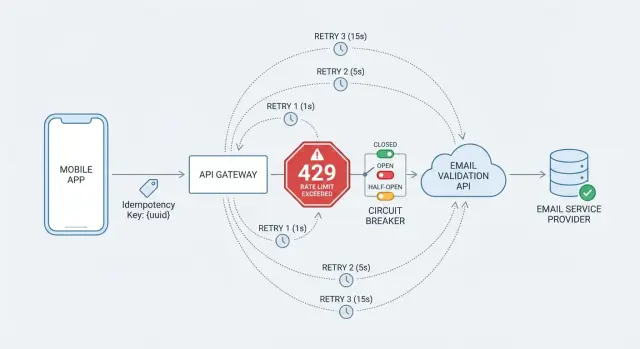
Wie Rate Limiting in echten Anwendungen aussieht
Rate Limiting ist einfach: eine API begrenzt, wie viele Anfragen Sie innerhalb eines kurzen Fensters senden dürfen. Anbieter tun dies, um Dienste stabil zu halten, Missbrauch zu verhindern und zu verhindern, dass ein lauter Client die gemeinsame Kapazität aufzehrt.
Die meisten Teams bemerken Limits erst bei Spitzen: Eine Kampagne geht raus, ein Partner startet, oder ein Bot trifft Ihr Anmeldeformular. Wenn Sie E-Mails während der Anmeldung validieren (zum Beispiel durch Aufruf von Verimail, um Disposable- oder ungültige Adressen zu blockieren), können diese Spitzen Sie über die Schwelle treiben.
Für Nutzer fühlt sich das meist wie eine instabile App an, nicht wie „Rate limited“. Sie sehen langsamere Anmeldungen, zufällige „bitte erneut versuchen“-Fehler, die beim Aktualisieren verschwinden, Bestätigungs-E-Mails, die nicht ankommen weil die Adresse nie akzeptiert wurde, und Support-Tickets, die inkonsistent klingen.
Die Falle ist, was als Nächstes passiert. Ein naiver Client sieht einen Fehler und probiert sofort erneut, manchmal mit mehreren parallelen Versuchen. Unter Rate Limiting verschlimmert das die Situation. Sie erhöhen den Traffic genau in dem Moment, in dem die API Sie bittet, langsamer zu werden, und ein kurzer Aussetzer kann in Minuten von Störung ausarten.
Ein resilienter Client geht davon aus, dass solche Momente vorkommen und reagiert gelassen: er drosselt absichtlich, wiederholt nur wenn es sinnvoll ist (und nur ein paar Mal), vermeidet doppelte Arbeit, wenn dieselbe Nutzeraktion erneut erfolgt, und verhindert, dass eine schwächelnde Abhängigkeit in einen vollumfänglichen Seitenausfall ausartet.
Rate Limits sind normal. Der Unterschied zwischen einer reibungslosen Anmeldung und einem Vorfall ist meist, wie Ihr Client sich nach dem ersten 429 verhält.
Die Signale lesen: 429, Retry-After und Timeouts
Wenn Sie ein Limit erreichen, gibt Ihnen der Server ein Steuerungssignal: Sie senden Anfragen schneller, als er gerade akzeptieren möchte. Behandeln Sie das als normales Feedback, nicht als generischen Fehler.
Die Signale, die Sie am häufigsten sehen, sind:
- HTTP 429 (Too Many Requests)
- Request-Timeouts
- Netzwerkfehler wie Verbindungsabbrüche
Sie können im Dashboard ähnlich aussehen, benötigen aber unterschiedliche Handhabung.
Eine 429-Antwort ist der sauberste Fall, weil sie explizit ist. Wenn die API einen Retry-After-Header enthält, behandeln Sie ihn als die beste verfügbare Anweisung, wann Sie es erneut versuchen sollten. Einige APIs geben auch Quota-Hinweise wie verbleibende Anfragen oder Reset-Zeit an, aber verwenden Sie diese nur, wenn sie dokumentiert sind.
Eine Entscheidungsregel, die Sie schützt:
- 429 mit
Retry-After: warten Sie so lange (plus ein kleines zufälliges Jitter), und versuchen Sie es dann erneut.
