Como a limitação de taxa se manifesta em aplicações reais
A limitação de taxa é simples: uma API limita quantos pedidos pode receber dentro de uma janela curta. Os provedores fazem isto para manter o serviço estável, prevenir abuso e evitar que um cliente barulhento consuma toda a capacidade partilhada.
A maioria das equipas só nota os limites durante picos: uma campanha é lançada, um parceiro ativa algo, ou um bot começa a carregar no formulário de registo. Se validar emails durante o registo (por exemplo, chamando Verimail para bloquear endereços descartáveis ou inválidos), esses picos podem levar‑lo além do limite.
Para os utilizadores, isto costuma parecer que a aplicação está instável, não “limitada por taxa”. Verá coisas como registos mais lentos, erros aleatórios de “tente novamente” que desaparecem ao atualizar, emails de verificação que não chegam porque o endereço nunca foi aceite, e tickets de suporte com descrições inconsistentes.
A armadilha é o que vem depois. Um cliente ingênuo vê uma falha e tenta de novo imediatamente, por vezes com múltiplos retries em paralelo. Sob limitação de taxa, isso piora o problema. Acrescenta tráfego precisamente quando a API lhe está a pedir para abrandar, e um pequeno percalço pode transformar‑se em minutos de interrupção.
Um cliente resiliente assume que estes momentos acontecerão e reage com calma: abrandando intencionalmente, reintentando apenas quando faz sentido (e só algumas vezes), evitando trabalho duplicado quando a mesma ação do utilizador é repetida, e impedindo que uma dependência em dificuldades provoque uma falha em cascata em todo o site.
Os limites de taxa são normais. A diferença entre um registo suave e um incidente é maioritariamente como o seu cliente se comporta após o primeiro 429.
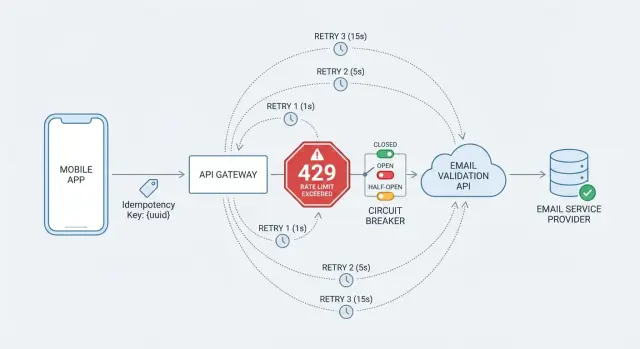
Leia os sinais: 429, Retry-After e timeouts
Quando atinge um limite, o servidor está a dar‑lhe um sinal de controlo: está a enviar pedidos mais rápido do que ele quer aceitar agora. Trate isso como feedback normal, não como uma falha genérica.
Os sinais que verá mais frequentemente são:
- HTTP 429 (Too Many Requests)
- Timeouts de pedido
- Erros de rede como resets de ligação
Podem parecer semelhantes nos dashboards, mas exigem tratamentos diferentes.
429 e cabeçalhos úteis
Uma resposta 429 é o caso mais limpo porque é explícita. Se a API incluir o cabeçalho Retry-After, trate‑o como a melhor instrução disponível sobre quando tentar novamente. Algumas APIs também incluem dicas de quota, como pedidos restantes ou tempo até reset, mas só use essas informações se estiverem documentadas.
Uma regra de decisão que o mantém seguro:
- 429 com
Retry-After: espere esse tempo (mais um pequeno jitter aleatório) e depois reintente.
- 429 sem
Retry-After: reintente com backoff exponencial e jitter, com um limite rígido no tempo total de espera.
- 429s repetidos: pare de reintentar e falhe rapidamente por um curto período (um circuit breaker ajuda aqui).
Timeouts e erros de ligação
Timeouts e erros de ligação normalmente significam sobrecarga, redes instáveis, ou uma má configuração do cliente. Ao contrário do 429, pode não haver um tempo “correto” para esperar. Reintentar pode ajudar, mas só com limites rigorosos.
Registe eventos de limitação de taxa separadamente de outros erros. Um 429 não é o mesmo que “email inválido” ou “API indisponível”. Se os misturar, irá afinar os retries de forma errada e perder tempo à procura da causa real.
Numa fluxo de registo que chama uma API como Verimail, planeie um fallback gracioso. Se a validação estiver temporariamente bloqueada, pode enfileirá‑la para depois, mostrar uma mensagem clara, ou aceitar o email e verificar mais tarde. A escolha certa depende de a validação ser um bloqueio obrigatório ou apenas uma verificação de qualidade.
Defina objetivos antes de adicionar retries
Os retries parecem inofensivos: se um pedido falhar, tente de novo. Na prática, os retries afetam a velocidade do registo, a qualidade dos dados e a pressão que coloca sobre o fornecedor.
