19 janv. 2025·8 min
Plan de déploiement en plusieurs étapes pour la validation d’e‑mails — au‑delà des seules regex
Planifiez un déploiement de validation d’e‑mails en plusieurs étapes, partant des seules regex, avec jalons, métriques, montées progressives de trafic et revert sûr pour éviter de casser les inscriptions.
Pourquoi les contrôles uniquement par regex cessent de fonctionner à grande échelle
Un contrôle par regex ne répond qu’à une seule question : est‑ce que ça ressemble à une adresse e‑mail ? Il attrape les fautes évidentes comme l’absence d’un @, des espaces ou un format de domaine cassé. C’est utile, mais ce n’est qu’un test de format. Cela ne vous dit pas si l’adresse peut recevoir du courrier.
Quand le volume d’inscriptions augmente, les ratés pèsent plus que les détections. La regex ne peut pas vous dire si un domaine existe, s’il a des enregistrements MX fonctionnels, ou si une adresse appartient à une boîte jetable. Elle ne protège pas non plus contre les pièges à spam et d’autres adresses qui paraissent valides mais nuisent à la délivrabilité.
Les équipes apprennent généralement quelques leçons à la dure :
- Si vous êtes trop strict, vous bloquez des utilisateurs légitimes (y compris des adresses valides mais peu communes) et la conversion diminue discrètement.
- Si vous êtes trop laxiste, des comptes factices passent, la charge du support augmente et les rebonds s’accumulent.
- Avec le temps, les rebonds répétés et les plaintes peuvent abîmer la réputation d’expéditeur, ce qui dégrade la performance de chaque campagne.
C’est pour cela qu’un déploiement de validation en plusieurs étapes est important. Vous passez d’un simple test de motif à des contrôles superposés (syntaxe, domaine, MX et signaux de risque), mais vous le faites sans surprendre les vrais clients.
Un déploiement sûr poursuit trois objectifs : impact utilisateur minimal (pas de rupture brutale des inscriptions), progrès mesurable (métriques claires avant et après chaque changement) et un rollback simple (un interrupteur pour revenir au comportement précédent si la conversion ou la délivrabilité chute).
Ce plan s’adresse aux équipes produit, ingénierie et growth qui ont le même objectif : garder la friction d’inscription basse tout en réduisant les adresses invalides et la fraude. Des outils comme Verimail peuvent exécuter les contrôles multi‑étapes en un seul appel API, mais l’approche de déploiement reste la même quel que soit l’outil.
Définir objectifs, contraintes et responsabilités
Avant de modifier la validation, clarifiez ce que « bon » signifie pour votre activité. L’objectif n’est pas de bloquer des personnes. L’objectif est d’accepter des e‑mails réels et joignables tout en réduisant les inscriptions de faible qualité qui gaspillent du temps et nuisent à la délivrabilité.
Rédigez 2–3 résultats mesurables, par exemple moins d’adresses jetables à l’inscription, moins de rebonds durs dans la première semaine et moins de comptes créés pour abus. C’est aussi ici que vous décidez du niveau de sévérité pour les différents flux.
Objectifs et contraintes à approuver
Mettez en place quelques garde‑fous pour que la validation aide sans créer de nouveaux problèmes :
- Latence : pas de ralentissement perceptible sur les flux critiques (inscription, paiement).
- Conversion : pas de chute significative du taux d’achèvement après application.
- Charge support : garder les tickets « pourquoi mon e‑mail a été rejeté ? » prévisibles et rares.
- Équité : autoriser les cas limites légitimes (nouveaux domaines, serveurs mail d’entreprise, plus‑addressing).
- Conformité : stocker seulement ce qui est nécessaire (évitez de logger les e‑mails complets dans l’analytics si ce n’est pas indispensable).
Décidez ensuite où la validation s’exécute. La plupart des équipes commencent à l’inscription, mais les invitations, réinitialisations de mot de passe, reçus de paiement et utilisateurs créés par admin peuvent aussi introduire de mauvaises adresses. Une règle simple : valider partout où un nouvel enregistrement d’e‑mail est créé et garder l’expérience cohérente.