- 429 ohne
Retry-After: wiederholen Sie mit exponentiellem Backoff und Jitter, mit einer strikten Obergrenze für die Gesamtwartezeit.
- Wiederholte 429s: stoppen Sie weitere Versuche und schlagen Sie für kurze Zeit schnell fehl (ein Circuit Breaker hilft hier).
Timeouts und Verbindungsfehler
Timeouts und Verbindungsfehler bedeuten meist Überlastung, instabile Netzwerke oder eine Client-seitige Fehlkonfiguration. Im Gegensatz zu 429 gibt es möglicherweise keine „richtige“ Wartezeit. Wiederholungen können helfen, aber nur mit strikten Limits.
Protokollieren Sie Rate-Limit-Ereignisse getrennt von anderen Fehlern. Ein 429 ist nicht dasselbe wie „ungültige E-Mail“ oder „API ist down“. Wenn Sie sie mischen, werden Sie Retries schlecht einstellen und Zeit mit der Suche nach der falschen Ursache verschwenden.
In einem Anmeldeflow, der eine API wie Verimail aufruft, planen Sie einen sanften Fallback. Wenn die Validierung vorübergehend blockiert ist, könnten Sie sie später in eine Warteschlange stellen, eine klare Nachricht anzeigen oder die E-Mail akzeptieren und später verifizieren. Die richtige Wahl hängt davon ab, ob Validierung ein striktes Tor oder eine Qualitätsprüfung ist.
Ziele setzen, bevor Sie Retries hinzufügen
Retries klingen harmlos: Wenn eine Anfrage fehlschlägt, versuch es nochmal. In der Praxis beeinflussen Retries die Anmeldegeschwindigkeit, die Datenqualität und wie viel Druck Sie auf den Provider ausüben.
Entscheiden Sie, was „Erfolg“ für Ihr Formular bedeutet. Während der Anmeldung bevorzugen die meisten Teams eine schnelle, vorhersehbare Erfahrung gegenüber perfekter Sicherheit. Wenn die Validierung langsam oder rate-limited ist, könnten Sie die E-Mail annehmen und später prüfen, anstatt den Nutzer zu blockieren.
Schreiben Sie vor Änderungen am Code ein paar Regeln auf:
- User Experience: Wie viel Zeit darf die Validierung hinzufügen (z. B. 200–500 ms), und was passiert, wenn dieses Budget aufgebraucht ist?
- Sicherheit: Welche Aktionen dürfen niemals doppelt ausgeführt werden (Kontoerstellung, Willkommens-E-Mails, Start von Testphasen)?
- Last: Wie viele Retry-Versuche sind erlaubt, und wieviel Gesamtzeit darf fürs Wiederholen aufgewendet werden?
- Supportbarkeit: Was sieht der Support in den Logs, und kann er es einem Kunden erklären?
- Fallback: Was ist die sichere Standardaktion unter Last (blockieren, erlauben oder in die Warteschlange stellen)?
Diese Ziele verhindern, dass Sie ewig weiter versuchen, was oft einen kurzen Spike in eine längere Störung verwandelt.
Beispiel: Ihr Anmeldeformular ruft Verimail auf, um Disposable-E-Mails zu prüfen. Wenn die API langsamer wird, könnte Ihre Regel lauten: „Verzögere die Anmeldung niemals länger als 1 Sekunde.“ Das weist auf ein kurzes Timeout, ein oder zwei Retries höchstens und dann einen Fallback hin (z. B. E-Mail akzeptieren, aber zur späteren Prüfung markieren).
Schritt für Schritt: Backoff und Jitter implementieren
Retries helfen nur, wenn sie kontrolliert sind. Wenn Sie zu schnell oder zu lange wiederholen, können Sie eine kleine Verlangsamung in ein größeres Problem verwandeln.
1) Setzen Sie zuerst ein kleines Budget
Wählen Sie zwei Limits: eine maximale Retry-Anzahl und ein Gesamtzeitbudget. Das Zeitbudget ist wichtiger, weil Backoff schnell wächst.
