025·7 Min.
E‑Mail‑Qualitätsmetriken, die Sie im Zeitverlauf überwachen sollten (und warum)
E‑Mail‑Qualitätsmetriken zeigen, wo schlechte Anmeldungen herkommen und was sie kosten. Verfolgen Sie ungültige, wegwerfbare und Domain‑/MX‑Fehler und verknüpfen Sie sie mit Aktivierung.
Was Sie wirklich messen wollen (einfach gesagt)
„E‑Mail‑Qualität“ ist einfach: Können Sie diese Person erreichen, und sieht die Adresse so aus, als gehöre sie zu einem echten, interessierten Nutzer?
Bei einem Anmelde‑ oder Lead‑Formular ist eine qualitativ hochwertige E‑Mail eine Adresse, die Mails empfangen kann, nicht temporär oder wegwerfbar ist und ein geringes Risiko zeigt (kein bekannter Trap oder ein Muster, das oft zu Beschwerden führt). Es geht nicht um Beurteilung der Person, sondern darum, ob die Adresse als verlässlicher Kanal funktioniert.
Wenn die Qualität sinkt, merkt man das schnell:
- Mehr Bounces, was Sender‑Reputation und Zustellbarkeit schadet
- Geringere Aktivierung, weil Nutzer Verifikations‑ oder Willkommensmails nie sehen
- Ein CRM voller toter Leads, das Nachverfolgungskapazitäten verschwendet
- Lärm in den Analytics (es sieht so aus, als würden „Anmeldungen steigen“, aber echte Nutzer tun das nicht)
Monitoring ist nicht nur hübsche Diagramme. Es ist Früherkennung und schnelle Diagnose. Nützliche Metriken sagen Ihnen zwei Dinge: was sich geändert hat und woher es kam (Kampagne, Traffic‑Quelle, Land, bestimmtes Formular oder ein neuer Partner).
Beispiel: Sie starten eine Promo und die Anmeldungen steigen um 30 %. Eine Woche später aktivieren weniger Nutzer. Wenn Sie E‑Mail‑Qualität tracken, sehen Sie vielleicht, dass sich die Wegwerf‑Adressen in diesem Zeitraum verdoppelt haben oder Domain‑/MX‑Fehler anstiegen. Das weist auf Bot‑Traffic, ein defektes Formularfeld oder eine Quelle mit niedriger Intent hin.
Legen Sie Erwartungen früh fest: Jede Kennzahl sollte einer Aktion zugeordnet sein. Wenn ein Wert steigt, sollten Sie bereits wissen, ob das bedeutet, die Validierung zu verschärfen, eine Kampagne anzupassen, mehr Reibung bei verdächtigem Traffic einzubauen oder einen einmaligen Ausfall zu untersuchen.
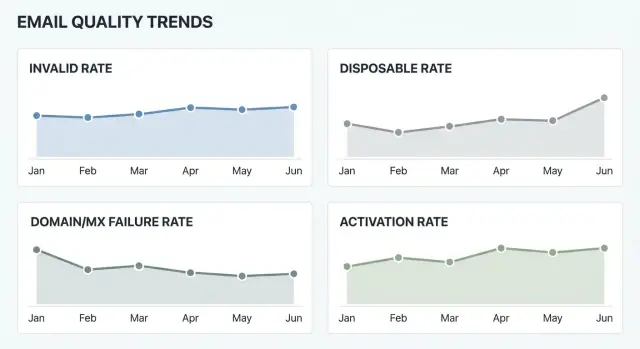
Die Kernmetriken: Ungültig, Wegwerf und Domain‑/MX‑Fehler
Wenn Sie Metriken wollen, die über die Zeit nützlich bleiben, halten Sie die „Kern‑Drei“ einfach und klar definiert. Diese Zahlen sagen Ihnen, ob Sie erreichbare Adressen sammeln und ob das Problem im Nutzerverhalten oder in der Infrastruktur liegt.
Ungültigkeitsrate ist der Anteil der Anmeldungen, bei denen die Adresse nicht nutzbar ist. Mindestens sollten Sie offensichtliche Fehler wie falsche Syntax (fehlendes @, unzulässige Zeichen) und nicht existierende Domains zählen. Wenn Sie auch die Mailbox‑Erreichbarkeit messen, seien Sie bei der Interpretation vorsichtig: „Mailbox nicht erreichbar“ kann eine tatsächlich ungültige Mailbox bedeuten, aber auch eine temporäre Blockade, Greylisting oder eine Einschränkung durch den Provider.