Responsabilités et droits de décision
Les contrôles multi‑étapes créent des décisions produit et support, pas seulement des tâches d’ingénierie. Accordez‑vous en amont sur qui est responsable de quoi :
- Produit : ce qui est bloqué vs signalé, et le texte du message d’erreur.
- Ingénierie : où les contrôles s’exécutent, timeouts, retries et comment les résultats sont mis en cache.
- Data/marketing : quelles métriques définissent le succès (réduction des rebonds, taux d’abus, délivrabilité).
- Support : un playbook court pour les overrides et les explications usuelles aux utilisateurs.
Si vous utilisez une API comme Verimail à l’inscription, décidez qui peut assouplir les règles si la conversion chute, et à quelle vitesse vous répondez quand un utilisateur légitime est bloqué.
À quoi ressemble la validation multi‑étapes en termes simples
La validation par regex, c’est vérifier si une clé a l’air correcte sans l’essayer dans la serrure. La validation multi‑étapes ajoute quelques vérifications rapides qui indiquent si une adresse est probablement réelle et joignable.
La première étape est la syntaxe, mais faite correctement. Un contrôle de syntaxe conforme aux RFC gère des formats que les regex basiques cassent souvent, comme le plus‑addressing ([email protected]), les points dans la partie locale et les TLD modernes plus longs. Il évite aussi les faux positifs qui correspondent au motif mais violent les règles d’e‑mail.
La seconde est la vérification du domaine. Si le domaine n’existe pas, personne ne peut recevoir de mail là‑bas. Une recherche DNS confirme que le domaine est réel, et un lookup MX vérifie si le domaine annonce des serveurs mail (ou a un routage équivalent). Cela attrape des fautes comme gmal.com et des domaines morts qu’une regex accepterait sans problème.
La troisième est la réputation et les signaux de risque. Cela inclut la détection des fournisseurs jetables et la comparaison avec des blocklists de sources connues malveillantes ou à risque.
Le but n’est pas de « bloquer plus ». C’est de choisir l’action adaptée selon le niveau de confiance :
- Autoriser : passe toutes les étapes.
- Avertissement doux : semble risqué, mais laisser l’utilisateur continuer.
- Exiger confirmation : accepter l’inscription, mais vérifier par e‑mail avant l’activation.
- Bloquer : clairement invalide, jetable (si votre politique le prévoit) ou à haut risque.
Prévoyez les cas limites comme les sous‑domaines (mail.eu.company.com), les passerelles d’entreprise qui routent le mail de manière inhabituelle, et les alias légitimes avec plus‑addressing. Des outils comme Verimail peuvent exécuter ces contrôles en un appel API, mais votre politique produit décide de l’action après chaque résultat.
Obtenir une ligne de base avant de changer quoi que ce soit
Avant un déploiement multi‑étapes, il vous faut une image claire du comportement actuel des inscriptions. Sans ligne de base, il est facile « d’améliorer » la validation tout en nuisant discrètement à la conversion, à la charge support ou à la délivrabilité.
Instrumentez l’ensemble du tunnel d’inscription et les résultats d’e‑mail de bout en bout. Mesurez non seulement combien d’utilisateurs terminent l’inscription, mais ce qui se passe après : les e‑mails de vérification arrivent‑ils, les utilisateurs s’activent‑ils, et des messages rebondissent‑ils ensuite ?
Suivez un petit ensemble de métriques de base pendant au moins 1 à 2 cycles business normaux (souvent 7 à 14 jours) :
- Taux de conversion à l’inscription (visite → compte créé)
- Taux de délivrance des e‑mails de vérification et temps de vérification
- Taux de rebond (dur et soft) sur vos premiers envois
- Taux de plainte (quand les fournisseurs signalent des problèmes)
- Tickets support liés à « je n’arrive pas à m’inscrire » ou « je n’ai jamais reçu l’e‑mail »
Si vous rejetez déjà certaines adresses (même avec une validation par regex), loggez chaque raison de rejet et le contexte : type de client, pays/locale, domaine et si l’utilisateur a réessayé avec une autre adresse. Les tickets support font aussi partie de la ligne de base, car des contrôles plus stricts peuvent déplacer la douleur des rebonds vers des utilisateurs bloqués.
