19 de jan. de 2025·8 min
Plano de implantação de validação de e-mail em múltiplas etapas além de checagens só por regex
Planeje um rollout de validação de e-mail em múltiplas etapas a partir de checagens só por regex, com marcos, métricas, rampas de tráfego graduais e fallbacks seguros para evitar quebra de cadastros.
Por que checagens apenas por regex param de funcionar em escala
Uma verificação só por regex responde a uma pergunta: isso parece um endereço de e-mail? Ela captura erros óbvios, como a falta do @, espaços ou um formato de domínio quebrado. Isso é útil, mas é só um teste de formato. Não diz se o endereço pode receber mensagens.
À medida que o volume de cadastros aumenta, os erros começam a importar mais do que os acertos. Regex não informa se um domínio existe, se tem registros MX funcionando ou se um endereço pertence a uma caixa descartável. Também não protege contra spam traps e outros endereços que parecem válidos, mas prejudicam a entregabilidade.
As equipes geralmente aprendem algumas lições do jeito difícil:
- Se você for excessivamente rígido, bloqueia usuários legítimos (incluindo endereços incomuns, mas válidos) e a conversão cai silenciosamente.
- Se for permissivo demais, contas falsas passam, a carga de suporte aumenta e as rejeições se acumulam.
- Com o tempo, rejeições repetidas e reclamações podem prejudicar a reputação do remetente, fazendo cada campanha performar pior.
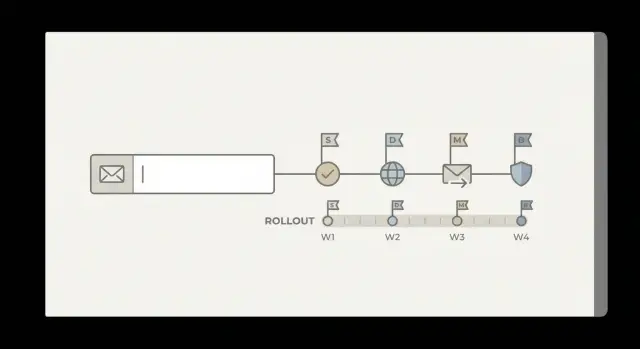
Por isso um rollout de validação de e-mail em múltiplas etapas importa. Você passa de uma simples checagem de padrão para verificações em camadas (sintaxe, domínio, MX e sinais de risco), mas faz isso de modo que não surpreenda clientes reais.
Um rollout seguro tem três objetivos: mínimo impacto ao usuário (sem quebras súbitas no cadastro), progresso mensurável (métricas claras antes e depois de cada mudança) e um rollback simples (uma chave para voltar ao comportamento anterior se a conversão ou entregabilidade cair).
Este plano é para times de produto, engenharia e growth com o mesmo objetivo: manter o atrito de cadastro baixo enquanto reduz endereços inválidos e fraudes. Ferramentas como Verimail podem rodar as checagens em múltiplas etapas em uma só chamada de API, mas a abordagem de rollout é a mesma independentemente da ferramenta.
Defina objetivos, restrições e responsabilidades
Antes de mudar a validação, deixe claro o que “bom” significa para o seu negócio. O objetivo não é bloquear pessoas. É aceitar e-mails reais e alcançáveis enquanto reduz cadastros de baixa qualidade que desperdiçam tempo e prejudicam a entregabilidade.
Anote 2–3 resultados mensuráveis, como menos endereços descartáveis no cadastro, menos hard bounces na primeira semana e menos contas criadas para abuso. É aqui também que você decide quão rígidas as regras devem ser em diferentes fluxos.
Objetivos e restrições a concordar
Coloque alguns limites para que a validação ajude sem criar novos problemas:
- Latência: sem lentidão perceptível em fluxos críticos (especialmente cadastro e checkout).
- Conversão: sem queda significativa na taxa de conclusão após a aplicação.
- Carga de suporte: mantenha tickets “por que meu e-mail foi rejeitado?” previsíveis e raros.