Wegwerf‑Rate ist der Anteil der Anmeldungen von bekannten Wegwerf‑Mail‑Providern (One‑Time‑Inbox‑Dienste). Diese Adressen korrelieren oft mit Fake‑Accounts, geringerer Aktivierung, höherem Betrugsrisiko und später schlechterer Zustellbarkeit. Eine Wegwerf‑Adresse kann technisch „gültig“ sein, deshalb sollte diese Metrik für sich stehen.
Die Domain‑ und MX‑Fehlerrate erfasst Probleme, die auftreten, bevor Sie eine Mailbox erreichen: Domain fehlt, DNS kann nicht aufgelöst werden oder es gibt keine MX‑Einträge. Wenn möglich, tracken Sie temporäre DNS‑Fehler separat, denn die steigen oft bei Ausfällen.
Eine praktische Einrichtung nutzt einige stabile Ergebnis‑Buckets. Viele Teams starten mit:
- Valid
- Invalid
- Disposable
- Unknown
Der Unknown‑Bucket ist Ihr Frühwarnsystem. Er fängt Timeouts, Provider‑Sperren und mehrdeutige Resultate auf, die Sie nicht in „valid“ oder „invalid“ pressen sollten. Egal welches Tool Sie nutzen: Konsistenz ist wichtiger als perfekte Kategorisierung. Halten Sie Definitionen stabil und ändern Sie sie nur mit einem datierten Hinweis, damit Trends vergleichbar bleiben.
So berechnen Sie Raten, die nicht lügen
Gute Metriken beginnen mit einer langweiligen Entscheidung: Wählen Sie einen konsistenten Nenner. Für das Signup‑Monitoring verwenden Sie die Gesamtzahl der Anmeldungen als Basis, damit jede Rate beantwortet: „Von allen, die sich anmelden wollten, wie viele hatten dieses Problem?“
Formeln, die Sie wiederverwenden können (pro Tag oder pro Woche):
- Ungültige E‑Mail‑Rate = invalid_results / total_signups
- Wegwerf‑E‑Mail‑Rate = disposable_results / total_signups
- Domain und MX‑Fehlerrate = domain_or_mx_fail_results / total_signups
- Validierungs‑Abdeckungsrate = validated_signups / total_signups
Tracken Sie neben den Raten auch die absoluten Zahlen. Nur Raten können irreführend sein, wenn das Volumen klein ist. Wenn Sie am Sonntag 20 Anmeldungen hatten und 2 waren ungültig, sind das 10 %, aber das kann Rauschen sein. Zahlen zeigen, ob es eine echte Verschiebung ist.
Für Reports nutzen Sie sowohl Tages‑ als auch Wochenansichten. Täglich erkennt plötzliche Veränderungen (z. B. Kampagnenstart). Wöchentlich glättet es Tagesschwankungen. Eine 7‑Tage‑Rollingsicht ist ein guter Mittelweg.
Domain‑ und DNS‑Prüfungen brauchen eine zusätzliche Regel: Retries. Manchmal schlägt ein Domain‑Lookup fehl wegen eines temporären Resolver‑Problems, nicht weil die E‑Mail schlecht ist. Entscheiden Sie, was Sie messen wollen, und benennen Sie es klar:
- First‑attempt‑Failure‑Rate (erkennt Infrastruktur‑ oder DNS‑Zuverlässigkeitsprobleme schnell)
- Final Failure Rate nach Retries (näher an der tatsächlichen Erreichbarkeit des Postfachs)
Speichern Sie schließlich den rohen Validierungs‑Resultcode, nicht nur Pass/Fail. Wenn Sie den Grund behalten (syntax_error, no_mx, disposable_provider, blocked, timeout usw.), können Sie Änderungen später erklären und genau segmentieren.
Schritt für Schritt: Monitoring von der Anmeldung bis zum Dashboard einrichten
Beginnen Sie damit, zu entscheiden, wo die Prüfungen stattfinden. Viele Teams machen eine schnelle Formatprüfung im Anmeldeformular, um Tippfehler abzufangen, und führen die echte Entscheidung auf dem Server aus, damit sie nicht umgangen werden kann.