Für eine interaktive Signup-Prüfung ist ein praktischer Ausgangspunkt 2–3 Retries innerhalb von 1–2 Sekunden Gesamtzeit. Für Hintergrund-Aufräumjobs können Sie mehr Zeit zulassen, weil der Nutzer nicht wartet.
2) Verwenden Sie exponentiellen Backoff und fügen Sie Jitter hinzu
Exponentieller Backoff bedeutet, dass Sie nach jedem Fehler länger warten. Jitter randomisiert diese Wartezeit, damit nicht Tausende Clients gleichzeitig erneut anfragen.
Ein einfaches Muster:
- Führen Sie die Anfrage aus.
- Falls sie mit einem retryfähigen Fehler fehlschlägt (z. B. 429 oder ein transientes Timeout), berechnen Sie die nächste Verzögerung.
- Delay = min(maxDelay, baseDelay * 2^attempt) + random(0, jitterRange).
- Schlafen Sie, und versuchen Sie es erneut, bis Sie Ihr Zeitbudget erreicht haben.
Wenn der Server Retry-After sendet, behandeln Sie ihn als Mindestwartezeit. Wenn Ihr Backoff 400 ms sagt, aber Retry-After 2 Sekunden angibt, warten Sie 2 Sekunden.
Wenn Verimail bei einem plötzlichen Anmelde-Spike 429 zurückgibt, hilft das Beachten von Retry-After plus Jitter, den Traffic zu glätten, anstatt die API zuzuprügeln.
3) Einstellungen nach Arbeitslast anpassen
Verwenden Sie nicht eine Retry-Policy für alles. Anmelde-Traffic und Hintergrund-Jobs haben unterschiedliche Ziele.
Halten Sie es einfach:
- Interaktiv (Signup): wenige Retries, enges Zeitbudget, schneller Fallback.
- Hintergrundjobs: mehr Retries, längeres Zeitbudget.
- Batch-Imports: gleichmäßiges Tempo, um Bursts zu vermeiden.
Das Ziel ist, die Nutzererfahrung flink zu halten und gleichzeitig bei Last höflich zu bleiben.
Idempotenz und Deduplizierung, damit Retries keine Duplikate erzeugen
Retries sind am sichersten, wenn der Aufruf nur lesend ist. E-Mail-Validierung ist meist so: Sie stellen eine Frage und bekommen eine Antwort. Selbst dann schaden doppelte Aufrufe: Sie verbrauchen Quoten, erhöhen Latenz und machen Logs schwerer lesbar, wenn eine Nutzeraktion mehrere Validierungen auslöst.
Wenn Ihr Anbieter Idempotency-Keys unterstützt, nutzen Sie sie für Endpunkte, die Seiteneffekte haben könnten (z. B. „validieren und speichern“-Workflows). Ein Idempotency-Key kann eine UUID pro Nutzeraktion oder ein stabiler Fingerabdruck wie ein Hash der normalisierten E-Mail plus Zeitfenster sein. Wenn Keys nicht unterstützt werden, können Sie den Großteil des Nutzens clientseitig nachbilden.
Ein praktischer Ansatz kombiniert drei Ebenen:
- Normalisieren und fingerprinten Sie die E-Mail (trimmen, kleinschreiben, offensichtliche Leerzeichen entfernen), sodass dieselbe Eingabe auf denselben Key abgebildet wird.
- Halten Sie einen kurzlebigen Cache (oft 1–10 Minuten), damit wiederholte Prüfungen die API nicht erneut aufrufen.
- Deduplizieren Sie in-flight Requests: Wenn mehrere Teile Ihrer App dieselbe E-Mail gleichzeitig validieren, sollten sie dasselbe Promise abwarten, nicht mehrere Netzaufrufe auslösen.
Seien Sie vorsichtig, was Sie cachen. „Valid“- und „invalid“-Ergebnisse sind meist sicher kurzzeitig wiederzuverwenden. Temporäre Fehler hingegen nicht. Bei Timeout, 429 oder einer „unknown“-Antwort cachen Sie nur für Sekunden (oder gar nicht), damit Sie kein schlechtes Ergebnis dauerhaft festschreiben.