- Justiça: permita casos legítimos de borda (domínios novos, servidores corporativos, plus addressing).
- Conformidade: armazene apenas o necessário (evite logar e-mails completos em analytics se não for preciso).
Em seguida, decida onde a validação roda. A maioria começa no cadastro, mas convites, resets de senha, recibos de checkout e usuários criados por admins também podem introduzir endereços ruins. Uma regra simples: valide sempre que criar um novo registro de e-mail e mantenha a experiência consistente.
Responsabilidades e direitos de decisão
Checagens em múltiplas etapas criam decisões de produto e suporte, não apenas tarefas de engenharia. Concordem de antemão sobre quem é responsável pelo quê:
- Produto: o que é bloqueado vs o que recebe aviso, e qual a mensagem de erro.
- Engenharia: onde as checagens rodam, timeouts, retries e como os resultados são cacheados.
- Dados/marketing: quais métricas definem sucesso (redução de rejeições, taxa de abuso, entregabilidade).
- Suporte: um playbook curto para overrides e explicações comuns ao usuário.
Se usar uma API como Verimail no cadastro, decida quem pode afrouxar regras se a conversão cair e com que rapidez responderão quando um usuário legítimo for bloqueado.
Como é a validação em múltiplas etapas em termos simples
Verificação só por regex é como checar se uma chave parece correta sem experimentá-la na fechadura. A validação em múltiplas etapas adiciona algumas checagens rápidas que dizem se um endereço é provável e alcançável.
A primeira é sintaxe, mas feita corretamente. Uma checagem de sintaxe compatível com RFC lida com formatos que regexes básicas quebram, como plus addressing ([email protected]), pontos na parte local e TLDs modernos mais longos. Também evita falsos positivos que batem no padrão mas violam regras do e-mail.
A segunda é verificação do domínio. Se o domínio não existe, ninguém pode receber e-mail ali. Uma consulta DNS confirma se o domínio é real, e uma busca por registros MX verifica se o domínio anuncia servidores de e-mail (ou roteia através de registros relacionados). Isso captura erros como gmal.com e domínios mortos que um regex aceitaria.
A terceira são sinais de reputação e risco. Isso inclui detectar provedores descartáveis e comparar com blocklists de fontes conhecidas como ruins ou arriscadas.
A ideia não é “bloquear mais”. É escolher a ação certa para cada nível de confiança:
- Permitir: passa por todas as etapas.
- Aviso leve: parece arriscado, mas deixar o usuário seguir.
- Requerer confirmação: aceita o cadastro, mas verifica via e-mail antes da ativação.
- Bloquear: claramente inválido, descartável (se sua política assim determinar) ou de alto risco.
Planeje casos de borda como subdomínios (mail.eu.company.com), gateways corporativos que roteiam e-mail de maneiras incomuns e aliases legítimos com plus addressing. Ferramentas como Verimail podem rodar essas checagens em uma única chamada de API, mas sua política de produto decide o que acontece após cada resultado.
Obtenha uma linha de base antes de mudar qualquer coisa
Antes de um rollout de validação em múltiplas etapas, você precisa de um retrato claro de como o cadastro se comporta hoje. Sem uma linha de base, é fácil “melhorar” a validação enquanto prejudica silenciosamente conversão, suporte ou entregabilidade.
Instrumente todo o funil de cadastro e os resultados de e-mail ponta a ponta. Meça não só quantos usuários concluem o cadastro, mas o que acontece depois: os e-mails de verificação chegam, os usuários ativam e as mensagens são rejeitadas mais tarde?
Acompanhe um pequeno conjunto de métricas básicas por pelo menos 1 a 2 ciclos normais de negócio (geralmente 7 a 14 dias):
- Taxa de conversão de cadastro (visita para conta criada)
- Taxa de entrega do e-mail de verificação e tempo até verificar
- Taxa de rejeição (hard e soft) nos primeiros envios
- Taxa de reclamação (quando provedores marcam suas mensagens)
- Tickets de suporte ligados a “não consegui me cadastrar” ou “não recebi o e-mail”
Se você já rejeita alguns endereços (mesmo com validação só por regex), registre cada motivo de rejeição e o contexto: tipo de cliente, país/locale, domínio e se o usuário tentou novamente com outro endereço. Tickets de suporte fazem parte da linha de base também, porque checagens mais rígidas podem deslocar a dor de rejeições para usuários bloqueados.
