21 oct 2025·8 min
Métricas de calidad del correo para monitorear con el tiempo (y por qué)
Las métricas de calidad de correo muestran de dónde vienen los registros malos y cuánto cuestan. Haz seguimiento de inválidos, desechables y fallos de dominio/MX y relaciónalos con la activación.
Qué intentas medir realmente (en términos sencillos)
“La calidad del correo” es simple: ¿puedes contactar a esta persona y la dirección parece pertenecer a un usuario real e interesado?
En un formulario de registro o de leads, una dirección de alta calidad es aquella que puede recibir correo, no es desechable o temporal y parece de bajo riesgo (no es una trampa conocida ni un patrón que suele provocar quejas). No estás juzgando a la persona: estás evaluando si la dirección funcionará como un canal fiable.
Cuando la calidad baja, se nota rápido:
- Más rebotes, lo que puede dañar la reputación del remitente y la entregabilidad
- Menor activación porque los usuarios nunca ven los correos de verificación o bienvenida
- Un CRM lleno de leads muertos que desperdician tiempo de seguimiento
- Analíticas ruidosas (parece que “los registros suben”, pero los usuarios reales no lo hacen)
Monitorear no es para tener gráficos bonitos. Es para detectar alertas tempranas y diagnosticar rápido. Las métricas útiles te dicen dos cosas: qué cambió y de dónde vino (una campaña, fuente de tráfico, país, formulario específico o un nuevo socio).
Ejemplo: lanzas una promo y los registros suben 30%. Una semana después, menos usuarios se activan. Si sigues la calidad del correo, podrías ver que las direcciones desechables se duplicaron en ese periodo, o que los fallos de dominio/MX se dispararon. Eso apunta a tráfico de bots, un campo de formulario roto o una fuente que atrae registros de baja intención.
Fija expectativas desde el principio: cada métrica debe mapearse a una acción. Si un número sube, ya deberías saber si eso significa endurecer la validación, ajustar una campaña, añadir fricción para tráfico sospechoso o investigar una caída puntual.
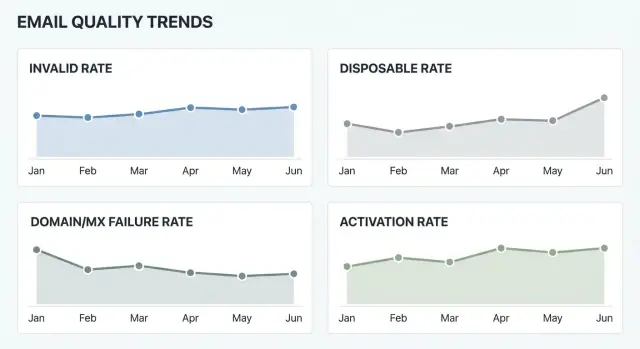
Métricas centrales: inválidos, desechables y fallos de dominio
Si quieres métricas que sigan siendo útiles en el tiempo, mantén las “tres centrales” simples y bien definidas. Estos números te dicen si estás recogiendo direcciones alcanzables y si el problema es comportamiento del usuario o infraestructura.
Tasa de inválidos es la proporción de registros cuya dirección no es usable. Como mínimo, cuenta fallos obvios como sintaxis incorrecta (falta @, caracteres no permitidos) y dominios que no existen. Si además mides alcanzabilidad del buzón, ten cuidado con la interpretación: “buzón inalcanzable” puede significar un buzón realmente inválido, pero también un bloqueo temporal, greylisting o un proveedor que limita las comprobaciones.
Tasa de desechables es la proporción de registros provenientes de proveedores de correo desechable (servicios de bandeja de un solo uso). Estas direcciones suelen correlacionar con cuentas falsas, menor activación, mayor riesgo de fraude y peor entregabilidad a futuro. Una dirección desechable puede ser técnicamente “válida”, por eso esta métrica debe analizarse por separado.
Tasa de fallos de dominio y MX captura problemas que ocurren antes de llegar al buzón: el dominio falta, DNS no se resuelve o el dominio no tiene registros MX (por lo que no puede recibir correo). Si puedes, registra por separado los fallos DNS temporales, porque suelen subir durante incidencias.