Decida o que “sucesso” significa para o seu formulário. Durante o registo, a maioria das equipas prefere uma experiência rápida e previsível a uma certeza absoluta. Se a validação estiver lenta ou limitada por taxa, pode aceitar o email e validar mais tarde em vez de bloquear o utilizador.
Antes de mudar código, escreva algumas regras:
- Experiência do utilizador: Quanto tempo pode a validação acrescentar (por exemplo 200–500 ms) e o que acontece passado esse orçamento?
- Segurança: Quais ações nunca devem acontecer duas vezes (criar contas, enviar emails de boas‑vindas, iniciar trials)?
- Carga: Quantas tentativas de retry são permitidas e qual o tempo máximo total gasto a reintentar?
- Suportabilidade: O que o suporte vê nos logs e consegue explicar a um cliente?
- Fallback: Qual é o padrão seguro sob pressão (bloquear, aceitar ou enfileirar)?
Estes objetivos impedem que reintente indefinidamente, o que muitas vezes transforma um pico breve numa interrupção mais longa.
Exemplo: o seu formulário de registo chama Verimail para filtrar emails descartáveis. Se a API abrandar, a sua regra pode ser “nunca atrasar o registo mais de 1 segundo”. Isso aponta para um timeout curto, um ou dois retries no máximo e depois um fallback (como aceitar o email mas marcá‑lo para revisão posterior).
Passo a passo: implementar backoff e jitter
Retries só ajudam quando são controlados. Se reintentar demasiado depressa ou por tempo demais, pode transformar uma pequena lentidão num problema maior.
1) Defina primeiro um orçamento pequeno
Escolha dois limites: um número máximo de retries e um orçamento de tempo total. O orçamento de tempo importa mais porque o backoff cresce rapidamente.
Para uma verificação interativa no registo, um ponto de partida prático são 2–3 retries dentro de 1–2 segundos no total. Para tarefas em background, pode permitir mais tempo porque o utilizador não está à espera.
2) Use backoff exponencial e depois adicione jitter
Backoff exponencial significa esperar cada vez mais tempo após cada falha. O jitter randomiza essa espera para que milhares de clientes não reintentem ao mesmo tempo.
Um padrão simples:
- Execute o pedido.
- Se falhar com um erro reintentável (como 429 ou um timeout transitório), calcule o próximo atraso.
- Delay = min(maxDelay, baseDelay * 2^attempt) + random(0, jitterRange).
- Durma, depois tente novamente até atingir o seu orçamento de tempo.
Se o servidor enviar Retry-After, trate‑o como um atraso mínimo. Se o seu backoff disser 400 ms mas Retry-After disser 2 segundos, espere 2 segundos.
Se Verimail retornar um 429 durante um pico súbito, honrar Retry-After mais jitter ajuda a suavizar o tráfego em vez de martelar a API.
3) Ajuste definições pelo tipo de carga
Não use uma política de retry única para tudo. Tráfego de registo e tarefas em background têm objetivos diferentes.
Mantenha simples:
- Interativo (registo): poucos retries, orçamento de tempo apertado, fallback rápido.
- Tarefas em background: mais retries, orçamento de tempo maior.
- Importações em lote: ritmo constante para evitar picos.
O objetivo é manter a experiência do utilizador rápida enquanto se mantém educado sob carga.
Idempotência e deduplicação para que os retries não criem duplicados
Retries são mais seguros quando a chamada é apenas de leitura. A validação de email costuma ser isso: faz‑se uma pergunta e obtém‑se uma resposta. Mesmo assim, chamadas duplicadas prejudicam. Gastam quota, acrescentam latência e complicam logs quando uma ação de utilizador dispara múltiplas validações.
Se o seu fornecedor suporta chaves de idempotência, use‑as para qualquer endpoint que possa ter efeitos colaterais (por exemplo, fluxos “validar e armazenar”). Uma chave de idempotência pode ser um UUID por ação do utilizador ou uma impressão estável como um hash do email normalizado mais uma janela temporal. Se as chaves não são suportadas, ainda pode obter a maioria do benefício do lado do cliente.
Uma aproximação prática combina três camadas:
- Normalize e gere uma impressão do email (trim, lowercase, remover espaços óbvios) para que a mesma entrada mapeie para a mesma chave.
- Mantenha um cache de curta duração (normalmente 1–10 minutos) para que verificações repetidas não chamem a API novamente.
- Deduplique pedidos em curso: se várias partes da sua app validam o mesmo email ao mesmo tempo, devem aguardar a mesma promessa em vez de disparar múltiplas chamadas de rede.