Protokollieren Sie das Ergebnis für jeden Versuch, auch für blockierte. Blockierte Versuche sagen etwas über Angriffe, fehlerhafte Marketingquellen und UX‑Reibung aus.
Eine einfache Einrichtung, die für die meisten Produkte funktioniert:
- Validieren bei der Anmeldung (und bei E‑Mail‑Änderungen).
- Speichern Sie Timestamp, Nutzer/Session‑ID, Anmeldequelle (Kampagne/Referrer/App) und die rohe E‑Mail‑Domain.
- Speichern Sie das Validierungsergebnis plus einen kurzen Grundcode (syntax, disposable, MX missing, domain not found, blocklisted, timeout).
- Mappen Sie Outcomes in stabile Buckets für die Langzeitaufbewahrung: valid, invalid, disposable, domain‑fail, unknown.
- Aggregieren Sie in einer täglichen Tabelle und zeichnen Sie jede Rate als Trendlinie.
Konsistenz ist der Unterschied zwischen einem Dashboard, dem Sie vertrauen, und einem, das Sie ignorieren. Halten Sie die Kern‑Buckets stabil, auch wenn Ihr Validator später neue Grundcodes hinzufügt. Sie können immer eine sekundäre Aufschlüsselung erstellen, aber Ihre Haupt‑Trendlinien sollten sich nicht jeden Monat ändern.
Für das Dashboard genügt anfangs ein Diagramm pro Rate. Fügen Sie unter jedem Diagramm eine kleine Tabelle mit Tageszahlen hinzu, damit Sie sehen, ob ein Ausschlag echt ist oder nur niedriges Volumen.
Entwickeln Sie eine wöchentliche Routine: Wenn ein Ausschlag erscheint, notieren Sie, was sich geändert hat (neue Kampagne, neues Land, Textänderung im Produkt, neue Traffic‑Quelle, Validierungs‑Config‑Update). Wenn die Wegwerf‑Rate direkt nach dem Start einer Giveaway‑Kampagne ansteigt, kann das erwartet sein. Die eigentliche Entscheidung ist, ob Sie blocken, warnen oder diese Anmeldungen erlauben, aber markieren.
Segmentierung: Finden Sie, wo schlechte E‑Mails tatsächlich herkommen
Wenn Sie nur eine gesamtweite Kennzahl verfolgen, verpassen Sie die Ursache. Schlechte Adressen sind selten gleichmäßig verteilt. Segmentierung macht E‑Mail‑Qualitätsmetriken handlungsfähig.
Starten Sie mit „Woher kam diese Anmeldung?“ und teilen Sie Raten nach einer kleinen Auswahl vertrauenswürdiger Quellen auf. Ein einfacher erster Schritt:
- Akquisitionskanal (Ads, SEO, Partner, Referrals, Sales‑Imports)
- Anmeldungsoberfläche (Warteliste, Trial, Newsletter, Kontaktvertrieb)
- Geografie oder Sprache (nur bei großem Volumen)
- Neue vs. wiederkehrende Nutzer (wenn unterscheidbar)
Halten Sie Gruppen groß genug, damit sie aussagekräftig sind. Ein Land mit 12 Anmeldungen kann über Nacht von 0 % auf 25 % ungültig springen — das ist bedeutungslos. Setzen Sie eine Mindeststichprobengröße (z. B. 100 Anmeldungen), bevor Sie ein Segment als Signal werten.
Ein praktisches Beispiel: Sie sehen wöchentlich einen Spike bei der Wegwerf‑Rate. Die gesamtweite Kurve sieht beängstigend aus, aber durch Segmentierung zeigt sich: Es kommt fast ausschließlich von einer Partnerkampagne, die Traffic auf ein Newsletter‑Formular leitet. Jetzt wissen Sie, was zu tun ist: Dieses Formular besser schützen, die Kampagne anpassen oder für diesen Pfad einen zusätzlichen Schritt verlangen.
Achten Sie auch auf Bots. Sie treffen oft eine Oberfläche besonders stark (meist das einfachste Formular) und erzeugen plötzliche Ausschläge. Hinweise sind: ein starker Anstieg von einem einzigen Referrer, sehr hohe Domain/MX‑Fehlerraten in einem Formular, Anmelde‑Burst zu ungewöhnlichen Zeiten oder Traffic aus Geografien, die nicht zu Ihrer Zielgruppe passen.