Una configuración práctica usa algunos buckets estables de resultado. Muchos equipos empiezan con:
- Válido
- Inválido
- Desechable
- Desconocido
El desconocido es tu sistema de alerta temprana. Abarca timeouts, bloqueos de proveedores y resultados ambiguos que no deberían forzarse a “válido” o “inválido”. Sea cual sea la herramienta, la consistencia importa más que una categorización perfecta: mantén definiciones estables y cámbialas solo anotando la fecha para que las tendencias sigan siendo comparables.
Cómo calcular las tasas para que no engañen
Las buenas métricas empiezan con una decisión aburrida: elegir un denominador consistente. Para el monitoreo de registros, usa el total de registros como base para que cada tasa responda: “De todos los que intentaron unirse, ¿cuántos tuvieron este problema?”
Fórmulas que puedes reutilizar (por día o por semana):
- Invalid email rate = invalid_results / total_signups
- Disposable email rate = disposable_results / total_signups
- Domain and MX failure rate = domain_or_mx_fail_results / total_signups
- Validation coverage rate = validated_signups / total_signups
Además de las tasas, sigue los conteos. Las tasas solas pueden engañar cuando el volumen es pequeño. Si tuviste 20 registros un domingo y 2 fueron inválidos, eso es 10%, pero podría ser ruido. Los conteos te dicen si estás viendo un cambio real.
Para reportes, usa vistas diarias y semanales. Lo diario te ayuda a detectar cambios súbitos (como el lanzamiento de una campaña). Lo semanal suaviza las oscilaciones diarias. Una vista móvil de 7 días es un buen punto intermedio.
Las comprobaciones de dominio y DNS necesitan una regla extra: reintentos. A veces una búsqueda de dominio falla por un problema temporal de resolvers, no porque el correo sea malo. Decide qué quieres medir y etiquétalo claramente:
- Tasa de fallo en primer intento (detecta rápido problemas de infraestructura o de resolución)
- Tasa de fallo final tras reintentos (más cercana a la alcanzabilidad real)
Finalmente, guarda el código de resultado bruto de la validación, no solo aprobado/fallado. Si conservas la razón (syntax_error, no_mx, disposable_provider, blocked, timeout, etc.), podrás explicar cambios después y segmentar con precisión.
Paso a paso: configurar el monitoreo desde el registro hasta el panel
Empieza decidiendo dónde ocurren las comprobaciones. Muchos equipos hacen una verificación rápida de formato en el formulario para atrapar errores tipográficos y luego ejecutan la decisión real en el servidor para que no se pueda eludir.
Después, registra el resultado de cada intento, incluso los que bloqueas. Los intentos bloqueados siguen informando sobre ataques, fuentes de marketing rotas y fricciones de UX.
Una configuración simple que funciona para la mayoría de productos:
- Validar en el registro (y en los flujos de cambio de correo).
- Almacenar timestamp, ID de usuario/sesión, fuente del registro (campaña/referrer/app) y el dominio del correo.
- Guardar el resultado de la validación más un código corto de razón (syntax, disposable, MX missing, domain not found, blocklisted, timeout).
- Mapear resultados en buckets estables que mantendrás a largo plazo: válido, inválido, desechable, fallo de dominio, desconocido.
- Agregar en una tabla diaria y graficar cada tasa como una línea de tendencia.
La consistencia es la diferencia entre un panel en el que confías y uno que ignoras. Mantén los buckets centrales estables incluso si tu validador añade nuevos códigos de razón después. Siempre puedes crear un desglose secundario, pero las líneas de tendencia principales no deben cambiar de definición cada mes.
Para el panel, un gráfico por tasa es suficiente al principio. Añade una pequeña tabla bajo cada gráfico con conteos diarios para ver si un pico es real o solo bajo volumen.
Construye un hábito semanal: cuando aparezca un pico, anota qué cambió (nueva campaña, nuevo país, cambio de copy, nueva fuente de tráfico, actualización de la configuración de validación). Si la tasa de desechables sube justo después de lanzar una promoción, puede ser esperado; la decisión real es bloquear, advertir o permitir pero etiquetar esos registros.
Segmentación: encuentra de dónde vienen realmente los correos malos
Si solo sigues un número global, te perderás la causa. Los correos malos rara vez están repartidos de forma uniforme. La segmentación convierte las métricas de calidad en acciones concretas.
