22 ene 2026·7 min
Limitación por tasa en la API de validación de correo: reintentos, backoff y circuit breakers
Gestiona la limitación por tasa en la API de validación de correos con reintentos seguros, backoff con jitter, idempotencia y circuit breakers para mantener los registros fiables.
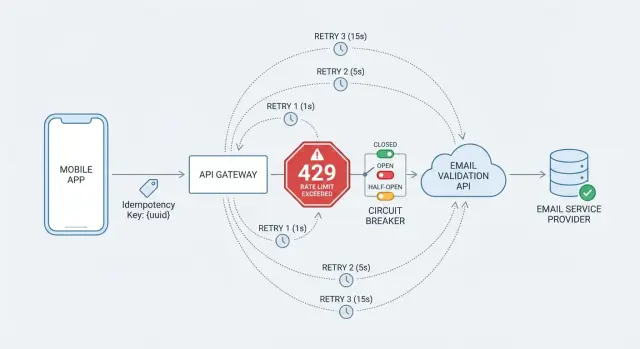
Cómo se ve la limitación por tasa en aplicaciones reales
La limitación por tasa es simple: una API limita cuántas solicitudes puedes enviar en una ventana corta. Los proveedores hacen esto para mantener el servicio estable, prevenir abusos y evitar que un cliente ruidoso consuma toda la capacidad compartida.
La mayoría de los equipos solo notan los límites durante picos: sale una campaña, un socio se lanza, o un bot empieza a golpear tu formulario de registro. Si validas correos durante el registro (por ejemplo, llamando a Verimail para bloquear direcciones desechables o inválidas), esos picos pueden llevarte por encima del umbral.
Para los usuarios, esto suele sentirse como que la app es inestable, no como “limitada por tasa”. Verás cosas como registros más lentos, errores aleatorios de “inténtalo de nuevo” que desaparecen al actualizar, correos de verificación que no llegan porque la dirección nunca fue aceptada, y tickets de soporte con síntomas inconsistentes.
La trampa es lo que ocurre después. Un cliente ingenuo ve una falla y reintenta inmediatamente, a veces con múltiples reintentos en paralelo. Bajo limitación por tasa, eso empeora el problema. Añades tráfico justo cuando la API te está pidiendo que reduzcas la velocidad, y un pequeño contratiempo puede convertirse en minutos de interrupción.
Un cliente resiliente asume que estos momentos pasarán y reacciona con calma: reduce la velocidad a propósito, reintenta solo cuando tiene sentido (y solo unas pocas veces), evita trabajo duplicado cuando la misma acción de usuario se reintenta y evita que una dependencia en problemas se convierta en un fallo en todo el sitio.
Los límites por tasa son normales. La diferencia entre un registro fluido y un incidente es mayormente cómo se comporta tu cliente después del primer 429.
Lee las señales: 429, Retry-After y timeouts
Cuando alcanzas un límite, el servidor te está dando una señal de control: estás enviando solicitudes más rápido de lo que quiere aceptar ahora. Trátalo como retroalimentación normal, no como un fallo genérico.
Las señales que verás con más frecuencia son:
- HTTP 429 (Too Many Requests)
- Timeouts de solicitud
- Errores de red como reinicios de conexión
Pueden parecer similares en los dashboards, pero requieren un manejo distinto.
429 y cabeceras útiles
Una respuesta 429 es el caso más claro porque es explícita. Si la API incluye una cabecera Retry-After, trátala como la mejor instrucción disponible sobre cuándo intentar de nuevo. Algunas APIs también incluyen pistas de cuota como solicitudes restantes o tiempo de reinicio, pero úsalas solo si están documentadas.
Una regla de decisión que te mantiene a salvo:
- 429 con
Retry-After: espera ese tiempo (más una pequeña jitter aleatoria), luego reintenta. - 429 sin
Retry-After: reintenta con backoff exponencial y jitter, con un límite estricto de espera total. - 429s repetidos: deja de reintentar y falla rápido por un período corto (un circuito abierto ayuda aquí).
Timeouts y errores de conexión
Los timeouts y errores de conexión generalmente indican sobrecarga, redes inestables o una mala configuración del cliente. A diferencia del 429, puede que no haya un tiempo de espera “correcto”. Reintentar puede ayudar, pero solo con límites estrictos.
Registra eventos de limitación por tasa por separado de otros errores. Un 429 no es lo mismo que “correo inválido” o “API caída”. Si los mezclas, afinarás mal los reintentos y perderás tiempo buscando la causa equivocada.
