17 feb 2025·6 min
Patrones de validación de correo electrónico asíncrona para registros rápidos y fiables
Aprende patrones de validación de correo asíncrona con colas, webhooks y reintentos para mantener registros con mucho tráfico ágiles y mejorar la calidad de datos.
Por qué la validación síncrona falla bajo alto tráfico
Un endpoint de registro debe ser rápido: aceptar unos pocos campos, crear un registro y responder. La validación síncrona de correo convierte ese camino simple en una cadena de llamadas de red, y cada llamada es otra oportunidad para atascarse.
Bajo carga, las partes lentas rara vez son tu propio código. Son las dependencias que esperas: búsquedas DNS, comprobaciones MX y listas de bloqueo. Incluso si cada paso suele ser rápido, la cola larga importa. Un pequeño porcentaje de peticiones será lento, y cuando el tráfico sube, esas peticiones lentas se acumulan y empiezan a bloquear todo lo demás.
En sistemas reales, tiende a cascada:
- La latencia salta de unos cientos de milisegundos a varios segundos.
- Las peticiones hacen timeout, así que los usuarios pulsan actualizar y generan aún más carga.
- Los servidores de la app agotan hilos de trabajo porque demasiadas peticiones están esperando.
- Los servicios downstream se ven sobrecargados, causando más fallos y reintentos más lentos.
Eso perjudica la conversión y la disponibilidad. La gente abandona páginas de registro lentas. Mientras tanto, tu equipo ve tasas elevadas de error y escala infraestructura solo para manejar la espera.
Imagínate una promoción donde 10.000 personas intentan registrarse en cinco minutos. Si tu ruta de registro espera validación externa, una ralentización temporal de DNS puede convertirse en un incidente de todo el sistema. El camino de registro se vuelve el cuello de botella.
La validación de correo asíncrona es una solución común en sistemas de alto tráfico: acepta el registro rápidamente y valida fuera de banda. Esto mejora la capacidad de respuesta y reduce fallos en cascada. No lo arregla todo, sin embargo. Aún debes decidir qué puede hacer una cuenta recién creada antes de que el correo sea confiable.
Decide qué debe ocurrir antes de crear la cuenta
Registros rápidos y datos perfectos rara vez van de la mano. Si intentas validar completamente cada correo antes de crear la cuenta, añades latencia justo donde los usuarios son más propensos a abandonar.
Una regla práctica: solo haz comprobaciones que sean baratas, locales y deterministas antes de crear la cuenta. Todo lo demás pertenece a la pipeline asíncrona.
Lo que suele tener sentido hacer de inmediato:
- Comprobaciones de campos obligatorios (email presente, contraseña, consentimiento si hace falta)
- Formato básico del correo y errores obvios (falta de @, espacios, caracteres inválidos)
- Limitación de tasa simple o señales de abuso que ya tengas en memoria
- Una comprobación rápida de “¿esto ya está en uso?” (si tu producto requiere correos únicos)
Comprobaciones más profundas pueden esperar sin romper la experiencia de usuario. Verificación de dominio, búsquedas MX, detección de proveedores desechables, señales de trampas de spam y coincidencia en listas de bloqueo en tiempo real pueden ser lentas o fallar a veces.
La decisión clave es tu “ventana de riesgo”: cuánto tiempo permites que exista una cuenta no confiable y qué puede hacer durante ese tiempo. Por ejemplo, podrías permitir que el usuario configure su perfil, pero bloquear el envío de invitaciones, el inicio de una prueba gratuita o el acceso a funciones de alto valor hasta que la validación termine.
