17 de fev. de 2025·6 min
Padrões de validação assíncrona de e-mails para cadastros rápidos e confiáveis
Aprenda padrões de validação assíncrona de e-mails usando filas, webhooks e retries para manter cadastros responsivos em alto tráfego e melhorar a qualidade dos dados.
Por que a validação síncrona falha sob alto tráfego
Um endpoint de cadastro deve ser rápido: aceitar alguns campos, criar um registro e responder. A validação síncrona de e-mail transforma esse caminho simples em uma cadeia de chamadas de rede, e cada chamada é mais uma chance de travar.
Sob carga, as partes lentas raramente são o seu próprio código. São as dependências que você espera: consultas DNS, checagens MX e verificações em blocklists. Mesmo que cada etapa normalmente seja rápida, a cauda longa importa. Uma pequena porcentagem de requisições será lenta e, quando o tráfego dispara, essas requisições lentas se acumulam e começam a bloquear todo o resto.
Em sistemas reais, tende a haver um efeito cascata:
- A latência sobe de algumas centenas de milissegundos para vários segundos.
- Requisições expiram, então usuários dão refresh e criam ainda mais carga.
- Servidores da aplicação ficam sem threads de trabalho porque muitas requisições estão esperando.
- Serviços downstream são sobrecarregados, causando mais falhas e retries mais lentos.
Isso prejudica conversão e disponibilidade. Pessoas abandonam páginas de cadastro lentas. Enquanto isso, sua equipe vê taxas de erro elevadas e começa a escalar infraestrutura só para lidar com esperas.
Imagine uma promoção onde 10.000 pessoas tentam se cadastrar em cinco minutos. Se a rota de cadastro espera por validação externa, uma desaceleração temporária de DNS pode virar um incidente de sistema. O caminho de cadastro vira o gargalo.
A validação assíncrona de e-mails é uma solução comum em sistemas de alto tráfego: aceite o cadastro rapidamente e valide em segundo plano. Isso melhora a responsividade e reduz falhas em cascata. Não resolve tudo, porém. Você ainda precisa decidir o que uma conta nova pode fazer antes que o e-mail seja confiável.
Decida o que precisa acontecer antes de criar a conta
Cadastros rápidos e dados perfeitos raramente acontecem ao mesmo tempo. Se você tentar validar completamente todo e-mail antes de criar a conta, adiciona latência exatamente onde os usuários têm mais probabilidade de abandonar.
Uma regra prática: faça apenas checagens que sejam baratas, locais e determinísticas antes de criar a conta. Todo o resto pertence ao pipeline assíncrono.
O que costuma fazer sentido checar imediatamente:
- Verificação de campos obrigatórios (e-mail presente, senha presente, consentimento registrado se necessário)
- Formato básico do e-mail e erros óbvios de digitação (falta de @, espaços, caracteres inválidos)
- Limitação simples de taxa ou sinais de abuso que você já tem em memória
- Uma checagem rápida “isso já está em uso?” (se seu produto requer e-mails únicos)
Checagens mais profundas podem esperar sem quebrar a experiência do usuário. Verificação de domínio, consultas MX, detecção de provedores descartáveis, sinais de spam traps e matching em blocklists em tempo real podem ser lentos ou eventualmente expirar.
A decisão chave é sua “janela de risco”: quanto tempo você permite que uma conta não confiável exista e o que ela pode fazer nesse período. Por exemplo, você pode permitir que o usuário configure o perfil, mas bloquear envio de convites, início de trial ou acesso a funcionalidades de alto valor até a validação completar.
Padrão central: aceite agora, verifique depois
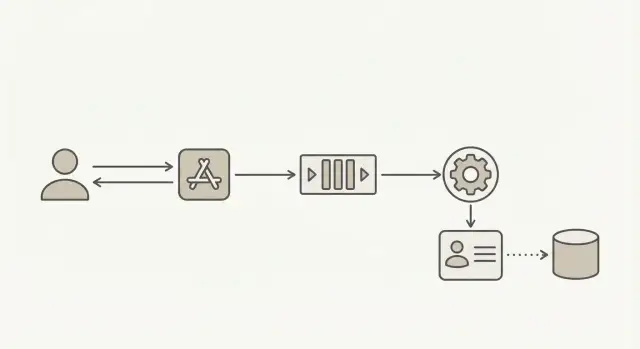
Para manter cadastros rápidos sob carga, separe “criar um usuário” de “confiar no e-mail”. Aceite a requisição, crie a conta imediatamente e marque-a como pendente. Então execute a validação em segundo plano, onde atrasos não vão retardar o endpoint de cadastro.