En un flujo de registro que llama a una API como Verimail, planifica una alternativa elegante. Si la validación está bloqueada temporalmente, puedes ponerla en cola para más tarde, mostrar un mensaje claro o aceptar el correo y verificarlo después. La elección correcta depende de si la validación es una puerta obligatoria o solo una comprobación de calidad.
Define metas antes de añadir reintentos
Los reintentos parecen inofensivos: si una solicitud falla, intenta de nuevo. En la práctica, los reintentos afectan la velocidad del registro, la calidad de los datos y la presión que pones sobre el proveedor.
Decide qué significa “éxito” para tu formulario. Durante el registro, la mayoría de los equipos prefieren una experiencia rápida y predecible sobre una certeza perfecta. Si la validación es lenta o está limitada por tasa, quizá aceptes el correo y lo verifiques después en lugar de bloquear al usuario.
Antes de cambiar código, escribe algunas reglas:
- Experiencia de usuario: ¿Cuánto tiempo puede añadir la validación (por ejemplo, 200–500 ms) y qué ocurre cuando se agota ese presupuesto?
- Seguridad: ¿Qué acciones nunca deben ocurrir dos veces (crear cuentas, enviar correos de bienvenida, iniciar pruebas)?
- Carga: ¿Cuántos intentos de reintento están permitidos y cuál es el tiempo máximo total dedicado a reintentos?
- Soporte: ¿Qué verá soporte en los logs y puede explicárselo a un cliente?
- Fallback: ¿Cuál es el comportamiento seguro bajo presión (bloquear, permitir o poner en cola)?
Estas metas te evitan reintentar para siempre, lo que a menudo convierte un pico breve en una caída más larga.
Ejemplo: tu formulario de registro llama a Verimail para filtrar correos desechables. Si la API se enlentece, tu regla podría ser “nunca retrasar el registro más de 1 segundo”. Eso apunta a un timeout corto, uno o dos reintentos como máximo y luego un fallback (como aceptar el correo pero marcarlo para revisión posterior).
Paso a paso: implementar backoff y jitter
Los reintentos solo ayudan cuando están controlados. Si reintentas demasiado rápido o durante demasiado tiempo, puedes transformar una pequeña ralentización en un problema mayor.
1) Define primero un presupuesto pequeño
Elige dos límites: un recuento máximo de reintentos y un presupuesto total de tiempo. El presupuesto de tiempo importa más porque el backoff crece rápido.
Para una verificación interactiva en el registro, un punto de partida práctico son 2–3 reintentos dentro de 1–2 segundos en total. Para tareas en segundo plano, puedes permitir más tiempo porque el usuario no está esperando.
2) Usa backoff exponencial y añade jitter
El backoff exponencial significa esperar más tiempo tras cada fallo. El jitter aleatoriza esa espera para que miles de clientes no reintenten al mismo tiempo.
Un patrón simple:
- Intenta la solicitud.
- Si falla con un error reintentable (como 429 o un timeout transitorio), calcula el siguiente retraso.
- Delay = min(maxDelay, baseDelay * 2^attempt) + random(0, jitterRange).
- Duerme, luego intenta de nuevo hasta agotar tu presupuesto de tiempo.
Si el servidor envía Retry-After, trátalo como un retraso mínimo. Si tu backoff dice 400 ms pero Retry-After dice 2 segundos, espera 2 segundos.
Si Verimail devuelve un 429 durante un pico repentino, respetar Retry-After más jitter ayuda a alisar el tráfico en vez de martillar la API.
3) Ajusta parámetros según la carga
No uses una política de reintentos única para todo. El tráfico de registro y los trabajos en segundo plano tienen objetivos distintos.
Manténlo simple:
- Interactivo (registro): pocos reintentos, presupuesto de tiempo ajustado, fallback rápido.
- Trabajos en segundo plano: más reintentos, presupuesto de tiempo mayor.
- Importaciones por lotes: ritmo sostenido para evitar picos.
La idea es mantener la experiencia de usuario ágil mientras eres cortés bajo carga.
Idempotencia y desduplicación para que los reintentos no creen duplicados
Test email checks under load
Try Verimail with 100 validations per month, no credit card required.
Los reintentos son más seguros cuando la llamada es de solo lectura. La validación de correo suele ser así: preguntas y recibes una respuesta. Aun así, las llamadas duplicadas siguen siendo dañinas. Desperdician cuota, añaden latencia y complican los logs cuando una acción de usuario dispara múltiples validaciones.