El patrón central: aceptar ahora, verificar después
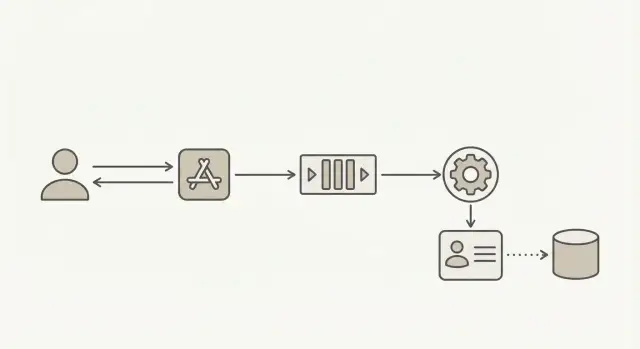
Para mantener los registros rápidos bajo carga, separa “crear un usuario” de “confiar en el correo”. Acepta la petición, crea la cuenta de inmediato y márcala como pendiente. Luego realiza la validación en segundo plano, donde los retrasos no frenarán tu endpoint de registro.
Trata la validación como un flujo de trabajo con sus propios estados y marcas de tiempo, no como un simple booleano. Eso hace que los reintentos sean más seguros, la depuración más fácil y el comportamiento del registro más predecible.
Un flujo común:
- Crea el usuario y establece
email_status = pending(almacena cuándo encolaste la validación) - Encola un trabajo de validación (incluye
user_idy correo) - Un worker valida y actualiza
email_statusavalid,risky,invalidounknown - Tu app restringe acciones según ese estado
Puedes seguir orientando al usuario sin bloquear la petición. Muestra “Revisa tu bandeja para confirmar tu correo” inmediatamente. Cuando la validación termine, actualiza lo que puede hacer.
Cuando la validación falle más tarde, decide de antemano qué sucede. Opciones comunes son restringir acciones sensibles, pedir un nuevo correo o eliminar cuentas claramente falsas tras un periodo de gracia.
Un modelo de datos simple para estados de validación
Si la validación se ejecuta después, tu base de datos debe seguir respondiendo preguntas sencillas: qué puso el usuario, a qué lo normalizaste y qué crees actualmente.
Almacena la entrada cruda separada de un valor normalizado. La entrada cruda ayuda a soporte y debugging (la gente pega espacios extraños). Los campos normalizados son los que usas para emparejar y enviar.
Un pequeño conjunto de estados funciona bien:
- pending: aceptado en el registro, trabajo de validación no terminado
- valid: parece alcanzable y seguro para mantener
- risky: técnicamente válido, pero de baja calidad (por ejemplo desechable o de rol)
- invalid: falló comprobaciones (sintaxis mala, dominio inválido, sin MX, desechable conocido)
- unknown: fallo temporal (timeouts, errores de proveedor), reintentar luego
Junto con el estado, guarda la evidencia, no solo el veredicto. Un paquete compacto de “hechos de validación” evita conjeturas y facilita cambios de política.
Campos sugeridos (nombres de ejemplo):
email_raw,email_normalized,email_domainvalidation_status,validated_at,validation_providervalidation_reason_code,validation_reason_textpolicy_version(oruleset_id), más un contadorvalidation_attempt
Ejemplo: un usuario se registra con " [email protected] ". Guarda la cadena exacta en email_raw, normaliza a [email protected], establece el estado en pending y deja que la cuenta continúe con privilegios limitados. Cuando la validación termine, actualiza estado y hechos sin reescribir la entrada original.
Paso a paso: construir una pipeline de validación asíncrona
Benchmark de latencia de validación
Ve cómo los tiempos de respuesta en milisegundos encajan en el flujo de tus workers de cola.
1) Crea el usuario y publica un trabajo de validación
Cuando alguien envía el formulario de registro, guarda el registro del usuario de inmediato, marca el correo como pending y publica un trabajo pequeño en la cola. El trabajo solo necesita user_id, email y una marca de tiempo requested_at.
Mantén la carga pequeña. Tu base de datos sigue siendo la fuente de la verdad, así que los workers pueden releer el estado más reciente del usuario.
2) Valida en un worker y almacena un código de motivo
Un worker en segundo plano consume trabajos y ejecuta la validación. Aquí es donde llamas a tu servicio de validación de correo sin ralentizar la respuesta de registro.