Beispiel: Während eines Spikes klickt ein Nutzer doppelt auf „Account erstellen“ und das Frontend feuert zusätzlich eine Hintergrundprüfung. Mit Fingerprinting und In-Flight-Dedupe machen Sie trotzdem nur einen Aufruf an Verimail, und Retries vervielfachen den Traffic nicht.
Wissen, wann Sie retryen und wann Sie aufgeben
Retries helfen, wenn das Problem temporär ist. Sie schaden, wenn die Anfrage niemals erfolgreich sein wird.
Wiederholen Sie nur, wenn ein frischer Versuch Erfolg haben könnte. Das umfasst typischerweise 429-Antworten, Netzwerk-Timeouts, Verbindungsabbrüche und viele kurzlebige 5xx-Fehler. Wenn Sie einen 429 erhalten, respektieren Sie Retry-After, wenn vorhanden.
Retryen Sie keine fehlerhaften Anfragen. Wenn die API sagt, Ihre Nutzlast ist ungültig, Parameter fehlen oder Auth falsch ist, wiederholen Sie nur dieselben Fehler.
Ein einfacher Entscheidungsfilter:
- Retry: 429, Timeouts, Verbindungsabbrüche, 5xx (außer in Fällen, die Sie als permanent kennen)
- Schnell fehlschlagen: Input-Validation-4xx, 401/403 Auth-Fehler, fehlende Pflichtfelder
- Stoppen Sie Retries, wenn Ihr Gesamtwartebudget erreicht ist (z. B. 2–3 Sekunden für Signup)
Manchmal ist das beste Ergebnis „ohne validierte Antwort weitermachen“. Während eines Spikes lassen Sie ggf. die Anmeldung zu, speichern ein Flag wie email_status = needs_review und planen eine Hintergrundnachprüfung.
Seien Sie explizit bei partiellen Fehlern. Wenn die Validierung übersprungen wurde, speichern Sie, was passiert ist (Fehlercode, Zeitstempel, Retry-Anzahl) und behandeln die E-Mail später nicht als „verifiziert".
Einen Circuit Breaker hinzufügen, um kaskadierende Fehler zu verhindern
Retries helfen, wenn ein Ausfall kurz ist. Wenn die Validierungs-API für Minuten langsam oder fehlerhaft ist, häufen sich Retries und können Ihren gesamten Anmeldeflow ausbremsen. Ein Circuit Breaker stoppt Aufrufe an die API, wenn Fehler zunehmen, sodass Ihre App reaktionsfähig bleibt.
Ein Breaker hat drei Zustände:
- Closed: Aufrufe gehen normal durch.
- Open: Sie stoppen Aufrufe an die API für eine Abkühlungszeit, weil die letzten Aufrufe zu oft fehlgeschlagen sind.
- Half-open: Sie erlauben einige Testaufrufe. Wenn sie gelingen, schließen Sie den Breaker. Wenn sie fehlschlagen, öffnen Sie ihn wieder.
Start-Thresholds, die für viele Teams funktionieren:
- Öffnen nach 5–10 aufeinanderfolgenden Fehlern oder einer Fehlerquote von 50 % über die letzten 20–50 Aufrufe
- Abkühlungszeit 15–60 Sekunden
- Im Half-Open erlauben Sie 1–5 Testaufrufe, bevor Sie entscheiden
Wenn der Breaker offen ist, legen Sie fest, was Ihre App macht. Bei Signup könnten Sie die E-Mail akzeptieren, aber als „needs verification“ markieren und später validieren. In risikoreicheren Flows zeigen Sie vielleicht eine deutliche Meldung, dass die E-Mail-Prüfung vorübergehend nicht verfügbar ist.
Rate Limiting und Circuit Breaker lösen unterschiedliche Probleme. Rate Limiting ist die API, die Ihnen sagt, langsamer zu werden (oft mit 429 und Retry-After). Ein Circuit Breaker ist Ihre Client-Entscheidung, Aufrufe zu pausieren, weil die jüngsten Ergebnisse Probleme zeigen, auch wenn Sie nicht rate-limited werden.