Si tu proveedor soporta claves de idempotencia, úsalas para cualquier endpoint que pueda tener efectos secundarios (por ejemplo, flujos de “validar y almacenar”). Una clave de idempotencia puede ser un UUID por acción de usuario o una huella estable como un hash del correo normalizado más una ventana temporal. Si no hay soporte, aún puedes obtener la mayor parte del beneficio en el cliente.
Un enfoque práctico combina tres capas:
- Normaliza y crea una huella del correo (trim, lowercase, eliminar espacios obvios) para que la misma entrada dé la misma clave.
- Mantén una caché de corta duración (a menudo 1–10 minutos) para que comprobaciones repetidas no llamen de nuevo a la API.
- Desduplica solicitudes en vuelo: si varias partes de tu app validan el mismo correo a la vez, deben esperar la misma promesa, no lanzar múltiples llamadas de red.
Ten cuidado qué cacheas. Resultados “válido” e “inválido” suelen ser seguros para reusar brevemente. Fallos temporales no lo son. Si recibes un timeout, un 429 o una respuesta “desconocida”, cachea por segundos (o no lo hagas) para no fijar un resultado malo.
Ejemplo: durante un pico, un usuario hace doble clic en “Crear cuenta” y el frontend también lanza una comprobación en segundo plano. Con fingerprinting y desduplicación en vuelo, aún haces una sola llamada a Verimail, y los reintentos no multiplican el tráfico.
Saber cuándo reintentar y cuándo fallar
Los reintentos ayudan cuando el problema es temporal. Dañan cuando la solicitud nunca va a tener éxito.
Reintenta solo cuando un nuevo intento pueda funcionar. Eso suele incluir respuestas 429, timeouts de red, reinicios de conexión y muchos errores 5xx de corta duración. Si obtienes un 429, respeta Retry-After cuando esté presente.
No reintentes solicitudes malas. Si la API dice que tu payload es inválido, faltan parámetros o la autenticación es incorrecta, reintentar solo repite el mismo error.
Un filtro de decisión simple:
- Reintentar: 429, timeouts, reinicios de conexión, 5xx (salvo casos que sabes permanentes)
- Fallar rápido: validación de entrada 4xx, 401/403 errores de auth, campos requeridos faltantes
- Dejar de reintentar cuando se agote tu presupuesto total de espera (por ejemplo, 2–3 segundos para el registro)
A veces el mejor resultado es “continuar sin una respuesta validada”. Durante un pico, quizá permitas que el registro termine, guardes una bandera como email_status = needs_review y pongas en cola una revalidación en segundo plano.
Sé explícito sobre fallos parciales. Si la validación se omite, guarda lo que pasó (código de error, timestamp, recuento de reintentos) y evita tratar el correo como “verificado” más adelante.
Añade un circuito (circuit breaker) para evitar fallos en cascada
Los reintentos ayudan cuando una caída es breve. Pero si la API de validación está lenta o fallando durante minutos, los reintentos se acumulan y pueden arrastrar todo tu flujo de registro. Un circuito evita llamar a la API cuando las fallas aumentan para que tu app siga siendo responsiva.
Un breaker tiene tres estados:
- Cerrado: las llamadas pasan con normalidad.
- Abierto: dejas de llamar a la API por un período de enfriamiento porque las llamadas recientes fallaron con frecuencia.
- Semi-abierto: permites algunas llamadas de prueba. Si tienen éxito, cierras el breaker. Si fallan, lo vuelves a abrir.
Umbrales iniciales que funcionan para muchos equipos:
- Abrir tras 5–10 fallos consecutivos, o un 50% de fallos sobre las últimas 20–50 llamadas
- Tiempo de enfriamiento de 15–60 segundos
- En semi-abierto, permitir 1–5 llamadas de prueba antes de decidir
Cuando el breaker está abierto, decide qué hace tu app. Para el registro, podrías aceptar el correo pero marcarlo como “verificación pendiente” y validarlo más tarde. Para flujos de más riesgo, podrías mostrar un mensaje claro de que la comprobación está temporalmente indisponible.
La limitación por tasa y los circuit breakers resuelven problemas diferentes. La limitación por tasa es la API diciéndote que reduzcas la velocidad (a menudo con 429 y Retry-After). Un circuit breaker es tu cliente eligiendo pausar llamadas porque los resultados recientes muestran problemas, incluso si no estás siendo limitado por tasa.