Escribe el resultado con un estado y un código de motivo. Los estados pueden ser valid, risky, invalid o unknown. Los códigos de motivo pueden ser syntax_error, no_mx, disposable, spam_trap_risk o timeout.
Los códigos de motivo importan porque aceleran las decisiones de soporte y producto. “Invalid” no basta cuando tienes que decidir qué mostrar al usuario.
3) Dispara la acción de seguimiento adecuada
Una vez que guardes el estado, aplica tu política:
- Valid: desbloquea límites normales y envía correos de ciclo de vida
- Risky: permite ingreso, pero reduce límites o marca para revisión
- Invalid: pide un nuevo correo antes de acciones clave
- Unknown: reintenta más tarde y mantiene la cuenta limitada
4) Revisa cuando cambie el correo
Cuando un usuario actualice su correo, resetea el estado a pending y publica un nuevo trabajo. Registra qué dirección fue comprobada para que resultados antiguos nunca apliquen a un valor nuevo.
Flujo de validación por webhook: push vs pull
Una vez que la validación es asíncrona, necesitas una forma de traer los resultados de vuelta a tu app. Hay dos modelos principales:
Pull significa que tu app consulta el estado más tarde. Es más fácil de razonar y suele ser suficiente cuando solo un sistema necesita la respuesta. La desventaja es tráfico extra y actualizaciones más lentas si consultas con poca frecuencia.
Push significa que el validador te llama de vuelta con un evento tipo webhook tan pronto como el resultado está listo. Esto ayuda cuando varios sistemas lo necesitan (servicio de registro, sincronización CRM, automatización de marketing) o quieres actualizaciones casi en tiempo real sin hacer polling.
Si implementas push, mantén la carga del callback pequeña pero completa:
- Identificador interno (user id o account id)
- Estado de validación (
valid,invalid,risky,unknown) - Código de motivo
- Marca de tiempo y un id de evento único
- Opcional: un hash del email (no el correo en claro) para debugging
Asegúralo. Requiere HTTPS, verifica una firma con un secreto compartido, rechaza peticiones antiguas por timestamp y guarda una caché de ids de evento vistos por poco tiempo para prevenir replay. Si tu infraestructura lo permite, añade una lista de IPs permitidas.
Fundamentos de fiabilidad: reintentos, idempotencia y backpressure
Mover la validación fuera de la petición de registro gana velocidad, pero aún necesitas manejar fallos cotidianos: redes que caen, proveedores que hacen timeout, workers que se caen a mitad de trabajo.
Reintentos: trata la validación como algo reintentable. Timeouts y errores 5xx suelen ser temporales, así que reintenta con un retraso que crezca cada vez. Mantén la ventana acotada para no validar la misma dirección durante horas.
Idempotencia: asume entregas duplicadas desde colas y webhooks. Da a cada petición una clave de deduplicación estable (por ejemplo, un request_id o (user_id, validation_attempt)), y haz que tus actualizaciones sean seguras para aplicarse dos veces y terminar en el mismo estado final.
Dead letters: cuando los reintentos fallan consistentemente, detente. Mueve el trabajo a una dead-letter queue y marca el correo como unknown para investigarlo después.
Backpressure: limita la concurrencia y establece presupuestos de tiempo para que la validación no pueda abrumar rutas críticas como registro, login y facturación.
Algunas métricas detectan la mayoría de los problemas temprano:
- Profundidad y antigüedad de la cola (cuánto tiempo ha esperado el trabajo más antiguo)
- Tasa de éxito vs fallos transitorios vs fallos permanentes
- Tiempo medio de validación y latencias p95/p99
- Conteos de reintentos y volumen de dead-letter
- Utilización de workers
Manejar la escala: desduplicación, caché y límites de tasa
Mantén una lista de correo más saludable
Valida nuevos registros y actualizaciones para mantener más limpia tu CRM y los correos de ciclo de vida.