Em seguida, crie um conjunto de dados rotulado com cadastros recentes. Uma abordagem simples é amostrar as últimas semanas de contas novas e rotular cada e-mail como: aceito e ativo, aceito mas depois rejeitado, aceito mas depois reclamado, ou nunca verificado. Isso vira sua “verdade de base” para comparar novas checagens.
Finalmente, decida como quantificar erros durante o rollout:
- Falsos positivos: e-mails legítimos bloqueados ou retardados (observe quedas de conversão e picos de tickets).
- Falsos negativos: e-mails ruins permitidos (observe rejeições, domínios descartáveis e sinais de spam traps).
Quando você testar um validador (por exemplo, Verimail em modo shadow), pontue as decisões dele contra essa linha de base para que mudanças sejam mensuráveis, não anedóticas.
Fase 1: Modo shadow para aprender sem quebrar cadastro
Modo shadow significa rodar as novas checagens em cada cadastro, mas não bloquear ninguém ainda. A experiência do usuário permanece igual. Seu time obtém dados reais sobre o que o validador teria feito, sem arriscar queda de conversão.
Registre os resultados de cada etapa, não apenas um único passe/falha. Por exemplo: resultado da checagem de sintaxe, domínio existe, registros MX encontrados, descartável detectado e qualquer correspondência em blocklist. Mantenha a decisão antiga baseada em regex ao lado para que você possa comparar depois.
Um primeiro marco útil é responder três perguntas com números:
- Qual a proporção de cadastros que são e-mails descartáveis?
- Qual a proporção que tem domínios inválidos ou que não resolvem?
- Qual a proporção que parece arriscada (por exemplo, suspeita de traps ou outros sinais vermelhos)?
Essas taxas se tornam sua linha de base para o rollout. Se usar uma API de validação como Verimail, armazene a resposta bruta e sua decisão interna final separadamente, para que você possa mudar regras depois sem perder histórico.
Escolha uma cadência de revisão que mostre problemas rápido. Revisões diárias na primeira semana geralmente captam surpresas como um pico de um canal de tráfego ou um domínio corporativo comum que falha em checagens DNS durante um problema temporário. Depois da primeira semana, mude para semanal.
Um exemplo prático: se sua regex aceita 98% dos cadastros, mas o modo shadow mostra 6% como descartáveis e 1% com domínios inválidos, você agora tem um alvo claro para o que a aplicação poderia reduzir. Também tem uma lista de casos de borda para tratar com cuidado antes de bloquear usuários reais.
Fase 2: Aplicação gradual com marcos mensuráveis
Choose the right action
Use reason codes to warn, confirm, or block based on your policy.
Depois do modo shadow, passe para a aplicação em passos pequenos e reversíveis. O objetivo é reduzir e-mails ruins sem surpreender usuários reais ou prejudicar a conversão.
Comece com um segmento estreito onde o risco é baixo e o aprendizado é alto. Uma escolha comum são cadastros vindos de anúncios pagos, tráfego de afiliados ou uma única geografia onde você vê mais e-mails descartáveis. Mantenha o resto do tráfego inalterado para comparar resultados.
Inicie com ações de baixo risco antes de bloqueios rígidos. Se a validação sinalizar um endereço como descartável ou inalcançável, mostre uma mensagem curta pedindo para o usuário revisar e tentar outro e-mail. Facilite a edição e continuação. Só passe a bloqueio rígido quando tiver confiança de que não está pegando usuários legítimos.
Um plano de ramp simples:
- Aplicar para 5% do segmento escolhido, monitorar métricas por 24–48 horas.
- Aumentar para 25% se as condições de parada não forem atingidas.
