19 ene 2025·8 min
Plan de despliegue multietapa de validación de email más allá de solo regex
Planea un despliegue multietapa de validación de email (más allá de regex): hitos, métricas, rampas de tráfico graduales y retrocesos seguros para evitar roturas en el registro.
Por qué las comprobaciones solo por regex dejan de funcionar a escala
Una comprobación por regex responde a una pregunta: ¿esto parece una dirección de correo? Captura errores obvios como falta de una @, espacios o un formato de dominio roto. Eso es útil, pero es solo una prueba de formato. No te dice si la dirección puede recibir correo.
A medida que crece el volumen de registros, los errores que el regex no detecta empiezan a importar más que los aciertos. El regex no puede decir si un dominio existe, si tiene registros MX operativos o si una dirección pertenece a una bandeja desechable. Tampoco te protege de trampas de spam y otras direcciones que parecen válidas pero dañan la entregabilidad.
Los equipos suelen aprender algunas lecciones por las malas:
- Si eres demasiado estricto, bloqueas usuarios legítimos (incluidas direcciones inusuales pero válidas) y la conversión baja silenciosamente.
- Si eres demasiado laxo, cuentas falsas se cuelan, aumenta la carga de soporte y se acumulan rebotes.
- Con el tiempo, rebotes repetidos y quejas pueden perjudicar la reputación del remitente, empeorando el rendimiento de cada campaña.
Por eso importa un despliegue multietapa de validación de correo. Pasas de una coincidencia de patrón a comprobaciones en capas (sintaxis, dominio, MX y señales de riesgo), pero lo haces de forma que no sorprenda a los clientes reales.
Un despliegue seguro tiene tres objetivos: mínimo impacto al usuario (sin roturas súbitas en el registro), progreso medible (métricas claras antes y después de cada cambio), y una reversión fácil (un interruptor simple para volver al comportamiento anterior si la conversión o la entregabilidad empeoran).
Este plan es para equipos de producto, ingeniería y crecimiento con el mismo objetivo: mantener la fricción baja en el registro mientras se reducen las direcciones inválidas y el fraude. Herramientas como Verimail pueden ejecutar las comprobaciones multietapa en una sola llamada API, pero el enfoque de despliegue es el mismo independientemente de lo que uses.
Definir objetivos, restricciones y responsabilidades
Antes de cambiar la validación, deja claro qué significa “bien” para tu negocio. El objetivo no es bloquear gente. El objetivo es aceptar correos reales y alcanzables mientras reduces registros de baja calidad que consumen tiempo y dañan la entregabilidad.
Anota 2–3 resultados que puedas medir, como menos direcciones desechables en el registro, menos rebotes duros en la primera semana y menos cuentas creadas para abuso. Aquí también decides cuán estrictas deben ser las reglas en distintos flujos.
Objetivos y restricciones a acordar
Pon algunos límites para que la validación ayude sin crear nuevos problemas:
- Latencia: sin desaceleración perceptible en flujos críticos (especialmente registro y pago).
- Conversión: sin caída significativa en la tasa de finalización tras la aplicación.
- Carga de soporte: mantener las consultas “¿por qué se rechazó mi correo?” previsibles y raras.
- Equidad: permitir casos límite legítimos (dominios nuevos, servidores corporativos, direccionamiento con +).
- Cumplimiento: guarda solo lo necesario (evita registrar correos completos en analytics si no hace falta).
A continuación, decide dónde se ejecuta la validación. La mayoría empieza en el registro, pero invitaciones, restablecimientos de contraseña, recibos de compra y usuarios creados por admins también pueden introducir direcciones malas. Una regla simple: valida en todos los sitios donde se crea un nuevo registro de email y mantén la experiencia consistente.
Responsabilidades y derechos de decisión
Las comprobaciones multietapa generan decisiones de producto y soporte, no solo tareas de ingeniería. Acordad desde el principio quién se encarga de qué:
- Producto: qué se bloquea frente a qué se advierte, y qué dice el mensaje de error.
- Ingeniería: dónde se ejecutan las comprobaciones, timeouts, reintentos y cómo se cachean los resultados.