Trate a validação como um workflow próprio, com status e timestamps — não apenas um booleano. Isso torna retries mais seguros, debugging mais fácil e o comportamento do cadastro mais previsível.
Um fluxo comum:
- Crie o usuário e defina
email_status = pending(armazene quando você enfileirou a validação) - Enfileire um job de validação (incluir
user_ide e-mail) - O worker valida e atualiza
email_statusparavalid,risky,invalidouunknown - Sua app libera ou restringe ações com base nesse status
Você ainda pode orientar o usuário sem bloquear a requisição. Mostre “Confira sua caixa de entrada para confirmar o e-mail” imediatamente. Quando a validação terminar, atualize o que ele pode fazer.
Quando a validação falha mais tarde, decida antecipadamente o que acontece a seguir. Opções comuns são restringir ações sensíveis, pedir um novo e-mail ou remover contas claramente falsas após um período de carência.
Um modelo de dados simples para estados de validação
Se a validação roda depois, seu banco de dados ainda deve responder a perguntas simples: o que o usuário digitou, para qual valor você normalizou e no que você acredita atualmente.
Armazene a entrada bruta separadamente do valor normalizado. A entrada bruta ajuda suporte e debug (pessoas colam espaços estranhos). Campos normalizados são o que você usa para casar e enviar.
Um pequeno conjunto de estados funciona bem:
pending: aceito no cadastro, job de validação não finalizadovalid: aparentemente alcançável e seguro para manterrisky: tecnicamente válido, mas de baixa qualidade provável (por exemplo, descartável ou role-based)invalid: falhou nas checagens (sintaxe ruim, domínio inválido, sem MX, conhecido como descartável)unknown: falha temporária (timeouts, erros de provedor), tente novamente mais tarde
Junto com o status, armazene as evidências, não apenas o veredito. Um pacote compacto de “fatos de validação” evita suposições depois e facilita mudanças de política.
Campos sugeridos (nomes de exemplo):
email_raw,email_normalized,email_domainvalidation_status,validated_at,validation_providervalidation_reason_code,validation_reason_textpolicy_version(ouruleset_id), além de um contadorvalidation_attempt
Exemplo: um usuário se cadastra com " [email protected] ". Armazene a string exata em email_raw, normalize para [email protected], defina o status como pending e deixe a conta seguir com privilégios limitados. Quando a validação terminar, atualize status e fatos sem reescrever a entrada original.
Passo a passo: construa um pipeline de validação assíncrono
Try it on real traffic
Use the free tier with 100 validations per month, no credit card required.
1) Crie o usuário e publique um job de validação
Quando alguém envia o formulário de cadastro, salve o registro do usuário imediatamente, marque o e-mail como pendente e publique um job pequeno na sua fila. O job precisa apenas de user_id, email e um timestamp requested_at.
Mantenha o payload pequeno. Seu banco de dados continua sendo a fonte da verdade, então os workers podem reler o estado mais recente do usuário.
2) Valide em um worker e registre um código de motivo
Um worker em background consome jobs e executa a validação. É aqui que você chama seu serviço de validação de e-mails sem atrasar a resposta do cadastro.
Escreva o resultado com status e um código de motivo. Status podem ser valid, risky, invalid ou unknown. Códigos de motivo podem ser syntax_error, no_mx, disposable, spam_trap_risk ou timeout.
Códigos de motivo importam porque aceleram suporte e decisões de produto. “Invalid” não é suficiente quando você precisa decidir o que mostrar ao usuário.
3) Dispare a ação de follow-up correta
Depois de salvar o status, aplique sua política:
- Valid: desbloqueie limites normais e envie e-mails de lifecycle
- Risky: permita login, mas reduza limites ou marque para revisão
- Invalid: peça um novo e-mail antes de ações chave
- Unknown: tente novamente mais tarde e mantenha a conta limitada
4) Recheque quando o e-mail mudar
Quando um usuário atualiza o e-mail, redefina o status para pending e publique um novo job. Registre qual endereço foi checado para que resultados antigos nunca se apliquem a um valor novo.
Fluxo de validação por webhook: push vs pull
Uma vez que a validação é assíncrona, você precisa de um jeito de trazer os resultados de volta para sua app. Há dois modelos principais:
Pull significa que sua app checa o status depois. É mais fácil de raciocinar e muitas vezes suficiente quando apenas um sistema precisa da resposta. A desvantagem é tráfego extra e atualizações mais lentas se você fizer polling pouco frequente.
Push significa que o validador faz um callback com um evento do tipo webhook assim que o resultado estiver pronto. Isso ajuda quando múltiplos sistemas se importam (serviço de cadastro, sincronização com CRM, automação de marketing) ou quando você quer atualizações quase em tempo real sem polling.