El alto tráfico suele fallar de forma aburrida: la misma dirección se valida repetidamente, los workers se acumulan y una dependencia lenta hace que todo parezca roto. El objetivo es hacer la validación barata durante los picos sin perder frescura razonable en los resultados.
Desduplicar durante picos. Normaliza claves (minúsculas, trim) para que [email protected] y [email protected] se mapeen igual. Añade una “ventana de dedupe” corta antes de encolar (o al inicio del worker) para que el mismo correo no se valide 20 veces en un minuto.
Cachear brevemente. Cachear no es para mantener resultados por siempre. Es para evitar trabajo repetido durante picos. Cachea tanto resultados positivos como negativos, pero expíralos rápidamente.
Un punto de partida simple:
- Cache de “Valid”: 1 a 24 horas
- Cache de “Invalid/desechable”: 5 a 60 minutos
- Cache de “Unknown/timeout”: 1 a 5 minutos
Límites de tasa y prioridades. Protege cada dependencia downstream con un rate limit. Durante picos, prioriza validaciones que desbloquean acciones de mayor riesgo como restablecimientos de contraseña, pagos o invitaciones a equipo. Deja las comprobaciones de bajo impacto (suscripciones a newsletter) esperar un poco.
Errores comunes que causan ralentizaciones y bugs
Marcar usuarios verificados demasiado pronto
Establecer email_verified = true cuando encolas la comprobación convierte “vamos a comprobar” en “ya comprobamos”. Si la cola se atasca, acabas dando acceso completo a direcciones que nunca validaste.
Transiciones de estado vagas o ausentes
Si solo tienes “pending” y “verified”, las cuentas pueden quedarse atascadas cuando los proveedores hacen timeout. Usa estados claros como pending, valid, invalid, risky y unknown, y haz que cada transición sea intencional.
Handlers de webhook no idempotentes
Los webhooks pueden llegar duplicados. Si tu handler crea un nuevo trabajo cada vez, un usuario puede disparar diez validaciones y diez actualizaciones. Clavea actualizaciones por un id de evento estable o request id e ignora repeticiones.
Filtrar detalles sensibles
No registres direcciones completas ni expongas en el cliente que una dirección es “trampa de spam” o de un “proveedor desechable”. Enmascara logs y devuelve resultados simples.
Bloquear acciones clave sin un plan
Si bloqueas login o compras hasta que la validación asíncrona termine, recreas el problema original del registro lento. Acceso limitado + mensaje claro suele funcionar mejor.
Checklist rápido antes de lanzar
Integra la validación de forma sencilla
Agrega comprobaciones de sintaxis RFC, dominio y MX a tu canal asíncrono en minutos.
Prueba el peor día, no el día promedio. Simula validación lenta, timeouts y un pico repentino de tráfico, y confirma que el registro sigue siendo ágil y que el backlog se drena de forma segura.
- El registro responde rápido aunque la validación se demore (la cuenta se crea con un estado
pendingclaro). - Una única fuente de la verdad para el estado de validación (no banderas dispersas entre servicios).
- Reintentos definidos y acotados, con manejo de dead-letter.
- Endpoints de webhook (si se usan) seguros e idempotentes.
- Dashboards y alertas para fallos, timeouts y backlog de la cola.
Siguientes pasos: desplegar de forma segura y mantener los datos limpios
Empieza en pequeño y mantiene el sistema predecible. Acordad un conjunto corto de estados (por ejemplo pending, valid, invalid, unknown) y hace que un único camino de trabajo en background sea el único que los cambie.
Solo añade un consumidor de webhook cuando realmente necesites notificar a otros sistemas en tiempo casi real. Si tu app es la única consumidora, leer el estado más reciente de tu propia base de datos suele ser más sencillo.