- Datos/marketing: qué métricas definen el éxito (reducción de rebotes, tasa de abuso, entregabilidad).
- Soporte: un playbook corto para excepciones y explicaciones comunes a usuarios.
Si usas una API como Verimail en el registro, decidid quién puede relajar reglas si la conversión baja y con qué rapidez responderéis cuando un usuario legítimo quede bloqueado.
Cómo es la validación multietapa en términos sencillos
La validación solo por regex es como mirar una llave y ver si parece correcta sin probarla en la cerradura. La validación multietapa añade algunas comprobaciones rápidas que te dicen si una dirección es probablemente real y alcanzable.
Primero está la sintaxis, pero hecha correctamente. Una comprobación de sintaxis compatible con RFC maneja formatos que los regex básicos suelen romper, como el direccionamiento con + ([email protected]), puntos en la parte local y TLDs modernos largos. También evita falsos positivos que cumplen el patrón pero violan reglas de email.
Segundo, la verificación del dominio. Si el dominio no existe, nadie puede recibir correo allí. Una búsqueda DNS confirma que el dominio es real, y una consulta de registros MX comprueba si el dominio anuncia servidores de correo (o enruta correo mediante registros relacionados). Esto captura errores como gmal.com y dominios inactivos que un regex aceptaría sin problema.
Tercero, reputación y señales de riesgo. Eso incluye detectar proveedores desechables y comparar con listas de bloqueo de fuentes conocidas malas o riesgosas.
La idea no es “bloquear más”. Es elegir la acción correcta según el nivel de confianza:
- Permitir: pasa todas las etapas.
- Advertencia suave: parece riesgoso, pero deja continuar al usuario.
- Requerir confirmación: aceptar el registro, pero verificar por correo antes de la activación.
- Bloquear: claramente inválido, desechable (si tu política lo indica) o de alto riesgo.
Planea casos límite como subdominios (mail.eu.company.com), pasarelas corporativas que enrutan correo de formas inusuales y alias legítimos con +. Herramientas como Verimail pueden ejecutar estas comprobaciones en una sola llamada API, pero tu política de producto decide qué hacer tras cada resultado.
Obtén una línea base antes de cambiar nada
Antes de un despliegue multietapa, necesitas una foto clara de cómo se comporta el registro hoy. Sin una línea base, es fácil “mejorar” la validación mientras dañas silenciosamente la conversión, la carga de soporte o la entregabilidad.
Instrumenta todo el funnel de registro y los resultados de correo de punta a punta. Mide no solo cuántos usuarios completan el registro, sino qué ocurre después: ¿llegan los correos de verificación?, ¿los usuarios activan?, ¿los mensajes rebotan más tarde?
Sigue un pequeño conjunto de métricas base durante al menos 1 o 2 ciclos normales de negocio (a menudo 7–14 días):
- Tasa de conversión de registro (visita a cuenta creada)
- Tasa de entrega del correo de verificación y tiempo hasta verificar
- Tasa de rebotes (duros y suaves) en tus primeros envíos
- Tasa de quejas (cuando los proveedores marcan tus mensajes)
- Tickets de soporte ligados a “no puedo registrarme” o “no recibí el correo”
Si ya rechazas algunas direcciones (incluso con validación solo por regex), registra cada motivo de rechazo y el contexto: tipo de cliente, país/locale, dominio y si el usuario intentó nuevamente con otra dirección. Los tickets de soporte forman parte de la línea base, porque reglas más estrictas pueden trasladar el dolor de rebotes a usuarios bloqueados.
Luego, crea un dataset etiquetado a partir de registros recientes. Una aproximación simple es muestrear las últimas semanas de cuentas nuevas y etiquetar cada correo como: aceptado y activo, aceptado pero rebotó después, aceptado pero generó queja después, o nunca verificó. Esto será tu “verdad base” para comparar nuevas comprobaciones.
Finalmente, decide cómo cuantificarás errores durante el despliegue:
- Falsos positivos: correos legítimos bloqueados o retrasados (vigila caídas de conversión y picos de tickets).