E‑Mail‑Qualität mit Aktivierung und anderen Ergebnissen verknüpfen
Kampagnen-Anmeldungen schützen
Filtern Sie bei Promo-Traffic Wegwerf-Provider und segmentieren Sie nach Quelle.
E‑Mail‑Qualität betrifft nicht nur Zustellbarkeit. Sie beeinflusst, was nach der Anmeldung geschieht: ob Leute das Onboarding abschließen, ihre E‑Mail bestätigen und zurückkehren. Wenn ein Anteil der Anmeldungen ungültige oder wegwerfbare Adressen nutzt, können Ihre Produktmetriken schlechter aussehen, obwohl sich das Produkt nicht geändert hat.
Eine praktische Methode ist, die Aktivierungsrate pro Anmelde‑Kohorte (Tag oder Woche) zu verfolgen und Kohorten mit unterschiedlichen E‑Mail‑Qualitätslevels zu vergleichen. Wenn eine Kohorte höhere Ungültig‑ oder Wegwerf‑Raten hat, prüfen Sie, ob die Aktivierung in derselben Kohorte sinkt. Dann ist E‑Mail‑Qualität ein Geschäftssignal, nicht nur Mail‑Ops.
Downstream‑Ergebnisse, die Sie verfolgen sollten:
- Abschlussrate der E‑Mail‑Verifikation
- Erste Anmeldung/Erster Login innerhalb von 24–72 Stunden
- Erste Schlüsselaktion (Ihr „Aha“‑Moment)
- Trial‑zu‑Paid (oder Lead‑zu‑Meeting) Rate
- Support‑Kontakt‑Rate pro 1.000 Anmeldungen
Eine einfache Schätzung der Kosten hilft: zusätzliche Support‑Tickets, mehr Sales‑Nachverfolgung, Mehraufwand für Resends/Verifikation, plus der weiche Kostenfaktor der Rufschädigung durch Bounces. Wenn 2 % mehr Anmeldungen ungültig sind und jede schlechte Anmeldung 3 Minuten Support kostet, können Sie Prozentwerte schnell in Stunden und Euro umrechnen.
Ein Hinweis: Korrelation ist nicht immer Kausalität. Saisonalität, eine neue Traffic‑Quelle oder eine UI‑Änderung können Aktivierung und E‑Mail‑Qualität gleichzeitig verschieben. Wiederkehrende Muster über Kohorten hinweg sind jedoch meist ausreichend, um zu entscheiden, was weiter untersucht werden sollte.
Alarme und Schwellen, die die richtige Reaktion auslösen
Alarme sollten echte Probleme fangen, kein normales Rauschen. Lernen Sie zunächst Ihre Basis aus den letzten 2–4 Wochen: wie „normal“ für Ungültigkeitsrate, Wegwerf‑Rate und Domain/MX‑Fehler aussieht. Dann setzen Sie Schwellen, die zu Ihrem Traffic passen.
Eine praktische Regel ist „2× normal“, aber nur wenn das Volumen groß genug ist. Wenn Wegwerf‑E‑Mails normalerweise bei 1 % liegen, kann ein Alarm bei 2 % nützlich sein, jedoch erst nach mindestens 200 Anmeldungen im betrachteten Fenster.
Nutzen Sie sowohl relative als auch absolute Trigger, damit Metriken nicht in die Irre führen:
- Relativer Spike: Rate ist 2× (oder 1,5×) Ihrer Basis
- Absoluter Grenzwert: Rate liegt über einem festen Wert (z. B. >3 %)
- Mindestvolumen: mindestens N Anmeldungen (wählen Sie N passend zu Ihrem Traffic)
- Mindestdauer: anhaltend für 30–60 Minuten (oder 1 Tag bei geringem Volumen)
Halten Sie separate Alarme für verschiedene Fehlertypen, denn Zuständigkeit und Behebung unterscheiden sich oft. Ein Wegwerf‑Spike deutet häufig auf Abuse, Incentive‑Kampagnen oder Bot‑Wellen hin. Ein Domain/MX‑Fehler‑Spike deutet eher auf Formularfehler, ein schlechtes Autofill‑Muster oder ein temporäres DNS‑Problem.