Se implementar push, mantenha o payload do callback pequeno, mas completo:
- Identificador interno (user id ou account id)
- Status de validação (
valid,invalid,risky,unknown) - Código de motivo
- Timestamp e um id único do evento
- Opcional: um hash do e-mail (não o e-mail bruto) para debug
Proteja isso. Exija HTTPS, verifique uma assinatura com um segredo compartilhado, rejeite requisições antigas por timestamp e mantenha um cache de “event ids vistos” de curta duração para prevenir replay. Se sua infraestrutura suportar, adicione uma allowlist de IPs.
Noções básicas de confiabilidade: retries, idempotência e backpressure
Mover a validação para fora da requisição de cadastro ganha velocidade, mas você ainda precisa lidar com falhas do dia a dia: redes caem, provedores expiram, workers caem no meio de um job.
Retries: trate a validação como passível de retry. Timeouts e erros 5xx são normalmente temporários, então reenvie com um atraso que cresce a cada tentativa. Mantenha a janela limitada para não validar o mesmo endereço por horas.
Idempotência: presuma entregas duplicadas de filas e webhooks. Dê a cada requisição uma chave de dedup estável (por exemplo, um request_id ou (user_id, validation_attempt)), então torne suas atualizações seguras para aplicar duas vezes e terminar no mesmo estado final.
Dead letters: quando retries continuarem falhando, pare. Mova o job para uma dead-letter queue e marque o e-mail como unknown para que você possa investigar depois.
Backpressure: limite concorrência e defina orçamentos de tempo para que a validação não possa sobrecarregar caminhos críticos como cadastro, login e cobrança.
Algumas métricas pegam a maioria dos problemas cedo:
- Profundidade e idade da fila (há quanto tempo o job mais antigo está aguardando)
- Taxa de sucesso vs falhas transitórias vs falhas permanentes
- Tempo médio de validação e latências p95/p99
- Contagem de retries e volume de dead-letter
- Utilização dos workers
Lidando com escala: dedupe, cache e limites de taxa
Make email status explicit
Return clear status results like valid invalid risky unknown for predictable state transitions.
Alto tráfego geralmente falha de formas banais: o mesmo endereço é validado repetidamente, workers se acumulam e uma dependência lenta faz tudo parecer quebrado. O objetivo é tornar a validação barata durante rajadas, mantendo resultados razoavelmente frescos.
Dedupe durante picos. Normalize chaves (lowercase, trim) para que [email protected] e [email protected] mapeiem juntos. Adicione uma pequena “janela de dedupe” antes de enfileirar (ou no início do worker) para que o mesmo e-mail não seja validado 20 vezes em um minuto.
Cache por pouco tempo. Cache não é para manter resultados para sempre. É para evitar trabalho repetido durante picos. Cacheie resultados positivos e negativos, mas expire rápido.
Um ponto de partida simples:
- Cache de “valid”: 1 a 24 horas
- Cache de “invalid/disposable”: 5 a 60 minutos
- Cache de “unknown/timeout”: 1 a 5 minutos
Limites de taxa e prioridades. Proteja cada dependência downstream com um rate limit. Durante picos, priorize validações que desbloqueiam ações de maior risco, como reset de senha, pagamentos ou convite de colegas. Deixe checagens de baixa prioridade (inscrições em newsletter) aguardarem um pouco.
Erros comuns que causam lentidão e bugs
Marcar usuários verificados cedo demais
Definir email_verified = true quando você enfileira a checagem transforma “vamos checar” em “checamos”. Se a fila enfileirar, você acaba concedendo acesso total a endereços que nunca foram validados.
Transições de estado vagas ou ausentes
Se você só tem pending e verified, contas podem ficar presas quando provedores expiram. Use estados claros como pending, valid, invalid, risky e unknown, e torne cada transição intencional.
Handlers de webhook não idempotentes
Webhooks podem chegar duas vezes. Se seu handler cria um novo job a cada chegada, um usuário pode acionar dez validações e dez atualizações. Chaveie atualizações por um id de evento ou request estável e ignore repetições.
Vazamento de detalhes sensíveis
Não registre e-mails completos nem exponha detalhes como “spam trap” ou “provedor descartável” ao cliente. Masque logs e retorne resultados simples.
Bloquear ações chave sem um plano
Se você bloquear login ou compras até a validação assíncrona terminar, você recria o problema original de cadastro lento. Acesso limitado com mensagens claras costuma funcionar melhor.
Checklist rápido antes do deploy
Maintain a healthier email list
Validate new signups and updates so your CRM and lifecycle emails stay cleaner.