- Falsos negativos: correos malos permitidos (vigila rebotes, dominios desechables y señales de trampas de spam).
Cuando luego pruebes un validador (por ejemplo, Verimail en modo shadow), puntúa sus decisiones contra esta línea base para que los cambios sean medibles y no anecdóticos.
Fase 1: Modo shadow para aprender sin romper registros
El modo shadow significa ejecutar las nuevas comprobaciones multietapa en cada registro, pero sin bloquear a nadie todavía. La experiencia del usuario sigue igual. Tu equipo obtiene datos reales sobre lo que el validador habría hecho, sin arriesgar la conversión.
Registra resultados de cada etapa, no solo un único aprobado/rechazado. Por ejemplo: resultado de sintaxis, dominio existe, registros MX encontrados, detectado como desechable y cualquier coincidencia en listas de bloqueo. Mantén la decisión vieja basada en regex junto a ello para comparar después.
Un hito útil es responder tres preguntas con números:
- ¿Qué porcentaje de registros son correos desechables?
- ¿Qué porcentaje tiene dominios inválidos o no resolubles?
- ¿Qué porcentaje parece riesgoso (por ejemplo, trampas sospechadas u otras señales rojas)?
Esas tasas se convierten en tu línea base para el despliegue. Si usas una API de validación como Verimail, almacena la respuesta cruda y tu decisión interna final por separado, así puedes cambiar reglas más tarde sin perder el historial.
Elige una cadencia de revisión que saque los problemas rápido. Revisiones diarias la primera semana suelen detectar sorpresas como un pico desde una fuente de tráfico o un dominio corporativo común que falla las comprobaciones DNS durante un incidente temporal. Después de la primera semana, pasa a revisiones semanales.
Un ejemplo práctico: si tu regex aprueba el 98% de registros, pero el modo shadow muestra que el 6% son desechables y el 1% tiene dominios inválidos, ahora tienes un objetivo claro de lo que la aplicación podría ahorrar. También tienes una lista de casos límite para manejar con cuidado antes de bloquear a un usuario real.
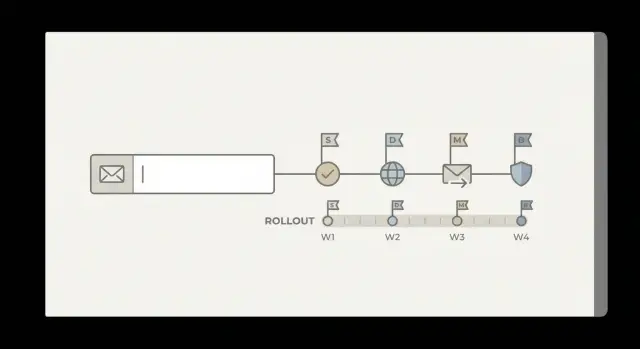
Fase 2: Aplicación gradual con hitos medibles
Convierta el despliegue en métricas
Compara decisiones de regex con resultados multinivel y sigue los resultados por cohortes.
Tras el modo shadow, pasa a la aplicación en pasos pequeños y reversibles. El objetivo es reducir direcciones malas sin sorprender a usuarios reales ni dañar la conversión.
Empieza con un segmento estrecho donde el riesgo sea bajo y el aprendizaje alto. Una elección común son nuevos registros desde anuncios pagados, tráfico de afiliados o una sola geografía donde veas más correos desechables. Mantén el resto del tráfico sin cambios para poder comparar resultados.
Comienza con acciones de bajo riesgo antes de bloquear. Si la validación marca una dirección como desechable o no entregable, muestra un mensaje corto pidiendo al usuario que lo revise e intente otro correo. Facilita editar y continuar. Solo pasa a bloquear duro cuando estés seguro de no atrapar usuarios legítimos.
Un plan de subida simple se ve así:
- Aplicar al 5% del segmento elegido, vigilar métricas 24–48 horas.
- Subir al 25% si no se alcanzan condiciones de parada.
- Subir al 50% y luego al 100% para ese segmento.
- Ampliar al siguiente segmento (otro canal o geo) y repetir.