Wenn ein Alarm ausgelöst wird, schreiben Sie eine kurze Incident‑Notiz:
- Was sich geändert hat (Release, Kampagne, Traffic‑Quelle, Land)
- Welche Metrik sich wie stark bewegt hat
- Welches Segment den Auslöser war (Kanal, Formular, Kohorte)
- Was Sie getan haben (blockiert, UI angepasst, Validierung verschärft)
- Ergebnis nach der Änderung
Klären Sie die Zuständigkeit im Voraus. Marketing‑Ops kümmert sich meist um kampagnengetriebene Ausschläge, Produkt um Formular‑/UX‑Probleme, Engineering um Validierungslogik und Integrationen.
Muster lesen: Was jeder Spike normalerweise bedeutet
Unbekannte Ergebnisse sichtbar machen
Erfassen Sie Timeouts und Sperren mit Grundcodes, die sich im Zeitverlauf auswerten lassen.
Wöchentlich lernen Sie am meisten aus Ausschlägen. Sie zeigen meist eine konkrete Ursache.
Ein Ungültig‑Rate‑Spike kommt oft von Formularmissbrauch (Bots), einfachen Tippfehlern oder einer UI‑Änderung wie einer kaputten Eingabemaske.
Schnelle Aktion: Prüfen Sie kürzliche Formularänderungen und führen Sie einige echte Anmeldungen auf Mobil und Desktop durch.
Tiefere Nacharbeit: Vergleichen Sie Ungültige nach Quelle (Landingpage, Gerät, Land, Kampagne) und prüfen Sie Server‑Logs auf bot‑ähnliche Muster.
Ein Wegwerf‑Rate‑Spike ist typisch nach Incentives (Coupons, Gratis‑Trials) oder beim Zukauf von Traffic. Er kann auch geringe Nutzer‑Intent anzeigen.
Schnelle Aktion: Verschärfen Sie Regeln rund um das Angebot (Einmal‑Codes, Rate‑Limits, stärkere Bot‑Checks).
Tiefere Nacharbeit: Brechen Sie Wegwerf‑Anmeldungen nach Kanal und Creative herunter und entscheiden Sie, ob Sie blocken, warnen oder einen Zusatzschritt verlangen.
Ein Domain/MX‑Fehler‑Spike deutet oft auf DNS‑Auflösungsprobleme, einen temporären Ausfall bei einem großen Provider oder eine Netzwerkänderung auf Ihrer Seite hin.
Schnelle Aktion: Testen Sie eine Stichprobe der fehlerhaften Domains ein paar Minuten später und von einem zweiten Netzwerk.
Tiefere Nacharbeit: Prüfen Sie die Gesundheit Ihrer DNS‑Resolver und Timeouts.
Wachstum im „Unknown“‑Bucket deutet meist auf eine Integration hin, die time‑outs erzeugt, Felder verliert oder neue Muster nicht klassifiziert.
Schnelle Aktion: Vergewissern Sie sich, dass API‑Antworten end‑to‑end geloggt und gespeichert werden.
Tiefere Nacharbeit: Auditieren Sie Timeouts, Retries und wie Sie Reason‑Codes in Buckets mappen.
Eine gute Regel: Wenn ein Spike zu einer Produktänderung passt, schauen Sie zuerst ins Formular. Wenn er zu einer Traffic‑Änderung passt, vermuten Sie Intent und Abuse.
Häufige Fehler, die Metriken wertlos machen
Die meisten Dashboards scheitern an langweiligen Gründen: Die Zahlen wirken präzise, aber die Daten sind schmutzig. Jedes Diagramm sollte eine klare Frage beantworten und Wochen zu Wochen vergleichbar bleiben.
Ein schneller Weg, Raten kaputtzumachen, ist Versuche statt Personen zu zählen. Anmeldeversuche beinhalten oft Retries (Tippfehler, Zurück‑Button, Resubmits, Mobile‑Timeouts). Wenn Sie jeden Versuch zählen, kann Ihre Ungültigkeitsrate steigen, obwohl dieselben Nutzer die Adresse später korrigieren. Entscheiden Sie sich für eine Einheit (eindeutiger Nutzer, eindeutige E‑Mail oder eindeutige Session) und deduplizieren Sie vor der Berechnung der Raten.