Ensuite, créez un jeu de données labellisé à partir des inscriptions récentes. Une approche simple consiste à échantillonner les dernières semaines de nouveaux comptes et à étiqueter chaque e‑mail comme : accepté et actif, accepté mais rebondi plus tard, accepté mais a porté plainte, ou jamais vérifié. Cela devient votre « vérité terrain » pour comparer les nouveaux contrôleurs.
Enfin, décidez comment vous quantifierez les erreurs pendant le déploiement :
- Faux positifs : e‑mails légitimes bloqués ou retardés (surveillez les baisses de conversion et les pics de tickets).
- Faux négatifs : mauvais e‑mails autorisés (surveillez les rebonds, domaines jetables et signaux de piège à spam).
Quand vous testerez un valideur (par exemple Verimail en mode shadow), notez ses décisions par rapport à cette ligne de base afin que les changements soient mesurables et non anecdotiques.
Phase 1 : mode shadow pour apprendre sans casser l’inscription
Le mode shadow signifie que vous exécutez les nouveaux contrôles multi‑étapes sur chaque inscription, mais sans bloquer qui que ce soit. L’expérience utilisateur reste inchangée. Votre équipe obtient des données réelles sur ce que le validateur aurait fait, sans risquer la conversion.
Loggez les résultats pour chaque étape, pas seulement un simple pass/fail. Par exemple : résultat du contrôle de syntaxe, domaine existe‑t‑il, enregistrements MX trouvés, détecté comme jetable, et toute correspondance blocklist. Conservez aussi la décision ancienne (regex) à côté pour pouvoir comparer plus tard.
Un premier jalon utile consiste à répondre à trois questions avec des chiffres :
- Quelle part des inscriptions sont des e‑mails jetables ?
- Quelle part a des domaines invalides ou non résolus ?
- Quelle part semble risquée (par exemple, pièges suspects ou autres drapeaux) ?
Ces taux deviennent votre base pour le déploiement. Si vous utilisez une API de validation comme Verimail, stockez la réponse brute et votre décision interne finale séparément, afin de pouvoir modifier les règles plus tard sans perdre l’historique.
Choisissez un rythme de revue qui fait remonter les problèmes rapidement. Des revues quotidiennes la première semaine détectent généralement des surprises comme un pic provenant d’une source de trafic ou un domaine d’entreprise courant qui échoue les vérifications DNS pendant un incident temporaire. Après la première semaine, passez à l’hebdomadaire.
Un exemple concret : si votre regex accepte 98 % des inscriptions, mais que le mode shadow montre 6 % d’adresses jetables et 1 % de domaines invalides, vous avez désormais une cible claire pour ce que l’application pourrait économiser. Vous avez aussi une liste de cas limites à traiter doucement avant de bloquer de vrais utilisateurs.
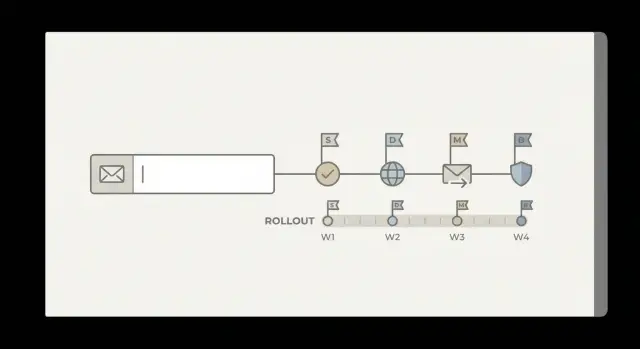
Phase 2 : application progressive avec jalons mesurables
Exécuter le mode shadow aujourd'hui
Voyez ce qui serait bloqué sans changer l'expérience d'inscription.
Après le mode shadow, passez à l’application par étapes petites et réversibles. L’objectif est de réduire les mauvais e‑mails sans surprendre les vrais utilisateurs ni nuire à la conversion.
Commencez par un segment étroit où le risque est faible et l’apprentissage élevé. Un choix courant : les nouvelles inscriptions venant de publicités payantes, de trafic d’affiliés ou d’un seul pays où vous observez plus d’adresses jetables. Laissez le reste du trafic inchangé pour pouvoir comparer les résultats.