Monitoring und Tuning, das wirklich hilft
Retries und Breaker funktionieren nur, wenn Sie sehen, was sie tun.
Verfolgen Sie eine kleine Metrikauswahl, die die Geschichte über die Zeit erklärt:
- Retry-Anzahl pro Anfrage (und % der Anfragen, die wiederholen)
- Gesamte hinzugefügte Backoff-Zeit pro Anfrage
- 429-Rate (und wie oft
Retry-After vorhanden ist)
- Erfolgsrate (2xx) und Hard-Fail-Rate (nicht-wiederholte 4xx)
- End-to-End-Latenz (p50/p95) für Validierung, inklusive Retries
Logging ist genauso wichtig wie Dashboards. Pro Validierungsversuch loggen Sie eine Request-ID und das endgültige Ergebnis. Wenn die API ihre eigene Request-ID zurückgibt, speichern Sie diese ebenfalls. Halten Sie Logs datenschutzkonform: Hashen Sie die E-Mail, und Sie können trotzdem Duplikate debuggen.
Alarme sollten sich auf anhaltende Veränderungen konzentrieren, nicht auf normales Rauschen. Eine Handvoll 429s während einer geschäftigen Stunde kann okay sein. Ein Spike, der 10 Minuten anhält, deutet meist auf veränderte Traffic-Muster, zu aggressive Retries oder einen dauerhaft geöffneten Breaker hin.
Testen Sie auch unter Last. Simulieren Sie burstige Anmeldungen und langsame Netzwerke, nicht nur Happy-Path-Aufrufe. Selbst wenn Ihr Provider normalerweise in Millisekunden antwortet, sollten Timeouts und Retry-Limits davon ausgehen, dass das Internet unzuverlässig sein kann.
Wenn möglich, machen Sie wichtige Stellschrauben ohne Redeploy verstellbar: maxRetries, baseBackoff, Timeout und Breaker-Thresholds. So können Sie während Spikes schneller beruhigen.
Beispiel: Traffic-Spike während der Anmeldung
Eine bezahlte Kampagne trifft ein und der Signup-Traffic steigt in einer Stunde um das Zehnfache. Ihre App validiert jede E-Mail beim Eingang und ruft Verimail im Anmeldeflow auf. Zuerst sieht alles gut aus, dann treten Randfälle auf: mehr parallele Anfragen, gelegentliche Timeouts und einige 429-Antworten.
Ohne Schutz probieren viele Clients sofort erneut. Wenn Hunderte Anfragen gleichzeitig fehlschlagen, versuchen sie es zusammen wieder. Das erzeugt ein Thundering-Herd-Problem und lässt die nächste Welle ebenfalls fehlschlagen, obwohl die API sich mit etwas Atemraum erholt hätte.
Mit Backoff und Jitter verteilen sich die Retries. Selbst ein einfaches Vorgehen hilft:
- Erster Retry nach ~200–400 ms (randomisiert)
- Zweiter Retry nach ~800–1200 ms
- Stop nach 2–3 Retries für Signup-Traffic
Idempotenz und Caching reduzieren das Aufrufvolumen weiter. Während Spikes wird dieselbe Adresse oft zweimal übermittelt (Doppelklicks, erneute Einsendungen, Nutzer auf mehreren Geräten). Ein kurzes Cache-Fenster (z. B. 10–30 Minuten), das nach normalisierter E-Mail gekeyt ist, lässt Sie Wiederholungen ohne API-Aufruf beantworten. Kombinieren Sie das mit einem Idempotency-Key für die Signup-Aktion, damit ein Retry keine doppelten Nutzerkonten erstellt.
Ein Circuit Breaker hält Ihre Seite reaktionsfähig, wenn Fehler sich häufen. Wenn 429s und Timeouts einen Schwellenwert überschreiten, öffnen Sie den Breaker kurz und überspringen Validierungsaufrufe. Die Anmeldung kann trotzdem durchlaufen, indem Sie die E-Mail als „pending verification“ markieren und die Validierung im Hintergrund nachholen, sobald der Breaker schließt.