- Subir para 50% e depois 100% para esse segmento.
- Expandir para o próximo segmento (outro canal ou região) e repetir.
- Quando estável entre segmentos, aplicar para todos os novos cadastros.
Defina condições de parada com antecedência e documente-as. Exemplos: conversão de cadastro cai mais que X%, tempo mediano para concluir cadastro aumenta Y segundos, contatos de suporte sobre cadastro sobem acima de Z por dia ou as rejeições downstream param de melhorar.
Acompanhe marcos que reflitam experiência do usuário e valor de negócio: taxa de conversão, tempo para concluir cadastro, quantos usuários tentam novamente com outro e-mail, volume de suporte e taxa de rejeição dos e-mails de boas-vindas. Se usar uma API como Verimail, também monitore como as taxas de “inválido” e “descartável” mudam conforme você faz ramp.
Trate cada aumento como um ponto de decisão com um limite claro para avançar, segurar ou reverter. Isso mantém o rollout calmo e fácil de explicar entre produto, engenharia e suporte.
Métricas e dashboards que realmente pegam regressões
Se você só olhar “cadastros subiram ou caíram”, vai perder o impacto real das mudanças de validação. Construa um dashboard para saúde imediata do cadastro e uma segunda visão que acompanhe esses usuários na entrega de e-mails e resultados de abuso.
Escolha um pequeno conjunto de métricas primárias que serão decisoras. Mantenha-as visíveis em todo gráfico e evite adicionar tantas linhas que ninguém saiba o que importa.
Essas cinco costumam mostrar a verdade rápido:
- Taxa de conversão de cadastro (cadastros concluídos / cadastros iniciados)
- Taxa de inválidos ou inalcançáveis (resultados da validação mais rejeições posteriores)
- Taxa de e-mails descartáveis (e como muda por canal)
- Sinais de abuso (denúncias de spam, cadastros suspeitos, account takeovers ligados a contas novas)
- Resultados de entrega pós-cadastro (taxa de rejeição, taxa de reclamação, proxies de colocação em inbox se tiver)
Adicione guardrails antes de aplicar qualquer regra. Use limites, não intuição: por exemplo, “no máximo 0,5% de queda absoluta na conversão” e “no máximo 50 ms a mais de latência no p95”. Se um guardrail for violado, pause o rollout e investigue.
Fatie cada métrica por coorte para detectar falhas localizadas: canal de aquisição, país, tipo de dispositivo e categoria de domínio de e-mail (provedores grátis vs domínios corporativos). Uma regressão comum é bloquear demais em uma geografia ou no mobile, onde erros de digitação são mais frequentes.
Revise casos limite semanalmente. Puxe uma amostra pequena de endereços “arriscados mas não claramente ruins” e verifique se pessoas reais estão sendo bloqueadas. Se usar uma API como Verimail, registre códigos de motivo (sintaxe, MX, blocklist) para ver qual etapa está causando atrito e ajustar regras sem chutar no escuro.
Fallbacks, rollbacks e opções de experiência segura para o usuário
Roll back with confidence
Use feature flags and a kill switch with consistent validation responses.
A validação em múltiplas etapas pega mais cadastros ruins, mas também pode bloquear usuários reais se algo mudar (queda de DNS, domínios corporativos novos, problemas temporários de roteamento). Planeje a falha antes de ativar a aplicação.
Comece com um interruptor de emergência que retorne instantaneamente ao comportamento por regex. Faça isso via configuração server-side, não via deploy. Combine com feature flags para cada tipo de regra para poder desabilitar uma parte sem perder tudo: tratamento de MX, bloqueio de descartáveis e checagens de blocklist.
Quando você bloqueia ou desafia um usuário, escolha um fallback que mantenha o cadastro andando enquanto protege a plataforma. Opções eficazes incluem:
- Permitir cadastro, mas exigir confirmação por e-mail antes do login ou antes de ativar ações-chave.
- Permitir cadastro, mas atrasar recursos de alto risco (referências, cupons, chaves de API, créditos de teste) até a verificação.