- Cuando sea estable en segmentos, aplicar a todos los registros nuevos.
Define condiciones de parada por adelantado y escríbelas. Ejemplos: la conversión de registro cae más de X%, el tiempo mediano para completar el registro aumenta Y segundos, los contactos de soporte por problemas de registro superan Z por día, o los rebotes posteriores dejan de mejorar.
Controla hitos que reflejen experiencia de usuario y valor de negocio: tasa de conversión, tiempo para completar el registro, cuántos usuarios reintentan con un nuevo correo, volumen de soporte y tasa de rebote de correos de bienvenida. Si usas una API como Verimail, también monitoriza cómo cambian las tasas de veredictos “inválido” y “desechable” mientras escalas.
Trata cada subida como un punto de decisión con un umbral claro para avanzar, mantener o revertir. Eso mantiene el despliegue tranquilo y fácil de explicar entre producto, ingeniería y soporte.
Métricas y dashboards que realmente detectan regresiones
Si solo miras “los registros subieron o bajaron”, te perderás el impacto real de los cambios de validación. Construye un dashboard para la salud inmediata del registro y una vista secundaria que siga a esos usuarios hacia la entrega de correo y resultados de abuso.
Elige un pequeño conjunto de métricas primarias que usarás como decisoras. Tenlas visibles en cada gráfico y evita añadir tantas líneas que nadie sepa qué importa.
Estas cinco suelen decir la verdad rápido:
- Tasa de conversión de registro (registros completados / registros iniciados)
- Tasa de inválidos o no entregables (resultados de validación más rebotes posteriores)
- Tasa de correos desechables (y cómo varía por canal)
- Señales de abuso (reportes de spam, registros sospechosos, compromisos vinculados a nuevas cuentas)
- Resultados de entrega tras el registro (tasa de rebote, tasa de queja, proxies de colocación en bandeja si los tienes)
Añade guardrails antes de aplicar nada. Usa umbrales, no intuición: por ejemplo, “no más de 0.5% de caída absoluta en conversión” y “no más de 50 ms añadidos de latencia en p95”. Si se rompe un guardrail, pausa el despliegue e investiga.
Corta cada métrica por cohortes para detectar fallos localizados: canal de adquisición, país, tipo de dispositivo y categoría de dominio (proveedores gratuitos vs dominios de empresa). Una regresión común es bloquear demasiado en una geografía o en móvil, donde los errores tipográficos son más frecuentes.
Revisa casos limítrofes semanalmente. Extrae una pequeña muestra de direcciones “arriesgadas pero no claramente malas” y comprueba si personas reales están siendo bloqueadas. Si usas una API como Verimail, registra los códigos de razón (sintaxis, MX, coincidencia en listas) para ver qué etapa causa fricción y afinar reglas sin adivinar.
Fallbacks, rollbacks y opciones seguras de experiencia de usuario
Mantén tu lista limpia
Evita inscripciones falsas y leads de baja calidad antes de que entren al sistema.
La validación multietapa detecta más registros malos, pero también puede bloquear usuarios reales si algo cambia (caídas de DNS, dominios corporativos nuevos, problemas temporales de enrutamiento). Planea fallos antes de activar la aplicación.
Empieza con un kill switch que te devuelva instantáneamente al comportamiento de solo regex. Que sea una configuración server-side, no un deploy. Combínalo con feature flags para cada tipo de regla para que puedas desactivar una parte sin perder todo: manejo de MX, bloqueo de desechables y coincidencias en listas de bloqueo.
Cuando bloquees o desafíes a un usuario, elige un fallback que mantenga el registro activo al tiempo que proteja tu plataforma. Opciones que funcionan bien incluyen:
- Permitir el registro, pero requerir confirmación por correo antes de iniciar sesión o habilitar acciones clave.
- Permitir el registro, pero retrasar funciones de riesgo (referencias, cupones, claves de API, créditos de prueba) hasta verificar.
- Poner la cuenta en modo limitado mientras vuelves a comprobar el correo tras unos minutos.