Eine weitere Falle ist, Definitionen mittendrin zu ändern. Wenn „disposable“ mehr Provider einschließt oder „invalid“ von Syntax‑Only auf Syntax plus Domain‑Checks wechselt, zeigt Ihre Trendlinie einen falschen Spike. Fixieren Sie Definitionen, versionieren Sie sie und führen Sie ein einfaches Änderungsprotokoll.
Fehler, die Ergebnisse vergiften:
- Versuche und eindeutige Anmeldungen ohne klare Deduplizierung mischen
- Stillschweigende Änderung dessen, was als invalid oder disposable gilt
- Nur Gesamtzahlen beobachten und so den Kanal übersehen, der die schlechten E‑Mails treibt
- Zu aggressiv blocken, um die Valid‑Rate zu verbessern, und dadurch echte Conversions senken
- Temporäre DNS‑Timeouts als permanente Fehler behandeln statt zu retryen oder zu separieren
Beispiel: Eine Kampagne bringt Anmeldungen aus einer Region. DNS‑Lookups sind dort für ein paar Stunden langsamer, also time‑outs bei Domain‑Checks. Wenn Sie das als harte Fehler labeln, steigt Ihre Domain‑Fehlerrate und Sie könnten gute Nutzer blockieren. Wenn Sie Timeouts separat tracken und retryen, wird der Spike zu einem Performance‑Problem, nicht zu einer E‑Mail‑Qualitäts‑Krise.
Beispiel: Diagnose eines Qualitätseinbruchs in einer Woche
Ein SaaS‑Team bemerkt am Montag Folgendes: Trials steigen nach einer Promo‑Kampagne um 30 %, aber die Wegwerf‑Rate schießt von 4 % auf 18 %. Zwei Tage später steigt das Support‑Volumen, weil Leute behaupten, die Willkommensmail nie erhalten zu haben, und der Vertrieb meldet Leads mit geringer Intent.
Zuerst bestätigen Sie, dass es echt ist und kein Tracking‑Fehler. Vergleichen Sie die Woche mit dem Vier‑Wochen‑Durchschnitt, mit derselben Definition und demselben Nenner. Wenn Metriken pro Anmeldeversuch berechnet werden, können sich Änderungen im Retry‑Verhalten verstecken oder übertreiben. Entscheiden Sie, ob Sie pro Versuch, pro akzeptierter Anmeldung oder pro eindeutigem Nutzer überwachen — und bleiben Sie dabei.
Dann segmentieren Sie, um den Treiber zu finden. Ergebnis: Der Spike kommt fast ausschließlich von PromoA (ein Coupon, gepostet in einem Deal‑Forum). Organischer Traffic und Partner‑Referrals sind unverändert. Domain/MX‑Fehler bleiben stabil, also scheint kein DNS‑Ausfall oder Formularfehler vorzuliegen. Es sind überwiegend Wegwerf‑Provider.
Ein einfacher Root‑Cause‑Check:
- Wegwerf‑Rate nach Kampagne vergleichen, nicht nur gesamt
- Aktivierungsrate der neuen Kohorte vs. der Vorwoche prüfen
- Eine kleine Stichprobe von Adressen prüfen (ohne unnötig mehr Daten zu speichern)
- Sicherstellen, dass das System Domains konsistent klassifiziert
- Ziel festlegen: mehr Trials, mehr Aktivierungen oder beides
Die Entscheidung: gestufte Reaktion. Die häufigsten Wegwerf‑Domains blocken und zusätzlich für PromoA‑Traffic eine E‑Mail‑Verifikation einführen. Das Incentive bleibt, aber Abuse wird erschwert.
Innerhalb einer Woche sinkt die Wegwerf‑Rate für PromoA auf 6 %, die Aktivierung steigt von 9 % auf 14 % und die Support‑Last normalisiert sich. Das Team dokumentiert kurz die Metriken, Daten und die genaue Änderung, so dass beim nächsten Alarm schnell entschieden werden kann.
Schnell‑Checklist für ein gesundes E‑Mail‑Qualitäts‑Dashboard
Absprungraten frühzeitig reduzieren
Prüfen Sie Syntax, Domain und MX-Einträge, bevor Sie eine einzige E-Mail versenden.