Teste o pior dia, não o dia médio. Simule validação lenta, timeouts e um pico de tráfego repentino, então confirme que o cadastro continua responsivo e seu backlog drena com segurança.
- O cadastro retorna rápido mesmo quando a validação está atrasada (conta é criada com um estado claro
pending). - Uma fonte única da verdade para status de validação (não flags espalhadas entre serviços).
- Retries definidos e limitados, com tratamento de dead-letter.
- Endpoints de webhook (se usados) seguros e idempotentes.
- Dashboards e alertas para falhas, timeouts e backlog de filas.
Próximos passos: implante com segurança e mantenha os dados limpos
Comece pequeno e mantenha o sistema previsível. Combine-se em um conjunto curto de statuses (por exemplo pending, valid, invalid, unknown) e faça um único caminho de job em background ser o lugar que altera esses estados.
Só adicione um consumidor de webhook quando você realmente precisar notificar outros sistemas em quase tempo real. Se sua app for a única consumidora, ler o status mais recente do seu próprio banco de dados costuma ser mais simples.
Antes de escrever código, documente suas regras de retry e dedupe: o que conta como o mesmo evento, quanto tempo você tenta e o que acontece depois que desiste. Isso previne duplicações misteriosas e loops acidentais no futuro.
Se quiser terceirizar checagens mais profundas, Verimail (verimail.co) é uma API de validação de e-mails projetada para proteção de cadastros, com checagens de sintaxe, verificação de domínio e MX, detecção de provedores descartáveis e matching em blocklists em uma única chamada. Mesmo com um validador rápido, manter a chamada em um worker em vez de na requisição de cadastro é o que protege seu fluxo durante picos.
Perguntas Frequentes
Why does synchronous email validation make signups slow under high traffic?
A validação síncrona faz a requisição de cadastro esperar por chamadas de rede externas, como consultas DNS e verificações MX. Em picos de tráfego, um pequeno número de consultas lentas pode se acumular, ocupar threads de trabalho e levar o endpoint inteiro a timeouts.
What should I validate immediately vs in the background?
Faça apenas checagens baratas e locais que não possam expirar: campos obrigatórios, formato básico do e-mail, remoção de espaços óbvios e controles simples de abuso que você já tem em memória. Deixe checagens mais profundas, como MX, detecção de provedores descartáveis e matching em blocklists, para o processo em segundo plano.
What’s the simplest async flow to implement?
Crie a conta imediatamente, defina explicitamente email_status = pending e enfileire um job de validação vinculado ao usuário e ao valor atual do e-mail. Quando o worker terminar, atualize o status e registre um código de motivo para que a aplicação possa reagir de forma consistente.
Which email validation states should I store?
Armazene um pequeno conjunto de estados que você pode usar para controlar acesso: pending, valid, risky, invalid e unknown. Unknown é importante para timeouts e erros de provedores, para que contas não fiquem presas em um estado ‘verificado’ falso.
What can a user do while their email is still pending?
Permita que o usuário realize ações de baixo risco enquanto o e-mail estiver pendente e bloqueie ou atrase ações de alto valor até que esteja valid. Ações comumente controladas incluem convites para times, trials, pagamentos/payouts e fluxos de redefinição de senha.
What should I store besides “valid/invalid”?
Armazene um pacote compacto de “fatos”: e-mail normalizado, domínio, status, timestamp, nome do provedor, código de motivo e um contador de tentativas. Isso facilita o suporte e evita reexecuções desnecessárias só para explicar uma decisão.
How should retries and failures work in an async validation pipeline?
Reenvie timeouts e erros 5xx com backoff e um limite rígido para não ficar tentando indefinidamente. Se as tentativas se esgotarem, marque o e-mail como unknown, mova o job para uma dead-letter queue e mantenha a conta limitada até que seja possível rechecá-lo.
How do I make webhook handlers and jobs idempotent?
Presuma que ocorrerão duplicatas e torne as atualizações seguras para aplicar mais de uma vez. Use uma chave de deduplicação estável como (user_id, validation_attempt) ou um request/event id, e ignore resultados tardios que não correspondam ao e-mail atual do usuário.
How do I secure webhook-style “push” validation results?
Exija HTTPS, verifique uma assinatura com um segredo compartilhado e rejeite callbacks com timestamp muito antigo. Registre também event ids vistos por um curto período para que requisições replay não sobrescrevam estado ou disparem trabalho extra.
How do I reduce repeated validations during spikes?
Normalize emails consistentemente (trim e lowercase) e adicione uma pequena janela de dedupe para que o mesmo endereço não seja validado muitas vezes durante um pico. Faça cache de resultados recentes por pouco tempo para reduzir consultas repetidas, mantendo TTLs curtos para não segurar respostas desatualizadas.