Commencez par des actions à faible risque avant de bloquer fermement. Si la validation signale une adresse comme jetable ou injoignable, affichez un court message demandant à l’utilisateur de vérifier et d’essayer un autre e‑mail. Facilitez la modification et la reprise. Ne passez au blocage strict que lorsque vous êtes sûr de ne pas attraper des utilisateurs légitimes.
Un plan de montée simple :
- Appliquer à 5 % du segment choisi, surveiller les métriques 24–48 heures.
- Monter à 25 % si les conditions d’arrêt ne sont pas atteintes.
- Monter à 50 %, puis 100 % pour ce segment.
- Étendre au segment suivant (autre canal ou pays) et répéter.
- Quand tout est stable, appliquer à toutes les nouvelles inscriptions.
Définissez des conditions d’arrêt à l’avance et consignez‑les. Exemples : la conversion chute de plus de X %, le temps médian d’inscription augmente de Y secondes, les contacts support liés à l’inscription dépassent Z par jour, ou les rebonds ne s’améliorent plus.
Suivez des jalons reflétant à la fois l’expérience utilisateur et la valeur business : taux de conversion, temps pour compléter l’inscription, combien d’utilisateurs réessaient avec un nouvel e‑mail, volume support, et taux de rebond des e‑mails de bienvenue. Si vous utilisez une API comme Verimail, surveillez aussi comment les taux « invalides » et « jetables » évoluent pendant la montée.
Traitez chaque montée comme un point de décision avec un seuil clair pour avancer, tenir ou revenir en arrière. Cela garde le déploiement calme et simple à expliquer entre produit, ingénierie et support.
Métriques et tableaux de bord qui détectent vraiment les régressions
Si vous ne regardez que « les inscriptions ont augmenté ou diminué », vous manquerez l’impact réel des changements de validation. Construisez un tableau de bord pour la santé immédiate des inscriptions, et une seconde vue qui suit ces utilisateurs dans la livraison d’e‑mails et les résultats d’abus.
Choisissez un petit ensemble de métriques primaires que vous traiterez comme décisions. Gardez‑les visibles sur chaque graphique et évitez d’en ajouter tellement que personne ne sait ce qui compte.
Ces cinq métriques disent généralement la vérité rapidement :
- Taux de conversion aux inscriptions (inscriptions complétées / inscriptions commencées)
- Taux d’e‑mails invalides ou injoignables (résultats de validation plus rebonds ultérieurs)
- Taux d’e‑mails jetables (et son évolution par canal)
- Signaux d’abus (plaintes spam, inscriptions suspectes, détournements de compte liés aux nouveaux comptes)
- Résultats de livraison après inscription (taux de rebond, taux de plainte, indicateurs d’arrivée en boîte de réception si vous en disposez)
Ajoutez des garde‑fous avant d’appliquer quoi que ce soit. Utilisez des seuils, pas l’intuition : par exemple « pas plus de 0,5 % de baisse absolue de conversion » et « pas plus de 50 ms ajoutés de latence au p95 ». Si un garde‑fou saute, mettez le déploiement en pause et investiguez.
Coupez chaque métrique par cohorte pour repérer les échecs localisés : canal d’acquisition, pays, type d’appareil, catégorie de domaine (fournisseurs gratuits vs domaines pro). Une régression fréquente est de bloquer trop sévèrement dans une géographie ou sur mobile, où les fautes de frappe sont plus courantes.
Revoyez les cas limites chaque semaine. Prélevez un petit échantillon d’adresses « risquées mais pas clairement mauvaises » et vérifiez si de vraies personnes se font bloquer. Si vous utilisez une API comme Verimail, loggez les codes de raison (syntaxe, MX, bloclist) pour voir quelle étape cause la friction et ajuster les règles sans deviner.
Contournements, rollbacks et options UX sûres
Repérer les adresses risquées tôt
Ajoutez des signaux de blocklist pour détecter tôt les adresses risquées.
La validation multi‑étapes attrape plus de mauvaises inscriptions, mais elle peut aussi bloquer de vrais utilisateurs si quelque chose change (pannes DNS, nouveaux domaines d’entreprise, problèmes temporaires de routage). Planifiez les échecs avant d’activer l’application.