Tenha cuidado com o que cacheia. Resultados “válidos” e “inválidos” normalmente são seguros para reutilizar por pouco tempo. Falhas temporárias não são. Se receber um timeout, um 429 ou uma resposta “desconhecida”, faça cache por segundos (ou nada) para não consolidar um resultado erróneo.
Exemplo: durante um pico, um utilizador faz duplo clique em “Criar conta” e o frontend também dispara uma verificação em background. Com fingerprinting e dedupe em‑curso, continua a fazer apenas uma chamada a Verimail, e os retries não multiplicam o tráfego.
Saiba quando reintentar vs quando falhar
Retries ajudam quando o problema é temporário. Atrapalham quando o pedido nunca terá sucesso.
Reintente apenas quando uma nova tentativa puder resultar em sucesso. Isso inclui tipicamente respostas 429, timeouts de rede, resets de ligação e muitos 5xx de curta duração. Se receber um 429, respeite Retry-After quando fornecido.
Não reintente pedidos inválidos. Se a API disser que o seu payload é inválido, faltam parâmetros ou a autenticação está errada, reintentar apenas repete o mesmo erro.
Um filtro de decisão simples:
- Reintentar: 429, timeouts, resets de ligação, 5xx (exceto casos que sabe serem permanentes)
- Falhar rápido: validação de input 4xx, 401/403 de autenticação, campos obrigatórios em falta
- Parar de reintentar quando o seu orçamento de espera total é atingido (por exemplo, 2–3 segundos para registo)
Por vezes o melhor resultado é “continuar sem uma resposta validada”. Durante um pico, pode deixar o registo concluir, guardar uma flag como email_status = needs_review e enfileirar uma revalidação em background.
Seja explícito sobre falhas parciais. Se a validação for ignorada, registe o que aconteceu (código de erro, timestamp, contador de retries) e evite tratar o email como “verificado” mais tarde.
Acrescente um circuit breaker para evitar falhas em cascata
Retries ajudam quando uma indisponibilidade é breve. Mas se a API de validação está lenta ou a falhar por minutos, os retries acumulam‑se e podem prejudicar todo o fluxo de registo. Um circuit breaker impede chamar a API quando as falhas disparam, para que a sua app permaneça responsiva.
Um breaker tem três estados:
- Closed: as chamadas passam normalmente.
- Open: deixa de chamar a API por um período de arrefecimento porque chamadas recentes falharam com demasiada frequência.
- Half‑open: permite algumas chamadas de teste. Se tiverem sucesso, fecha o breaker. Se falharem, abre‑o novamente.
Limiar inicial que funciona para muitas equipas:
- Abrir após 5–10 falhas consecutivas, ou uma taxa de falha de 50% nas últimas 20–50 chamadas
- Tempo de arrefecimento de 15–60 segundos
- Em half‑open, permitir 1–5 chamadas de teste antes de decidir
Quando o breaker está aberto, decida o que faz a sua app. Para registos, pode aceitar o email mas marcá‑lo como “verificação pendente” e validar mais tarde. Para fluxos de maior risco, pode mostrar uma mensagem clara de que a verificação está temporariamente indisponível.
Limitações de taxa e circuit breakers resolvem problemas diferentes. A limitação de taxa é a API a dizer para abrandar (frequentemente com 429 e Retry-After). Um circuit breaker é uma escolha do cliente para pausar chamadas porque os resultados recentes mostram problemas, mesmo que não esteja a ser explicitamente limitado.
Monitorização e afinação que realmente ajuda
Retries e breakers só funcionam se conseguir ver o que estão a fazer.
Acompanhe um pequeno conjunto de métricas que conte a história ao longo do tempo:
- Contagem de retries por pedido (e % de pedidos que reintentam)
- Tempo total de backoff adicionado por pedido
- Taxa de 429 (e com que frequência
Retry-After aparece)
- Taxa de sucesso (2xx) e taxa de falha dura (4xx não reintentados)
- Latência end‑to‑end (p50/p95) para validação, incluindo retries
O registo importa tanto quanto os gráficos. Para cada tentativa de validação, registe um ID de pedido e o resultado final. Se a API devolver o seu próprio ID de pedido, guarde‑o também. Mantenha os logs com privacidade: hash do email permite ainda diagnosticar duplicados.
Os alertas devem focar mudanças sustentadas, não o ruído normal. Alguns 429s numa hora ocupada podem ser aceitáveis. Um pico que dura 10 minutos normalmente significa que os padrões de tráfego mudaram, os retries são demasiado agressivos ou o breaker ficou aberto por muito tempo.
Teste também sob carga. Simule registos em rajada e redes lentas, não apenas chamadas de caminho feliz. Mesmo que o seu fornecedor responda normalmente em milissegundos, os seus timeouts e limites de retry devem assumir que a internet pode ser instável.