- Colocar a conta em modo limitado enquanto você revalida o e-mail após alguns minutos.
- Pedir outro e-mail apenas quando o sinal for forte (provedor descartável conhecido, problemas claros de sintaxe).
Com qualquer API de validação, falsos positivos são o maior risco do rollout. Trate-os como incidentes. Defina quem é acionado, com que rapidez e o que significa “estancar o sangramento” (geralmente disparar o kill switch ou desabilitar a flag mais rígida primeiro). Mantenha a comunicação interna simples: o que quebrou, quem foi impactado e o que você mudou.
Um playbook leve de incidentes pode ser pequeno:
- Confirme o pico (cadastros bloqueados, tickets de suporte, queda de conversão).
- Desative a flag mais provável (descartável ou blocklist) antes de desligar tudo.
- Reúna exemplos de endereços bloqueados e verifique padrões (domínio, região, provedor).
- Decida se é um outage temporário ou um problema de regras.
- Documente a correção e adicione um teste ou monitor para pegar mais cedo da próxima vez.
Por fim, mantenha um processo de allowlist para domínios importantes (parceiros, grandes clientes). Exija um dono, um motivo e um rastro de auditoria, e revise entradas periodicamente para que exceções não se acumulem silenciosamente.
Armadilhas comuns que equipes enfrentam durante a migração
A maioria dos problemas de migração não é sobre o validador em si. Vêm de tratar sinais iniciais como verdade final e aplicar regras rápido demais. Um rollout seguro precisa de espaço para incerteza.
Um erro comum é bloquear cadastros porque o DNS ficou instável por um minuto. Usuários reais não controlam seus resolvers DNS, Wi‑Fi de hotel ou firewalls corporativos. Se seu sistema fizer uma única busca e falhar fechado, você rejeitará bons e-mails. Faça cache de checagens de domínio quando possível, retry com curto delay e registre o motivo para ver se falhas se concentram por região ou ISP.
Outra armadilha é assumir que “sem MX” sempre significa “inválido”. Alguns domínios aceitam e-mail no A record da raiz, e algumas configurações são incomuns mas reais. Se tratar todo “sem MX” como bloqueio rígido, vai gerar falsos positivos. Trate como sinal de risco a menos que tenha forte evidência de que é inalcançável.
Bloquear descartáveis também pega equipes desprevenidas. Se seu produto tem casos legítimos de uso temporário (trials, downloads pontuais, inscrição em eventos), um bloqueio rígido pode prejudicar conversões. Em vez de proibição total, decida o que você está protegendo: abuso, chargebacks, entregabilidade ou todos os três.
Alguns padrões de falha que aparecem em postmortems:
- Não separar “definitivamente inválido” de “não foi possível verificar agora”
- Aplicar regras globais antes de testar por segmento (país, fonte de tráfego, dispositivo)
- Lançar sem scripts de suporte e mensagens claras ao usuário
- Tratar erros temporários de DNS como falhas permanentes de domínio
- Bloquear domínios descartáveis sem um plano de exceção específico ao produto
Um exemplo realista: você aplica globalmente numa segunda-feira, timeouts DNS disparam em uma região e o suporte vê tickets “meu e-mail é real” em horas. Se tivesse um caminho “tente novamente” para “não foi possível verificar agora” e rollout por segmento, manteria os cadastros fluindo enquanto investiga.
Checklist rápido de rollout
Antes de aplicar qualquer regra, certifique-se de que pode provar se a mudança ajudou ou prejudicou. O rollout é mais seguro quando cada etapa tem dono claro, objetivo mensurável e uma forma fácil de desfazer.
Use este checklist antes de passar do teste para a aplicação real:
- Linha de base capturada e estável: Você tem alguns dias (ou semanas) de conversão de cadastro, taxa de rejeição de e-mails e tickets de “e-mail inválido” rastreados num lugar, e conhece a faixa normal.
- Resultados do modo shadow revisados e decisões documentadas: Você revisou o que o validador teria bloqueado, checou amostras de casos de borda (domínios corporativos, TLDs incomuns) e concordou em thresholds (quando bloquear vs avisar).