Commencez par un kill switch qui vous ramène instantanément au comportement regex‑seul. Faites‑le côté serveur, pas au niveau déploiement. Associez‑le à des feature flags pour chaque type de règle afin de désactiver une partie sans tout perdre : gestion MX, blocage d’adresses jetables et matches blocklist.
Quand vous bloquez ou challengez un utilisateur, choisissez un contournement qui permet de continuer l’inscription tout en protégeant la plateforme. Options efficaces :
- Autoriser l’inscription, mais exiger la confirmation par e‑mail avant connexion ou avant d’activer des actions clés.
- Autoriser l’inscription, mais limiter certaines fonctionnalités (parrains, coupons, clés API, crédits d’essai) tant que l’e‑mail n’est pas vérifié.
- Placer le compte en mode restreint pendant que vous revérifiez l’e‑mail après quelques minutes.
- Demander un autre e‑mail seulement lorsque le signal est fort (fournisseur jetable connu, problèmes de syntaxe évidents).
Avec toute API de validation d’e‑mails, les faux positifs sont le plus grand risque du déploiement. Traitez‑les comme des incidents. Définissez qui est alerté, à quelle vitesse, et ce que signifie « arrêter l’hémorragie » (souvent basculer le kill switch ou désactiver d’abord le flag le plus strict). Gardez la communication interne simple : ce qui a cassé, qui est impacté et ce que vous avez changé.
Un playbook d’incident léger peut être petit :
- Confirmer le pic (inscriptions bloquées, tickets support, chute de conversion).
- Désactiver le flag le plus probable (jetable ou blocklist) avant d’éteindre tout.
- Récupérer des exemples d’adresses bloquées et vérifier les motifs (domaine, région, fournisseur).
- Décider si c’est une panne temporaire ou un problème de règles.
- Documenter la correction et ajouter un test ou un monitor pour détecter plus tôt la prochaine fois.
Enfin, maintenez un processus d’autorisation (allowlist) pour les domaines importants (partenaires, gros clients). Exigez un responsable, une raison et une trace d’audit, et révisez les entrées régulièrement pour que les exceptions ne s’accumulent pas en silence.
Pièges courants pendant la migration
La plupart des problèmes de migration ne viennent pas du validateur lui‑même. Ils proviennent de traiter des signaux précoces comme une vérité finale, puis d’appliquer trop vite. Un déploiement sûr doit laisser de la place à l’incertitude.
Une erreur fréquente est de bloquer des inscriptions parce que le DNS a été instable pendant une minute. Les vrais utilisateurs ne contrôlent pas leurs résolveurs DNS, le Wi‑Fi d’un hôtel ou les pare‑feu d’entreprise. Si votre système ne fait qu’un seul lookup et échoue en fermant, vous rejetterez de bons e‑mails. Mettez en cache les vérifications de domaine quand c’est possible, réessayez avec un court délai et loggez la raison pour voir si les échecs se regroupent par région ou ISP.
Un autre piège est de supposer que « pas de MX » signifie toujours « invalide ». Certains domaines acceptent le mail sur l’enregistrement A racine, et certaines configurations sont inhabituelles mais réelles. Si vous traitez chaque « pas de MX » comme un arrêt dur, vous créerez des faux positifs. Considérez‑le comme un signal de risque sauf si vous avez des preuves solides d’injoignabilité.
Le blocage d’adresses jetables coince aussi les équipes. Si votre produit a des cas d’usage légitimes à court terme (essais, téléchargements ponctuels, inscriptions à un événement), un blocage strict peut nuire à la conversion. Plutôt qu’un bannissement global, décidez ce que vous protégez : abus, rétrofacturations, délivrabilité, ou tout cela.
Quelques schémas d’échec reviennent souvent dans les postmortems :
- Ne pas séparer « définitivement invalide » de « impossible à vérifier pour l’instant »
- Appliquer des règles globales avant de tester par segment (pays, source de trafic, appareil)
- Lancer sans scripts de support et messages utilisateurs clairs
- Traiter les erreurs DNS temporaires comme des échecs de domaine permanents
- Bloquer des domaines jetables sans plan d’exceptions adapté au produit
Un exemple réaliste : vous déployez dans tous les marchés un lundi, des timeouts DNS augmentent dans une région et le support voit des tickets « mon e‑mail est réel » en quelques heures. Si vous aviez un chemin « réessayer » pour « impossible à vérifier maintenant » et un déploiement par segment, vous auriez pu laisser passer les inscriptions pendant l’investigation.