Ein gutes Dashboard ist die meisten Tage langweilig. Wenn sich etwas ändert, wissen Sie schnell, was sich geändert hat und wo es begann.
Bilden Sie eine Basis aus den letzten 4–8 Wochen. Das ist lang genug, um Rauschen zu glätten, aber kurz genug, um aktuellen Traffic und Ihren Signup‑Flow abzubilden.
Sanity‑Check Ihrer Einrichtung:
- Sie tracken invalid, disposable, domain/MX‑Fehler und unknown als separate Outcomes (nicht eine zusammengefasste Fehler‑Rate).
- Jedes Diagramm lässt sich nach Akquisitionsquelle und genauem Einstiegspunkt (Web, Mobile, Checkout, Warteliste) aufschlüsseln.
- Sie prüfen Aktivierung (oder erste Schlüsselaktion) pro Anmelde‑Kohorte neben E‑Mail‑Qualitätsraten.
- Alarme erfordern sowohl eine Ratenänderung als auch ein Mindestvolumen.
- Sie können von einem Spike zu einer kleinen Stichprobe des Segments springen, um Muster schnell zu erkennen.
Weisen Sie einen Owner und ein Playbook zu. Wenn die Wegwerf‑Rate steigt, wer prüft Kampagnen? Wenn Domain‑Fehler steigen, wer klärt Ausfall vs. Formularfehler?
Nächste Schritte: Qualität verbessern, ohne Anmeldungen zu schädigen
Beginnen Sie mit einer Änderung, die Sie durchhalten können. Wenn Sie Logging, Segmentierung und Alarme gleichzeitig hinzufügen, wissen Sie später nicht, was geholfen hat.
Wählen Sie die erste Verbesserung nach Ihrem größten Schmerz:
- Wenn Sie über die Zahlen streiten, verbessern Sie zuerst das Logging.
- Wenn Sie nicht wissen, wo Probleme herkommen, fügen Sie Segmentierung hinzu.
- Wenn Sie Probleme zu spät entdecken, fügen Sie Alarme hinzu.
Definieren Sie dann eine Policy für „schlechte“ und „vielleicht schlechte“ E‑Mails. Ungültige und harte Domain‑/MX‑Fehler sind meist sicher zu blocken, weil sie selten echte Nutzer werden. Wegwerf‑Adressen und temporäre Fehler sind komplizierter, weil manche echten Nutzer sie nutzen.
Eine einfache, gut funktionierende Policy: blocken Sie offensichtliche Ungültige, warnen Sie bei Wegwerf‑Adressen und retryen oder fragen Sie bei temporären Fehlern nach Bestätigung. Was auch immer Sie wählen — dokumentieren Sie es, damit Support und Produkt konsistent reagieren.
Führen Sie dann ein kleines Experiment durch. Ändern Sie ein Gate für ein Segment für kurze Zeit und beobachten Sie Qualität und Ergebnis. Beispiel: Zeigen Sie eine Warnung für Wegwerf‑E‑Mails bei mobilen Anmeldungen eine Woche lang und vergleichen Sie die Aktivierung der Kohorte mit der Vorwoche. Bleibt die Aktivierung stabil und sinkt die Wegwerf‑Rate, behalten Sie es bei. Fällt die Aktivierung, rollen Sie zurück.
Wenn Sie eine konsistente Klassifikation bei der Anmeldung wollen, kann eine E‑Mail‑Validierungs‑API helfen, invalid, disposable und domain/MX‑Outcomes einheitlich über Formulare und Services hinweg zu labeln. Zum Beispiel bietet Verimail (verimail.co) eine Single‑Call‑Validierungs‑API mit Checks wie Syntax, Domain-/MX‑Verifikation und Matching gegen Wegwerf‑Provider.
Planen Sie eine monatliche Review, die mit einer Entscheidung endet. Eine Seite reicht: Top‑Metriken, größte Änderung, was Sie versucht haben, was Sie nächsten Monat ändern und was Sie nicht ändern werden.
FAQ
Was bedeutet „E-Mail-Qualität“ bei Anmeldungen?