- Feature flags e kill switch testados em produção: Você pode ligar/desligar validação instantaneamente sem deploy, e testou o caminho “off” em tráfego real (não só staging). Se chamar uma API como Verimail, inclua timeouts e comportamento padrão seguro.
- Suporte pronto para as primeiras reclamações: Você tem respostas prontas curtas para “Por que meu e-mail foi rejeitado?”, uma forma de coletar exemplos e um caminho claro de escalonamento para o engenheiro dono do rollout.
- Cronograma e condições de parada documentadas: Você tem um calendário de rollout, donos nomeados para cada etapa e razões específicas para pausar (por exemplo, conversão cai mais que X% por Y horas, ou falsas rejeições excedem um número definido).
Quando isso estiver pronto, o rollout vira rotina: ative a próxima porcentagem, observe as mesmas métricas e pare rápido se os usuários sentirem dor.
Um cenário de rollout realista
Run shadow mode today
See what would be blocked without changing signup behavior.
Um app SaaS de porte médio começa a ver dois problemas: trials falsos (contas que nunca fazem login) e aumento na taxa de rejeição dos e-mails de onboarding. O formulário de cadastro só usa validação por regex, então quase tudo que parece um e-mail passa.
Eles adicionam validação em múltiplas etapas em modo shadow primeiro. Cadastros continuam iguais, mas todo e-mail submetido é verificado em background por sintaxe, domínio, registros MX e provedores descartáveis. Após duas semanas, a equipe revisa e encontra dois padrões: grande parte dos novos trials usa domínios descartáveis e um grupo menor usa domínios que não aceitam e-mail (sem MX, domínios estacionados ou erros comuns).
Com esses dados, passam para aplicação gradual com marcos simples:
- Semana 1: mostrar aviso educado para e-mails descartáveis e pedir um inbox alternativo.
- Semana 2: bloquear apenas inválidos claros (domínio ruim, sem DNS), ainda permitindo o restante.
- Semana 3: bloquear padrões de abuso recorrentes (por exemplo, múltiplos cadastros da mesma fonte usando diferentes descartáveis).
Eles também adicionam um fallback seguro para casos incertos. Se a checagem não tiver confiança, o usuário pode se cadastrar, mas deve confirmar o e-mail antes de acessar recursos-chave. Isso mantém usuários reais fluindo enquanto filtra cadastros de baixa qualidade.
Ao final do rollout, o time busca um resultado acima de tudo: rejeições caem sem impacto significativo em trials iniciados ou ativados. Se rejeições de onboarding caírem e trials ativados se mantiverem, apertam a política de descartáveis. Se a conversão cair, relaxam a aplicação e usam mais confirmação até afinarem as regras.
Próximos passos: implementar, afinar e melhorar continuamente
A validação em múltiplas etapas só parece arriscada quando as regras são vagas. Escolha uma primeira regra de aplicação que seja de baixo risco e alto valor. Para muitos times, isso significa bloquear domínios claramente inválidos (sem DNS) e tratar provedores descartáveis conforme a política do produto.
Escreva uma política interna curta para que todos saibam o que “válido” significa no seu produto:
- Bloquear: óbvios inválidos (sintaxe quebrada, domínio morto, domínios descartáveis se seu produto depende de identidade real)
- Avisar: arriscados mas possíveis (erros de digitação, catch-all, hosts temporários que você não está pronto para bloquear)
- Permitir: todo o resto, mas rotular para medir os resultados depois
Depois escolha um validador que rode checagens rápidas em múltiplas etapas (sintaxe, domínio, MX e detecção de descartáveis) e retorne códigos de motivo que você possa logar. Se estiver avaliando Verimail (verimail.co), ele é projetado para esse estilo de rollout: uma chamada de API pode cobrir sintaxe, verificação de domínio, lookup de MX e detecção de descartáveis, e você pode começar em modo shadow antes de aplicar qualquer regra.