Empieza con “¿de dónde vino este registro?” y desglosa las tasas por un conjunto pequeño de fuentes que confíes. Un primer paso simple:
- Canal de adquisición (ads, SEO, partners, referencias, importaciones de ventas)
- Superficie de registro (lista de espera, prueba, newsletter, contactar ventas)
- Geografía o idioma (solo cuando los volúmenes sean suficientemente grandes)
- Usuarios nuevos vs recurrentes (si puedes distinguirlos)
Mantén los grupos lo bastante grandes para que tengan sentido. Un país con 12 registros puede oscilar de 0% a 25% de inválidos de un día para otro y no significar nada. Fija un tamaño mínimo de muestra (por ejemplo, 100 registros) antes de tratar un segmento como señal.
Un ejemplo práctico: ves un pico semanal en la tasa de desechables. El gráfico global parece alarmante, pero la segmentación muestra que proviene casi en su totalidad de una campaña de un socio que manda tráfico a un formulario de newsletter. Ahora sabes qué hacer: revisar las protecciones de ese formulario, ajustar la campaña o requerir un paso extra para esa ruta.
También vigila bots. Suelen golpear una superficie concreta (a menudo el formulario más simple) y crear subidas repentinas. Pistas incluyen un aumento brusco desde un único referrer, una tasa muy alta de fallos de dominio/MX en un formulario, ráfagas de registros en horas extrañas o tráfico desde geografías que no coinciden con tu audiencia.
Vincula la calidad del correo con la activación y otros resultados downstream
Detecta fallos de dominio rápido
Detecta problemas de DNS y MX temprano con resultados de validación consistentes.
La calidad del correo no es solo entregabilidad. Cambia lo que ocurre tras el registro: si la gente completa la incorporación, confirma su correo y vuelve. Si un porcentaje de registros usa direcciones inválidas o desechables, tus métricas de producto pueden empeorar aunque el producto no haya cambiado.
Una forma práctica de verlo es seguir la tasa de activación por cohorte de registro (cada día o semana) y comparar cohortes con distintos niveles de calidad de correo. Cuando una cohorte tiene más inválidos o desechables, comprueba si la activación baja en esa misma cohorte. Ahí la calidad del correo se convierte en una señal de negocio, no solo en un detalle de mail ops.
Resultados downstream que merece la pena seguir
Selecciona algunos hitos importantes para tu producto y desglósalos por segmento de calidad de correo (válido vs inválido, desechable vs no desechable, fallos de dominio/MX):
- Tasa de completación de la verificación por correo
- Tasa de primer inicio de sesión en 24–72 horas
- Primera acción clave (tu momento “aha”)
- Tasa de prueba a pago (o lead a reunión)
- Tasa de contactos a soporte por cada 1.000 registros
Una forma simple de estimar el coste
Aunque sea aproximado, ayuda: tickets de soporte extra, seguimientos de ventas adicionales, sobrecarga de reenvíos/verificaciones y el coste blando del riesgo reputacional por rebotes. Si un 2% más de registros son inválidos y cada registro malo cuesta 3 minutos de soporte, puedes convertir ese porcentaje en horas y dólares rápido.
Una advertencia: correlación no siempre es causalidad. Estacionalidad, una nueva fuente de tráfico o un cambio en la UI pueden mover la activación y la calidad del correo al mismo tiempo. Aun así, patrones repetidos entre cohortes suelen ser suficientes para guiar la investigación.
Alertas y umbrales que desencadenan la respuesta correcta
Las alertas deben detectar problemas reales, no ruido normal. Empieza aprendiendo tu línea base de las últimas 2 a 4 semanas: cómo es lo “normal” para tasa de inválidos, tasa de desechables y tasa de fallos de dominio/MX. Luego fija umbrales que se ajusten a tu tráfico.
Una regla práctica es “2x lo normal”, pero solo cuando el volumen es lo bastante alto. Si las desechables suelen estar en 1%, una alerta en 2% puede ser útil, pero solo después de al menos 200 registros en la ventana.
Usa disparadores relativos y absolutos para que las métricas no confundan:
- Pico relativo: la tasa es 2x (o 1.5x) tu línea base
- Piso absoluto: la tasa está por encima de un número fijo (por ejemplo, >3%)
- Volumen mínimo: al menos N registros (elige N según tu tráfico)
- Duración mínima: sostenido durante 30–60 minutos (o 1 día completo para bajo volumen)
Mantén alertas separadas por tipo de fallo porque el responsable y la solución suelen ser distintos. Un pico de desechables suele apuntar a abuso, una campaña con incentivos o una ola de bots. Un pico de fallos de dominio/MX suele indicar un bug en el formulario, un patrón de autocompletado malo o un problema DNS temporal.