- Pedir otro correo solo cuando la señal sea fuerte (proveedor desechable conocido, problemas claros de sintaxis).
Con cualquier API de validación, los falsos positivos son el mayor riesgo del despliegue. Trátalos como incidentes. Define quién se alarma, con qué rapidez y qué significa “detener la hemorragia” (normalmente invertir el kill switch o desactivar la flag más estricta primero). Mantén la comunicación interna simple: qué falló, quiénes se ven afectados y qué cambiaste.
Un playbook ligero de incidentes puede ser pequeño:
- Confirmar el pico (registros bloqueados, tickets de soporte, caída de conversión).
- Desactivar la flag más probable (desechables o listas de bloqueo) antes de apagar todo.
- Extraer ejemplos de correos bloqueados y revisar patrones (dominio, región, proveedor).
- Decidir si es una caída temporal o un problema de reglas.
- Documentar la solución y añadir una prueba o monitor para que se detecte antes la próxima vez.
Finalmente, mantén un proceso de allowlist para dominios importantes (socios, clientes grandes). Requiere un responsable, una justificación y rastro de auditoría, y revisa las entradas con regularidad para que las excepciones no se acumulen en silencio.
Trampas comunes que sufren los equipos durante la migración
La mayoría de problemas de migración no vienen del validador en sí. Vienen de tratar señales tempranas como verdades finales y aplicar restricciones demasiado rápido. Un despliegue seguro necesita margen para la incertidumbre.
Un error común es bloquear registros porque el DNS estuvo inestable un minuto. Los usuarios reales no controlan sus resolutores DNS, la Wi‑Fi de un hotel o firewalls corporativos. Si tu sistema hace una sola consulta y falla cerrando la validación, rechazarás correos buenos. Cachea las comprobaciones de dominio cuando puedas, reintenta con un pequeño retardo y registra la razón para ver si las fallas se agrupan por región o ISP.
Otra trampa es asumir que “sin MX” siempre significa “inválido”. Algunos dominios aceptan correo en la dirección A, y algunas configuraciones son inusuales pero reales. Si tratas cada resultado “sin MX” como bloqueo duro, generarás falsos positivos. Trátalo como señal de riesgo a menos que tengas evidencia sólida de que es inalcanzable.
El bloqueo de desechables también complica a los equipos. Si tu producto tiene casos legítimos de uso a corto plazo (pruebas, descargas puntuales, registro para eventos), un bloqueo estricto puede dañar la conversión. En lugar de una prohibición global, decide qué quieres proteger: abuso, contracargos, entregabilidad o todo ello.
Algunos patrones de fallo que aparecen en postmortems son:
- No separar “definitivamente inválido” de “no se puede verificar ahora”.
- Aplicar reglas globales antes de probar por segmento (país, fuente de tráfico, dispositivo).
- Lanzar sin guiones de soporte y mensajes claros al usuario.
- Tratar errores temporales de DNS igual que fallos permanentes de dominio.
- Bloquear dominios desechables sin un plan de excepciones según producto.
Un ejemplo realista: despliegas en todos los mercados un lunes, los timeouts de DNS suben en una región y soporte recibe tickets “mi correo es real” en pocas horas. Si hubieras tenido un camino de “intenta de nuevo” para “no se puede verificar ahora” y un despliegue por segmentos, podrías haber mantenido los registros mientras investigabas.
Lista de comprobación rápida para el despliegue
Antes de aplicar cualquier restricción, asegúrate de poder demostrar si el cambio ayudó o perjudicó. El despliegue es más seguro cuando cada paso tiene un responsable claro, un objetivo medible y una forma fácil de deshacerlo.
Usa esta lista justo antes de pasar de pruebas a aplicación real:
- Línea base capturada y estable: Tienes varios días (o semanas) de conversión de registro, tasa de rebote de correos y tickets por “email inválido” en un solo lugar, y conoces el rango normal.
- Resultados en shadow revisados y decisiones documentadas: Has revisado lo que el validador habría bloqueado, comprobado una muestra de casos límite (dominios corporativos, TLDs raros) y acordado umbrales (cuándo bloquear duro frente a advertir).