Agende uma revisão pós‑rollout (por exemplo, 7–14 dias após o início da aplicação). Traga um conjunto pequeno de e-mails disputados, procure falsos positivos e ajuste thresholds ou allowlists. Um bom rollout não é um switch único. É um conjunto vivo de regras que evolui conforme os padrões de cadastro mudam.
Perguntas Frequentes
Por que a validação por regex sozinho não é suficiente?
Uma checagem por regex só diz se a entrada parece um endereço de e-mail. Ela não confirma que o domínio exista, que o domínio possa receber mensagens, nem se o endereço vem de um provedor descartável — portanto, endereços ruins ainda passam e depois viram rejeições e reclamações.
O que geralmente inclui “validação de e-mail em múltiplas etapas”?
Comece com verificações em camadas que respondem perguntas diferentes: sintaxe conforme RFC, existência do domínio via DNS, registros MX (ou roteamento equivalente) e sinais de risco como provedores descartáveis e fontes conhecidas como maliciosas. Trate a resposta como um sinal de confiança e então decida permitir, avisar, exigir confirmação ou bloquear.
Como adicionamos validação em múltiplas etapas sem prejudicar a conversão?
Use o modo shadow: rode o novo validador em todos os cadastros, mas não mude o que o usuário vê ainda. Registre o resultado de cada etapa e compare com o que sua regex atual teria decidido, assim você entende o impacto real antes de aplicar regras.
Quais métricas devemos monitorar durante o rollout?
No mínimo, acompanhe conversão de cadastro, taxa de entrega dos e-mails de verificação, taxa de rejeição inicial nas primeiras envios, taxa de reclamações e tickets de suporte relacionados a cadastro ou e-mails não recebidos. Fatia esses dados por coorte (canal, região, dispositivo, tipo de domínio) para detectar regressões localizadas.
Qual é a melhor primeira regra para aplicar após o modo shadow?
Uma primeira regra segura é bloquear entradas claramente inválidas, como sintaxe quebrada ou domínios inexistentes — esses usuários não podem receber e-mail. Para casos incertos, prefira um aviso ou o fluxo “cadastre agora, verifique antes do acesso” até ter dados suficientes para endurecer as regras.
Devemos bloquear e-mails se o domínio não tem registro MX?
Trate “sem MX” como um sinal de risco, não como uma falha absoluta. Alguns domínios aceitam e-mail por outras configurações e bloquear rigidamente pode gerar falsos positivos; uma alternativa mais segura é permitir com confirmação obrigatória ou aviso suave, a menos que haja fortes evidências de que o domínio é inalcançável.
Como devemos ramp-up a aplicação de regras com segurança?
Use rollout gradual por segmentos com feature flags e condições de parada predefinidas. Por exemplo, aplique primeiro a um único canal ou região, aumente as porcentagens lentamente e pause ou reverta se a conversão cair além do limite ou os tickets de suporte subirem.
Qual plano de rollback devemos ter antes de aplicar regras?
Tenha um kill switch no servidor que retorne instantaneamente ao comportamento anterior sem precisar de deploy. Separe flags por tipo de regra (tratamento de MX, bloqueio de descartáveis, checagens em blocklist) para desabilitar a regra mais problemática sem desligar tudo.
Quais alternativas amigáveis ao usuário existem além do bloqueio rígido?
Mantenha o cadastro avançando enquanto reduz riscos: permita a criação da conta mas exija confirmação antes do login ou antes de liberar recursos sensíveis, ou limite funcionalidades de alto risco até a verificação. Mensagens curtas e específicas ajudam o usuário a corrigir o e-mail facilmente.
O que devemos procurar em uma API de validação de e-mails como Verimail?
Procure um validador que retorne códigos de motivo claros que você possa registrar (sintaxe, DNS, MX, descartável, blocklist) e que responda rápido o suficiente para uso no cadastro. Verimail é um exemplo que faz essas checagens com uma única chamada de API, facilitando começar em modo shadow e aplicar regras gradualmente conforme sua política.