Cuando una alerta se dispara, escribe una nota de incidente corta:
- Qué cambió (release, campaña, fuente de tráfico, país)
- Qué métrica se movió y cuánto
- Qué segmento la impulsó (canal, formulario, cohorte)
- Qué hiciste (bloqueaste, ajustaste UI, endureciste validación)
- Resultado tras el cambio
Decide la responsabilidad por adelantado. Marketing ops suele encargarse de picos relacionados con campañas, producto de problemas de formulario y UX, e ingeniería de la lógica de validación e integraciones.
Leer los patrones: qué suele significar cada pico
Protégete contra emails trampa
Reduce el riesgo de trampas spam con coincidencias a listas de bloqueo en tiempo real durante el registro.
Semana a semana, es en los picos donde más aprendes. Suelen señalar una causa concreta.
Pico en la tasa de inválidos suele venir de abuso de formularios (bots), errores tipográficos o un cambio en la UI como una máscara de entrada rota.
Acción rápida: revisa cambios recientes en el formulario y haz unos registros reales desde móvil y escritorio.
Seguimiento más profundo: compara inválidos por fuente (landing, dispositivo, país, campaña) y revisa logs de servidor buscando ráfagas tipo bot.
Pico en la tasa de desechables es común tras añadir un incentivo (cupón, prueba gratuita) o comprar tráfico. También puede señalar visitantes de baja intención que prueban tu producto.
Acción rápida: endurece las reglas alrededor de la oferta (códigos de un solo uso, límites de tasa, controles anti-bot más fuertes).
Seguimiento más profundo: desglosa inscripciones desechables por canal y creativo, y decide si bloquear, advertir o requerir un paso extra para segmentos riesgosos.
Pico en la tasa de fallos de dominio/MX suele indicar problemas de resolución DNS, una caída temporal en un proveedor importante o un cambio de red en tu lado.
Acción rápida: vuelve a probar una muestra de dominios fallidos unos minutos después y desde otra red.
Seguimiento más profundo: comprueba la salud del resolver DNS y timeouts.
Crecimiento de la categoría “desconocido” normalmente significa que tu integración está agotando tiempos, no está registrando campos o no clasifica un patrón nuevo.
Acción rápida: verifica que las respuestas de la API se registran y almacenan correctamente de extremo a extremo.
Seguimiento más profundo: audita timeouts, reintentos y cómo mapeas códigos de razón a buckets.
Una buena regla: si un pico coincide con un cambio de producto, sospecha primero del formulario. Si coincide con un cambio de tráfico, sospecha intención y abuso.
Errores comunes que hacen inútiles las métricas
La mayoría de los paneles fallan por razones aburridas: los números parecen precisos, pero los datos están sucios. Cada gráfico debe responder a una pregunta clara y seguir siendo comparable semana a semana.
Una forma rápida de romper tus tasas es contar intentos en vez de personas. Los registros suelen incluir reintentos (typos, botón atrás, reenvíos, timeouts móviles). Si cuentas cada intento, tu tasa de inválidos puede subir aunque los mismos usuarios finalmente corrijan su dirección. Decide una unidad (usuario único, email único o sesión de registro única) y elimina duplicados antes de calcular las tasas.
Otra trampa es cambiar definiciones a mitad de camino. Si “desechable” se amplía para incluir más proveedores, o “inválido” pasa de solo sintaxis a sintaxis más comprobación de dominio, tu línea de tendencia mostrará un pico falso. Congela definiciones, versiona y mantiene un registro de cambios simple.
Errores comunes que envenenan los resultados:
- Mezclar intentos y registros únicos sin una deduplicación clara
- Cambiar silenciosamente qué cuenta como inválido o desechable y luego comparar meses
- Observar solo totales y perder el canal que genera la mayoría de correos malos
- Bloquear con demasiada agresividad para subir la “tasa válida” y luego reducir conversiones reales
- Tratar timeouts DNS temporales como fallos permanentes en lugar de reintentar o separarlos
Ejemplo: una campaña trae registros de una región. Las búsquedas DNS son más lentas allí por unas horas, así que las comprobaciones de dominio agotan tiempo. Si etiquetas eso como fallos duros, tu tasa de fallos de dominio sube y puedes bloquear usuarios buenos. Si haces seguimiento de timeouts por separado y reintentas, el pico se convierte en un problema de rendimiento, no en una crisis de calidad de correo.