- Feature flags y kill switch probados en producción: Puedes activar o desactivar la validación instantáneamente sin deploy y has probado la ruta “off” con tráfico real (no solo staging). Si llamas a una API como Verimail, incluye timeouts y un comportamiento seguro por defecto.
- Soporte listo para las primeras quejas: Tienes respuestas cortas prefabricadas para “¿por qué se rechazó mi correo?”, una forma de recoger ejemplos y una vía de escalado clara al ingeniero responsable del despliegue.
- Calendario y condiciones de parada documentadas: Tienes un calendario de despliegue, propietarios nombrados para cada paso y razones específicas para pausar (por ejemplo, la conversión cae más de X% durante Y horas o las falsas rejections superan un conteo establecido).
Cuando esto esté hecho, el despliegue se vuelve rutinario: activa el siguiente porcentaje, vigila las mismas métricas y detén rápido si los usuarios sufren.
Un escenario de despliegue realista
Añadir validación en minutos
Añade una única llamada API al registro y mantén la latencia baja.
Una app SaaS de tamaño medio empieza a ver dos problemas a la vez: más pruebas falsas (cuentas que nunca vuelven a iniciar sesión) y aumento de rebotes en correos de onboarding. Su formulario de registro solo usa validación por regex, así que casi cualquier cosa que parezca un correo pasa.
Añaden validación multietapa en modo shadow primero. Los registros siguen igual, pero cada dirección enviada se comprueba en segundo plano por sintaxis, dominio, MX y proveedores desechables. Tras dos semanas, el equipo revisa resultados y encuentra dos patrones: una gran parte de nuevas pruebas usan dominios desechables y un grupo más pequeño usa dominios que no aceptan correo (sin MX, dominios aparcados o errores comunes).
Con esos datos, pasan a una aplicación gradual con hitos simples:
- Semana 1: mostrar una advertencia amable para correos desechables y pedir un inbox personal o de trabajo.
- Semana 2: bloquear solo los claramente inválidos (dominio roto, sin DNS), dejando todo lo demás permitido.
- Semana 3: bloquear patrones de abuso repetido (por ejemplo, múltiples registros desde la misma fuente con diferentes direcciones desechables).
También añaden un fallback seguro para casos inciertos. Si la comprobación no es confiable, el usuario aún puede registrarse, pero debe confirmar su correo antes de acceder a funciones clave. Eso mantiene a usuarios reales en movimiento mientras filtran registros de baja calidad.
Al final del despliegue, el equipo busca un resultado por encima de todo: que los rebotes bajen sin un golpe significativo en inicios de prueba o activación. Si los rebotes disminuyen y las pruebas activadas se mantienen, endurecen la política de desechables. Si la conversión cae, aflojan la aplicación y confían más en la confirmación hasta afinar reglas.
Próximos pasos: implementar, afinar y seguir mejorando
La validación multietapa solo resulta arriesgada cuando las reglas son vagas. Elige una primera regla de aplicación que sea a la vez de bajo riesgo y alto valor. Para muchos equipos, eso significa bloquear dominios claramente inválidos (sin DNS) y manejar proveedores desechables según la política del producto.
Escribe una política interna corta para que todos sepan qué significa “válido” en tu producto:
- Bloquear: obvios inválidos (sintaxis rota, dominio muerto, dominios desechables si tu producto depende de identidad real)
- Advertir: riesgosos pero posibles (errores tipográficos, dominios catch-all, hosts temporales que no estás listo para bloquear)
- Permitir: todo lo demás, pero etiquetarlo para poder medir resultados más tarde
Después elige un validador que pueda ejecutar comprobaciones multietapa rápido (sintaxis, dominio, MX y detección de desechables) y que devuelva códigos de razón que puedas registrar. Si estás evaluando Verimail (verimail.co), está diseñado para este estilo de despliegue: una llamada API puede cubrir sintaxis, verificación de dominio, búsqueda MX y detección de desechables, y puedes empezar en modo shadow antes de aplicar nada.