Monitorización y ajuste que realmente ayudan
Keep your database clean
Protect your platform from low-quality leads with real-time blocklist matching.
Los reintentos y breakers solo funcionan si puedes ver lo que hacen.
Sigue un pequeño conjunto de métricas que explique la historia a lo largo del tiempo:
- Recuento de reintentos por solicitud (y % de solicitudes que reintentan)
- Tiempo total de backoff añadido por solicitud
- Tasa de 429 (y con qué frecuencia aparece
Retry-After) - Tasa de éxito (2xx) y tasa de fallo duro (4xx no reintentados)
- Latencia de extremo a extremo (p50/p95) para la validación, incluyendo reintentos
El logging importa tanto como los gráficos. Para cada intento de validación, registra un request ID y el resultado final. Si la API devuelve su propio request ID, guárdalo también. Mantén los logs seguros para la privacidad: hashea el correo y aún así podrás depurar duplicados.
Las alertas deben enfocarse en cambios sostenidos, no en ruido normal. Un puñado de 429s durante una hora ocupada puede estar bien. Un pico que dura 10 minutos suele significar que los patrones de tráfico cambiaron, los reintentos son demasiado agresivos o el breaker se queda abierto.
También prueba bajo carga. Simula registros con ráfagas y redes lentas, no solo llamadas en el camino feliz. Aunque tu proveedor normalmente responda en milisegundos, tus timeouts y límites de reintento deben asumir que Internet puede fallar.
Si puedes, haz que los ajustes clave sean modificables sin redeploy: max retries, base backoff, timeout y umbrales del breaker. Eso facilita calmar la situación rápidamente durante picos.
Ejemplo: pico de tráfico durante registros
Una campaña pagada impacta y el tráfico de registros sube 10x en una hora. Tu app valida cada correo a la entrada, llamando a Verimail como parte del flujo de registro. Al principio todo parece bien, luego aparecen casos límite: más solicitudes concurrentes, timeouts ocasionales y algunos 429.
Sin protecciones, muchos clientes reintentan inmediatamente. Cuando cientos de solicitudes fallan a la vez, reintentan juntos. Eso crea un thundering herd y hace que la siguiente ola falle también, incluso si la API se habría recuperado con un poco de respiro.
Con backoff y jitter, los reintentos se reparten. Incluso un plan simple ayuda:
- Primer reintento tras unos 200–400 ms (aleatorizado)
- Segundo reintento tras unos 800–1200 ms
- Parar después de 2–3 reintentos para tráfico de registro
La idempotencia y la caché reducen aún más el volumen de llamadas. Durante picos, la misma dirección a menudo se envía dos veces (doble clics, reenvíos, usuarios en distintos dispositivos). Una ventana de caché corta (por ejemplo, 10–30 minutos) con clave por correo normalizado te permite responder repeticiones sin golpear la API otra vez. Combina eso con una clave de idempotencia para la acción de registro para que un reintento no cree registros duplicados.
Un circuito mantiene tu sitio responsivo cuando las fallas se acumulan. Si 429s y timeouts cruzan un umbral, abre el breaker por una ventana corta y omite las llamadas de validación temporalmente. El registro puede seguir marcando el correo como “verificación pendiente” y validar en segundo plano cuando el breaker se cierre.
Lista rápida antes de lanzar
Validate emails the right way
Add RFC syntax, domain, MX, and disposable checks in one API call.
Antes de activar reintentos en producción, define qué significa “buen comportamiento” bajo carga. El objetivo es mantener los registros en movimiento y evitar convertir una breve ralentización en una interrupción mayor.
- Honra
Retry-Aftery limita el tiempo de reintento. SigueRetry-Aftercuando esté presente y fija un límite duro en el tiempo total de reintento para que una solicitud no atrape tu sistema. - No reintentes errores que causaste. Si la API devuelve un 4xx claro por entrada inválida, reintentar es una pérdida de tiempo. Corrige la entrada y devuelve un mensaje útil.
- Desduplica búsquedas repetidas. Añade una ventana de caché corta para que repeticiones reutilicen el primer resultado.
- Fija reglas del breaker y un fallback. Elige umbrales y decide qué pasa cuando el breaker se abre (aceptar y marcar, poner en cola para más tarde o bloquear flujos de alto riesgo).
- Haz que los fallos sean fáciles de depurar. Registra el resultado (éxito, 429, timeout), recuento de reintentos, tiempo total de espera y si el breaker estaba abierto.