Se puder, torne os parâmetros principais ajustáveis sem redeploy: max retries, base backoff, timeout e limiares do breaker. Isso facilita acalmar a situação rapidamente durante picos.
Exemplo: pico de tráfego durante registo
Uma campanha paga dispara e o tráfego de registo aumenta 10x numa hora. A sua app valida cada email à entrada, chamando Verimail como parte do fluxo de registo. Tudo parece bem no início, depois aparecem casos limite: mais pedidos concorrentes, timeouts ocasionais e alguns 429s.
Sem proteção, muitos clientes reintentam imediatamente. Quando centenas de pedidos falham ao mesmo tempo, reintentam em conjunto. Isso cria um thundering herd e faz com que a onda seguinte falhe também, mesmo que a API pudesse ter recuperado com um pouco de respiro.
Com backoff e jitter, os retries espalham‑se. Mesmo um plano simples ajuda:
- Primeiro retry depois de cerca de 200–400 ms (randomizado)
- Segundo retry depois de cerca de 800–1200 ms
- Parar após 2–3 retries para tráfego de registo
Idempotência e caching reduzem ainda mais o volume de chamadas. Durante picos, o mesmo endereço é frequentemente submetido duas vezes (duplo clique, reenvios, utilizadores em dispositivos diferentes). Uma janela de cache curta (por exemplo 10–30 minutos) com chave no email normalizado permite responder a repetições sem chamar a API novamente. Combine isso com uma chave de idempotência para a ação de registo, de modo que um retry não crie registos de utilizador duplicados.
Um circuit breaker mantém o site responsivo quando as falhas se acumulam. Se 429s e timeouts ultrapassarem um limiar, abra o breaker por uma curta janela e salte as chamadas de validação temporariamente. O registo pode continuar marcando o email como “pending verification” e validar em background quando o breaker fechar.
Lista rápida antes de colocar em produção
Antes de ativar retries em produção, defina o que é um “bom comportamento” sob carga. O objetivo é manter os registos a avançar e evitar transformar uma pequena lentidão numa interrupção mais ampla.
- Honrar
Retry-After e limitar o tempo de retry. Siga Retry-After quando presente e defina um limite rígido no tempo total de retry para que um pedido não possa bloquear o sistema.
- Não reintentar erros que causou. Se a API devolve um 4xx claro que aponta para input inválido, reintentar é perda de tempo. Corrija a entrada e devolva uma mensagem útil.
- Deduplique pesquisas repetidas. Adicione uma janela de cache curta para que repetições reutilizem o primeiro resultado.
- Defina regras do breaker e um fallback. Escolha limiares e decida o que acontece quando o breaker abre (aceitar e marcar, enfileirar para depois, ou bloquear fluxos de alto risco).
- Torne as falhas fáceis de diagnosticar. Registe o resultado (sucesso, 429, timeout), o número de retries, o tempo total de espera e se o breaker estava aberto.
Simule um pequeno pico de tráfego em staging e confirme que o serviço se mantém responsivo enquanto o cliente recua educadamente. Se usar Verimail ou um fornecedor similar, o mesmo padrão aplica‑se: respeite os sinais, mantenha os retries limitados e torne o caminho de “desistir” previsível.
Próximos passos: tornar a resiliência o comportamento por omissão
Trate o tratamento de retries e limites de taxa como uma funcionalidade de produto, não como um remendo rápido. Comece conservador, observe o que acontece em produção e ajuste com base nas métricas. As equipas normalmente têm problemas quando os retries são demasiado agressivos e amplificam uma lentidão.
Um plano prático:
- Mantenha os retries baixos (normalmente 2–3) com backoff exponencial e jitter, e honre
Retry-After.
- Acrescente dedupe para qualquer fluxo que possa criar duplicados.
- Defina regras de paragem: o que reintentar, o que falha rápido e quando recorre a “tentar de novo mais tarde”.
- Escreva o comportamento em linguagem simples para produto e suporte (o que os utilizadores vêem, o que é registado e quando a validação é adiada).
- Adicione dashboards e alertas para 429s sustentados, timeouts crescentes e tempo com breaker aberto.
Se as verificações de email forem críticas para o negócio, também ajuda usar um validador construído para baixa latência e alto volume. Verimail (verimail.co) executa verificações sintáticas RFC‑compliant, verificação de domínio e MX, e correspondência em listas de descartáveis/bloqueio em tempo real numa única chamada de API, o que reduz a frequência com que o seu cliente acaba no caminho de “retry”.
Agende revisões periódicas à medida que os padrões de tráfego mudam. Reavalie os limiares, atualize como lida com domínios descartáveis e confirme que o comportamento face a limites de taxa ainda corresponde ao comportamento real dos utilizadores e às necessidades do suporte.