Antes de escribir código, redacta tus reglas de reintento y dedupe: qué cuenta como el mismo evento, cuánto tiempo reintentas y qué pasa cuando te rindes. Eso evita duplicados misteriosos y bucles accidentales más adelante.
Si quieres externalizar las comprobaciones más profundas, Verimail (verimail.co) es una API de validación de correo diseñada para proteger registros, con comprobaciones de sintaxis, verificación de dominio y MX, detección de proveedores desechables y coincidencia con listas de bloqueo en una sola llamada. Incluso con un validador rápido, mantener la llamada en un worker en lugar de en la petición de registro es lo que protege tu flujo durante los picos.
Preguntas frecuentes
¿Por qué la validación síncrona de correo hace que los registros sean lentos con mucho tráfico?
La validación síncrona hace que la petición de registro espere llamadas de red externas como DNS y búsquedas MX. En picos de tráfico, un pequeño porcentaje de búsquedas lentas se acumula, ocupa hilos de trabajo y puede llevar al timeout de todo el endpoint.
¿Qué debo validar inmediatamente y qué puede ir al background?
Haz solo comprobaciones baratas y locales que no puedan agotar tiempo: campos obligatorios, formato básico del correo, recorte de espacios obvios y controles sencillos de abuso que ya tengas en memoria. Deja para segundo plano las comprobaciones más profundas como MX, detección de proveedores desechables y coincidencia con listas de bloqueo.
¿Cuál es el flujo asíncrono más simple para implementar?
Crea la cuenta de inmediato, establece explícitamente email_status = pending y encola un trabajo de validación vinculado al usuario y al valor de correo actual. Cuando el worker termine, actualizará el estado y almacenará un código de motivo para que la app reaccione de forma consistente.
¿Qué estados de validación de correo debería almacenar?
Usa un conjunto pequeño de estados con los que puedas aplicar reglas: pending, valid, risky, invalid y unknown. Unknown es importante para manejar timeouts y errores de proveedor y así evitar marcar cuentas como verificadas cuando no lo están.
¿Qué puede hacer el usuario mientras su correo está pendiente?
Permiteles avanzar con acciones de bajo riesgo mientras el correo está pending, y bloquea o retrasa acciones de alto valor hasta que sea valid. Suelen bloquearse invitaciones a equipo, pruebas gratuitas, pagos y flujos de restablecimiento de contraseña.
¿Qué debo almacenar además de “válido/ínválido”?
Guarda un paquete compacto de “hechos”: correo normalizado, dominio, estado, marca de tiempo, proveedor, código de motivo, versión de política y contador de intentos. Esto facilita soporte y debugging sin tener que repetir comprobaciones para explicar una decisión.
¿Cómo deben funcionar los reintentos y fallos en una pipeline asíncrona?
Reintenta timeouts y errores 5xx con backoff y un límite duro para no reintentar indefinidamente. Si agotas los reintentos, marca el correo como unknown, mueve el trabajo a una dead-letter queue y mantiene la cuenta limitada hasta poder revalidar.
¿Cómo hago idempotentes los handlers de webhooks y los trabajos?
Asume que habrá duplicados y haz las actualizaciones seguras para aplicarlas varias veces. Usa una clave de desduplicación estable como (user_id, validation_attempt) o un id de solicitud/evento y descarta resultados tardíos que no coincidan con el correo actual del usuario.
¿Cómo aseguro los resultados de validación “push” vía webhook?
Requiere HTTPS, verifica una firma con un secreto compartido y rechaza callbacks demasiado antiguos según su timestamp. Guarda ids de evento vistos por un tiempo corto para evitar que replays sobrescriban estado o desencadenen trabajo extra.
¿Cómo reduzco validaciones repetidas durante picos?
Normaliza correos consistentemente (trim y lowercase) y añade una ventana corta de desduplicación para que la misma dirección no se valide decenas de veces en minutos. Cachea resultados recientes por poco tiempo para reducir búsquedas repetidas sin mantener respuestas obsoletas.