E-Mail‑Qualität bedeutet, dass die Adresse wahrscheinlich erreichbar ist und ein geringes Risiko für Ihr Produkt darstellt. Eine „gute“ E‑Mail kann E‑Mails empfangen, stammt nicht von einem Wegwerf‑Provider und entspricht nicht Mustern, die oft zu Bounces oder Beschwerden führen.
Welche 3 E-Mail-Qualitätsmetriken sollte ich zuerst verfolgen?
Beginnen Sie mit drei Kennzahlen: Ungültigkeitsrate, Wegwerf‑Rate und Domain/MX‑Fehlerrate. Zusammen zeigen sie, ob Nutzer Tippfehler machen, ob Sie viele Anmeldungen mit geringer Absicht anziehen und ob Infrastruktur‑ oder DNS‑Probleme die Zustellung verhindern.
Was sollte ich als Nenner bei der Berechnung der Raten verwenden?
Verwenden Sie standardmäßig die Gesamtzahl der Anmeldeversuche als Nenner, damit jede Rate beantwortet: „Von allen, die sich angemeldet haben, wie viele hatten dieses Problem?“ Halten Sie diesen Nenner über die Wochen konsistent, damit Trends vergleichbar bleiben.
Warum brauche ich einen „Unbekannt“-Bucket?
„Unbekannt“ ist der Platz für Timeouts, Provider‑Sperren und mehrdeutige Prüfungen. Das ist nützlich, weil es Integrationsprobleme und temporäre Zustände hervorhebt, die Sie nicht einfach als gültig oder ungültig einstufen sollten.
Sollte ich Domain/MX-Prüfungen wiederholen oder Fehler sofort zählen?
DNS‑ und Netzwerkabfragen können temporär fehlschlagen, obwohl die E‑Mail in Ordnung ist. Eine gängige Vorgehensweise ist, First‑Attempt‑Fehler zu tracken (um Ausfälle schnell zu erkennen) und finale Fehler nach Retries (um die tatsächliche Erreichbarkeit abzuschätzen).
Wie finde ich heraus, woher schlechte E-Mails tatsächlich kommen?
Wenn Sie nur eine gesamtweite Zahl betrachten, übersehen Sie die Ursache. Segmentieren Sie zuerst nach Akquisitionskanal und Anmeldungsfläche, und fügen Sie Geografie oder Gerät nur hinzu, wenn die Stichprobe groß genug ist, um vertrauenswürdige Ergebnisse zu liefern.
Wie verbinde ich E‑Mail‑Qualität mit Aktivierung und anderen Ergebnissen?
Verfolgen Sie Aktivierung oder Verifikationsabschluss pro Anmelde‑Kohorte und vergleichen Sie Kohorten mit unterschiedlicher E‑Mail‑Qualität. Aktivieren Kohorten mit höheren Wegwerf‑ oder Ungültig‑Raten konsequent weniger, dann wirkt sich E‑Mail‑Qualität auf Produktmetriken aus, nicht nur auf Zustellung.
Welche Schwellenwerte sollte ich für Alarme verwenden, ohne zugespamt zu werden?
Legen Sie Alerts auf Basis eines Baselines der letzten Wochen fest und verlangen Sie ausreichend Volumen, um Rauschen zu vermeiden. Ein praktischer Alert feuert, wenn eine Rate deutlich über dem Normalwert liegt und lange genug anhält, um einen kurzzeitigen Ausreißer auszuschließen.
Was sind die häufigsten Fehler, die diese Metriken irreführend machen?
Das häufigste Problem ist, Versuche zu zählen statt eindeutige Anmeldungen oder Sessions — dadurch steigt die Ungültigkeitsrate, wenn Nutzer mehrere Versuche brauchen. Ein weiterer Fehler ist, Definitionen über die Zeit zu ändern; halten Sie Buckets stabil und dokumentieren Sie Änderungen mit Datum.
Sollte ich Wegwerf‑E‑Mails blockieren oder Nutzer nur warnen?
Blockieren Sie offensichtliche Ungültigkeiten und harte Domain/MX‑Fehler standardmäßig, weil sie selten zu echten Nutzern werden. Mit Wegwerf‑Adressen und temporären Fehlern sollten Sie vorsichtiger umgehen: Warnungen, zusätzliche Verifikation oder mehr Reibung nur für risikoreiche Segmente, damit legitime Konversionen nicht leiden.