Programa una revisión post‑despliegue (por ejemplo, 7–14 días después de empezar la aplicación). Reúne un pequeño conjunto de correos disputados, busca falsos positivos y afina umbrales o allowlists. Un buen despliegue no es un interruptor único. Es un conjunto vivo de reglas que evoluciona conforme cambian los patrones de registro.
Preguntas frecuentes
¿Por qué no basta la validación por regex?
Una comprobación por regex solo te dice si una entrada parece una dirección de correo. No puede confirmar que el dominio exista, que el dominio pueda recibir correo ni si la dirección es de un proveedor desechable, por lo que direcciones malas aún pasan y aparecen después como rebotes y quejas.
¿Qué incluye normalmente la “validación multietapa”?
Empieza con comprobaciones por capas que respondan distintas preguntas: sintaxis compatible con RFC, existencia del dominio vía DNS, registros MX (o enrutamiento equivalente), y señales de riesgo como proveedores desechables y fuentes conocidas malas. Trata la salida como una señal de confianza y decide si permitir, advertir, exigir confirmación o bloquear.
¿Cómo añadimos validación multietapa sin dañar la conversión de registros?
Usa modo shadow: ejecuta el nuevo validador en cada registro pero no cambies lo que ve el usuario todavía. Registra el resultado de cada etapa y compáralo con lo que tu regex actual habría decidido, así aprendes el impacto real antes de aplicar ninguna restricción.
¿Qué métricas debemos vigilar durante un despliegue?
Como mínimo, sigue conversión de registro, tasa de entrega de correos de verificación, tasa de rebotes tempranos en los primeros envíos, tasa de quejas y tickets de soporte ligados a registro o correos no recibidos. Córtalos por cohortes (canal, país, dispositivo, tipo de dominio) para detectar regresiones que sólo afectan a un subconjunto.
¿Cuál es la mejor primera regla para aplicar después del modo shadow?
Una primera regla segura es bloquear entradas claramente inválidas como sintaxis rota o dominios inexistentes, porque esos usuarios no pueden recibir correo. Para cualquier caso incierto, prefiere una advertencia o un flujo “regístrate ahora, verifica antes de acceder” hasta que tengas suficientes datos para endurecer las reglas.
¿Debemos bloquear correos si un dominio no tiene registro MX?
Trata “sin MX” como una señal de riesgo, no como un fallo automático. Algunos dominios aceptan correo mediante la dirección A u otras configuraciones, y bloquear estrictamente puede generar falsos positivos; un comportamiento más seguro es permitir con confirmación requerida o una advertencia suave a menos que tengas evidencia fuerte de que el dominio es inalcanzable.
¿Cómo deberíamos aumentar la aplicación de reglas de forma segura?
Usa un despliegue gradual por segmentos con feature flags y condiciones de parada predefinidas. Por ejemplo: aplica en un solo canal o región primero, aumenta el porcentaje lentamente y pausa o revierte si la conversión cae por encima del umbral o los tickets de soporte se disparan.
¿Qué plan de rollback deberíamos tener antes de aplicar restricciones?
Construye un kill switch server-side que devuelva instantáneamente el comportamiento previo sin necesidad de un deploy. También separa flags por tipo de regla (manejo de MX, bloqueo de desechables, comprobaciones de listas de bloqueo) para poder desactivar la regla problemática antes de apagar todo.
¿Qué alternativas amigables al usuario hay además del bloqueo duro?
Mantén el registro en movimiento mientras reduces riesgo: permite crear la cuenta pero exige confirmar el correo antes de iniciar sesión o habilitar acciones clave; o limita funciones de alto abuso hasta la verificación. Haz el mensaje de error breve y específico y da una forma fácil de editar el correo y reintentar.
¿Qué deberíamos buscar en una API de validación de emails como Verimail?
Busca un validador que devuelva códigos de razón claros que puedas registrar (sintaxis, DNS, MX, desechable, lista de bloqueo) y que responda lo bastante rápido para el registro. Verimail es un ejemplo que ejecuta estas comprobaciones en una sola llamada API, lo que facilita empezar en modo shadow y luego aplicar reglas gradualmente según tu política.