Schnelle Checkliste vor dem Produktivstart
Bevor Sie Retries in Produktion aktivieren, definieren Sie, wie sich „gutes Verhalten" unter Last anhört. Ziel ist, Anmeldungen in Bewegung zu halten und zu vermeiden, dass ein kurzer Stillstand in eine größere Störung ausartet.
- Beachten Sie
Retry-After und begrenzen Sie die Retry-Zeit. Folgen Sie Retry-After, wenn vorhanden, und setzen Sie eine harte Obergrenze für die Gesamt-Retry-Zeit, damit eine Anfrage Ihr System nicht blockiert.
- Wiederholen Sie keine selbstverursachten Fehler. Wenn die API eine klare 4xx-Antwort für falsche Eingaben gibt, sparen Sie sich Retries. Beheben Sie den Eingabepfad und geben Sie eine hilfreiche Meldung zurück.
- Deduplizieren Sie wiederholte Lookups. Fügen Sie ein kurzes Cache-Fenster hinzu, damit Wiederholungen das erste Ergebnis wiederverwenden.
- Setzen Sie Breaker-Regeln und einen Fallback. Wählen Sie Schwellenwerte und entscheiden Sie, was passiert, wenn der Breaker öffnet (akzeptieren und kennzeichnen, in die Warteschlange stellen oder riskante Flows blockieren).
- Machen Sie Fehler leicht debugbar. Loggen Sie Ergebnis (Erfolg, 429, Timeout), Retry-Anzahl, Gesamtwartezeit und ob der Breaker offen war.
Simulieren Sie einen kleinen Traffic-Spike in Staging und bestätigen Sie, dass der Service reaktionsfähig bleibt, während der Client höflich zurückfährt. Wenn Sie Verimail oder einen ähnlichen Anbieter nutzen, gilt dasselbe Muster: Respektieren Sie Signale, begrenzen Sie Retries und machen Sie den „Aufgeben“-Pfad vorhersehbar.
Nächste Schritte: Resilienz zur Standardpraxis machen
Behandeln Sie Retry- und Rate-Limit-Handling als Produktfunktion, nicht als schnellen Patch. Starten Sie konservativ, beobachten Sie das Verhalten in Produktion und passen Sie anhand von Metriken an. Teams geraten meistens in Schwierigkeiten, wenn Retries zu aggressiv sind und eine Verlangsamung verstärken.
Ein praktischer Plan:
- Halten Sie Retries niedrig (oft 2–3) mit exponentiellem Backoff und Jitter, und beachten Sie
Retry-After.
- Fügen Sie Dedupe für jeden Flow hinzu, der Duplikate erzeugen könnte.
- Definieren Sie Stoppregeln: was wird wiederholt, was schlägt schnell fehl, und wann fällt man auf „später erneut versuchen" zurück.
- Schreiben Sie das Verhalten in einfacher Sprache für Produkt und Support (was Nutzer sehen, was geloggt wird und wann Validierung aufgeschoben wird).
- Fügen Sie Dashboards und Alarme für anhaltende 429s, steigende Timeouts und Breaker-Open-Zeiten hinzu.
Wenn E-Mail-Prüfungen geschäftskritisch sind, hilft es außerdem, einen Validator zu verwenden, der für geringe Latenz und hohes Volumen ausgelegt ist. Verimail (verimail.co) führt RFC-konforme Syntaxprüfungen, Domain- und MX-Überprüfungen sowie Echtzeit-Prüfung auf Disposable-/Blocklisten in einem einzigen API-Aufruf aus, was reduziert, wie oft Ihr Client im „Retry“-Pfad landet.
Planen Sie regelmäßige Reviews, wenn sich Traffic-Muster ändern. Überprüfen Sie Schwellenwerte neu, aktualisieren Sie den Umgang mit Disposable-Domains und vergewissern Sie sich, dass Ihr Rate-Limit-Verhalten noch zu echtem Nutzerverhalten und Support-Bedarf passt.