Ejemplo: diagnosticar una caída de calidad de registros en una semana
Un equipo SaaS nota algo raro un lunes: las pruebas gratis suben 30% tras una nueva campaña promo, pero la tasa de desechables salta del 4% al 18%. Dos días después, aumentan los tickets de soporte porque la gente “nunca recibió el correo de bienvenida” y ventas se queja de que los leads parecen de baja intención.
Primero, confirma que es real y no un fallo de tracking. Compara la última semana con el promedio móvil de las cuatro semanas previas, usando la misma definición y denominador. Si las métricas se calculan por intento de registro, cambios en el comportamiento de reintento pueden ocultar (o exagerar) el problema. Decide si monitorizas por intento, por registro aceptado o por usuario único, y mantente fiel a ello.
Luego segmenta para encontrar el origen. Desglosar por fuente muestra que el pico proviene casi en su totalidad de PromoA (un cupón publicado en un foro de ofertas). Orgánico y referidos de partners no cambian. La tasa de fallos de dominio/MX se mantiene estable, lo que sugiere que no es una caída DNS ni un bug de formulario. Es mayormente proveedores desechables.
Una comprobación simple de causa raíz:
- Compara la tasa de desechables por campaña, no solo el global
- Revisa la tasa de activación de la cohorte nueva vs la cohorte de la semana anterior
- Revisa una pequeña muestra de direcciones (sin almacenar más de lo necesario)
- Confirma que el sistema clasifica los mismos dominios de forma consistente
- Alinea el objetivo: más pruebas, más activaciones o ambos
Luego viene la decisión. El equipo elige una respuesta escalonada: bloquear los dominios desechables más comunes y añadir verificación de correo solo para el tráfico de PromoA. La oferta sigue, pero el abuso se reduce.
En una semana, la tasa de desechables baja a 6% para PromoA, la activación mejora del 9% al 14% y la carga de soporte vuelve a la normalidad. Documentan una nota corta antes/después (métricas, fechas y el cambio exacto) para que la próxima alerta lleve a una respuesta confiada.
Lista rápida para un dashboard sano de calidad de correo
Mejora tu panel de calidad
Valida cada registro y guarda códigos de resultado para métricas en las que puedas confiar.
Un buen panel es aburrido la mayor parte del tiempo. Cuando algo cambia, puedes decir rápido qué cambió y dónde empezó.
Fija una línea base de las últimas 4 a 8 semanas. Es lo bastante larga para suavizar ruido, pero lo bastante corta para reflejar el tráfico actual y tu flujo de registro.
Comprueba tu configuración:
- Sigues inválidos, desechables, fallos de dominio/MX y desconocidos como resultados separados (no una tasa única mezclada).
- Cada gráfico puede dividirse por fuente de adquisición y por punto exacto de entrada (web, móvil, checkout, lista de espera).
- Revisión de activación (o primera acción importante) por cohorte de registro junto a las tasas de calidad de correo.
- Las alertas requieren tanto cambio de tasa como volumen mínimo.
- Puedes saltar de un pico a una muestra pequeña de ese segmento para detectar patrones rápido.
Asigna un responsable y un playbook. Cuando la tasa de desechables sube, ¿quién revisa campañas? Cuando aumentan fallos de dominio, ¿quién verifica si es una caída o un bug de formulario?
Próximos pasos: mejorar la calidad sin afectar registros
Empieza con un cambio que puedas mantener. Si añades logging, segmentación y alertas a la vez, no sabrás qué ayudó.
Elige la primera mejora según el problema que más te haga sentir dolor:
- Si discutís los números, mejora el logging primero.
- Si no sabes de dónde vienen los problemas, añade segmentación primero.
- Si encuentras problemas demasiado tarde, añade alertas primero.
Después, decide tu política para correos “malos” y “posiblemente malos”. Los inválidos y fallos duros de dominio/MX suelen ser seguros para bloquear porque rara vez se convierten en usuarios reales. Los desechables y fallos temporales son más delicados porque algunas personas reales los usan.