Simula un pequeño pico de tráfico en staging y confirma que el servicio sigue responsivo mientras el cliente reduce la velocidad educadamente. Si usas Verimail u otro proveedor similar, el mismo patrón aplica: respeta las señales, mantiene los reintentos acotados y haz que la vía de “rendirse” sea predecible.
Próximos pasos: hacer de la resiliencia la opción por defecto
Trata el manejo de reintentos y límites por tasa como una característica de producto, no como un parche rápido. Empieza conservador, observa qué ocurre en producción y ajusta según las métricas. Los equipos suelen tener problemas cuando los reintentos son demasiado agresivos y amplifican una ralentización.
Un plan práctico:
- Mantén los reintentos bajos (a menudo 2–3) con backoff exponencial y jitter, y respeta
Retry-After. - Añade desduplicación para cualquier flujo que pueda crear duplicados.
- Define reglas de parada: qué reintenta, qué falla rápido y cuándo caes en “intentar más tarde”.
- Escribe el comportamiento en lenguaje claro para producto y soporte (qué ve el usuario, qué se registra y cuándo se difiere la validación).
- Añade dashboards y alertas para 429s sostenidos, timeouts crecientes y tiempo con breaker abierto.
Si las comprobaciones de correo son críticas para el negocio, también ayuda usar un validador diseñado para baja latencia y alto volumen. Verimail (verimail.co) realiza comprobaciones de sintaxis RFC, verificación de dominio y MX y coincidencias en listas de bloqueo/desechables en una sola llamada API, lo que reduce cuántas veces tu cliente cae en la vía de “reintento”.
Programa revisiones periódicas a medida que cambian los patrones de tráfico. Reevalúa umbrales, actualiza cómo manejas dominios desechables y confirma que el comportamiento frente a límites por tasa aún coincide con el comportamiento real de usuarios y las necesidades de soporte.
Preguntas frecuentes
What does rate limiting usually look like to my users?
Start by assuming it’s normal and temporary, not a mystery outage. Treat HTTP 429 as a clear “slow down” signal, stop immediate retries, and switch to a controlled retry plan that respects Retry-After when present.
What should I do when the API returns HTTP 429?
A 429 Too Many Requests means the server is explicitly asking you to reduce request rate. If Retry-After is included, wait at least that long (plus a small random jitter) before trying again so you don’t create another synchronized spike.
How should I handle timeouts differently than 429s?
A timeout is ambiguous: it could be overload, a network hiccup, or an overly aggressive client timeout. Retry only a small number of times with backoff, and keep a strict total time budget so the signup flow stays predictable.
Why do I need both backoff and jitter?
Exponential backoff spreads retries out over time, and jitter adds randomness so many clients don’t retry at the same moment. A simple default is to double the delay each attempt and add a small random amount, stopping once you hit your retry count or time budget.
How many retries should I allow during signup?
For interactive signup validation, a good default is 2–3 retries within about 1–2 seconds total, then fall back. The goal is to avoid turning a brief spike into a long slowdown while keeping the form responsive.
What’s the safest fallback if email validation is rate limited?
Use a safe fallback that matches your risk level. Common options are accepting the email and marking it for later recheck, queueing validation for background processing, or showing a clear message that validation is temporarily unavailable; pick one and make it consistent.
How do I prevent duplicate validation calls when users retry or double-click?
Deduplicate at three levels: normalize the email (trim and lowercase), cache recent results for a short window so repeats don’t call again, and dedupe in-flight requests so concurrent checks share the same promise. This cuts quota waste and reduces the chance you amplify a spike.
When should I add a circuit breaker, and what should it do?
A circuit breaker stops calling the dependency for a short cool-down when failures are frequent, so your app doesn’t keep piling load onto a struggling service. While it’s open, skip the API call and use your fallback behavior, then probe with a few trial calls before fully resuming.
Which errors should I retry, and which should I fail fast?
Retry only when a new attempt could succeed, like 429s, transient network errors, and many 5xx responses. Fail fast on errors that won’t change by retrying, like malformed requests, missing parameters, and auth problems such as 401/403.
What metrics should I monitor to tune retries and rate-limit handling?
Track how often you see 429s, how frequently Retry-After appears, how many requests retry, and how much backoff time you add, alongside p50/p95 latency. Logging the final outcome per validation (separately from “invalid email” results) helps you tune retries without guessing, especially when validating emails via Verimail during traffic spikes.