Una política simple que funciona para muchos productos: bloquear los inválidos obvios, advertir sobre desechables y reintentar fallos temporales (o pedir confirmación al usuario). Sea lo que sea, escríbelo para que soporte y producto respondan de forma coherente.
Luego ejecuta un pequeño experimento. Cambia una puerta (gate) para un segmento durante poco tiempo y observa calidad y resultados. Ejemplo: muestra una advertencia (no un bloqueo) para correos desechables en registros móviles durante una semana y compara la activación por cohorte con la semana anterior. Si la activación se mantiene y la tasa de desechables baja, mantenla. Si la activación baja, revierte.
Si quieres clasificación consistente en el registro, una API de validación puede ayudarte a etiquetar inválidos, desechables y resultados de dominio/MX de la misma forma en todos los formularios y servicios. Por ejemplo, Verimail ofrece una API de validación de una sola llamada con comprobaciones como sintaxis, verificación de dominio y MX, y coincidencia de proveedores desechables.
Fija una revisión mensual que termine con una decisión. Una página es suficiente: métricas principales, mayor cambio, qué intentaste, qué cambiarás el mes siguiente y qué no cambiarás.
Preguntas frecuentes
¿Qué significa realmente “calidad de correo” para los registros?
La calidad del correo significa que la dirección probablemente sea alcanzable y de bajo riesgo para tu producto. Un correo “bueno” puede recibir mensajes, no proviene de un proveedor desechable y no coincide con patrones que suelen causar rebotes o quejas.
¿Qué 3 métricas de calidad de correo debería seguir primero?
Empieza con tres métricas: tasa de inválidos, tasa de desechables y tasa de fallos de dominio/MX. Juntas te indican si los usuarios cometen errores tipográficos, si atraes inscripciones de baja intención y si problemas de infraestructura o DNS bloquean la entregabilidad.
¿Qué debo usar como denominador al calcular las tasas?
Usa intentos totales de registro como denominador por defecto, de modo que cada tasa responda “de todos los que intentaron registrarse, ¿cuántos tuvieron este problema?”. Mantén ese denominador consistente semana a semana para que las tendencias sean comparables.
¿Por qué necesito una categoría “desconocido”?
“Desconocido” es donde van los timeouts, bloqueos por proveedores y las comprobaciones ambiguas. Es útil porque señala problemas de integración y condiciones temporales que no debes etiquetar silenciosamente como válidas o inválidas.
¿Debo reintentar comprobaciones de dominio/MX o contar los fallos de inmediato?
Como las búsquedas DNS y de red pueden fallar temporalmente incluso cuando un correo es válido, una práctica común es seguir la tasa de fallos al primer intento (para detectar caídas de infraestructura rápidamente) y la tasa final tras reintentos (más cercana a la alcanzabilidad real).
¿Cómo averiguo de dónde vienen los correos malos?
Si solo miras un número global, perderás la causa. Segmenta por fuente de adquisición y por la superficie de registro primero; luego añade geografía o dispositivo solo cuando el tamaño de muestra sea suficiente para confiar en los resultados.
¿Cómo conecto la calidad del correo con la activación y otros resultados?
Haz un seguimiento de la tasa de activación o de la finalización de la verificación por cohorte de registro y compara cohortes con distintos niveles de calidad de correo. Si las cohortes con más desechables o inválidos activan menos, has encontrado una palanca que afecta a las métricas del producto.
¿Qué umbrales debería usar para alertas sin recibir spam de notificaciones?
Define una línea base con las últimas semanas y exige suficiente volumen para evitar ruido. Un aviso práctico salta cuando una tasa sube notablemente sobre lo normal y se mantiene elevada el tiempo suficiente para descartar un pico breve.
¿Cuáles son los errores más comunes que hacen que estas métricas sean engañosas?
El error más frecuente es contar intentos en lugar de registros únicos o sesiones, lo que infla las tasas de inválidos cuando los usuarios reintentan. Otro error es cambiar definiciones con el tiempo: congela las categorías, versiona los cambios y registra las fechas.
¿Debería bloquear correos desechables o solo advertir a los usuarios?
Bloquea por defecto los inválidos obvios y los fallos duros de dominio/MX, ya que rara vez convierten. Trata los correos desechables y los fallos temporales con más cuidado: advertencia, verificación adicional o fricción extra solo en segmentos de mayor riesgo para no dañar conversiones legítimas.