Checklist rapide de déploiement
Avant d’appliquer quoi que ce soit, assurez‑vous de pouvoir prouver si le changement a aidé ou nui. Le déploiement est le plus sûr quand chaque étape a un responsable clair, un objectif mesurable et un moyen simple de l’annuler.
Utilisez cette checklist juste avant de passer des tests à l’application réelle :
- La ligne de base est capturée et stable : vous avez au moins quelques jours (ou semaines) de conversion d’inscription, taux de rebond des e‑mails et tickets « e‑mail invalide » suivis au même endroit, et vous connaissez la plage normale.
- Les résultats du mode shadow sont revus et les décisions écrites : vous avez examiné ce que le validateur aurait bloqué, vérifié un échantillon de cas limites (domaines d’entreprise, TLD inhabituels) et convenu de seuils (quand bloquer vs avertir).
- Feature flags et kill switch sont prouvés en production : vous pouvez activer ou désactiver la validation instantanément sans déploiement, et vous avez testé le chemin « off » sur du trafic réel (pas seulement en staging). Si vous appelez une API comme Verimail, incluez des timeouts et un comportement par défaut sûr.
- Le support est prêt pour les premières plaintes : vous avez des réponses pré‑rédigées courtes pour « pourquoi mon e‑mail est rejeté ? », un moyen de collecter des exemples et une voie d’escalade claire vers l’ingénieur responsable du déploiement.
- Le calendrier et les conditions d’arrêt sont documentés : vous avez un calendrier de montée, des propriétaires nommés pour chaque étape et des raisons spécifiques pour mettre en pause (par exemple, la conversion chute de plus de X % pendant Y heures, ou les faux rejets dépassent un certain nombre).
Quand tout cela est en place, le déploiement devient routinier : activez le pourcentage suivant, surveillez les mêmes métriques et stoppez rapidement si les utilisateurs souffrent.
Un scénario de déploiement réaliste
Réduire les rebonds rapidement
Écartez les adresses invalides avant qu'elles n'altèrent la délivrabilité et la réputation d'expéditeur.
Une application SaaS de taille moyenne commence à constater deux problèmes simultanés : plus d’essais frauduleux (comptes créés qui ne se reconnectent jamais) et une hausse du taux de rebond sur les e‑mails d’onboarding. Leur formulaire d’inscription n’utilise que la validation par regex, donc presque tout ce qui ressemble à un e‑mail passe.
Ils ajoutent la validation multi‑étapes en mode shadow d’abord. Les inscriptions fonctionnent exactement pareil, mais chaque adresse soumise est vérifiée en arrière‑plan pour la syntaxe, le domaine, les MX et les fournisseurs jetables connus. Après deux semaines, l’équipe analyse et identifie deux motifs : une large part des nouveaux essais utilisent des domaines jetables, et un plus petit groupe utilise des domaines qui n’acceptent pas le mail (MX manquant, domaines parqués ou fautes de frappe communes).
Avec ces données, ils passent à une application progressive avec des jalons simples :
- Semaine 1 : afficher un avertissement poli pour les e‑mails jetables et demander une boîte pro ou personnelle.
- Semaine 2 : bloquer uniquement les cas clairement invalides (domaine cassé, DNS absent), tout en autorisant le reste.
- Semaine 3 : bloquer les schémas d’abus répétés (par ex. multiples inscriptions depuis la même source utilisant différentes adresses jetables).
Ils ajoutent aussi un contournement sûr pour les cas incertains. Si la vérification n’est pas confiante, l’utilisateur peut quand même s’inscrire, mais doit confirmer son e‑mail avant d’accéder aux fonctionnalités clés. Cela permet aux vrais utilisateurs d’avancer tout en filtrant les inscriptions de faible qualité.
À la fin du déploiement, l’équipe cherche un résultat par‑dessus tout : les rebonds diminuent sans impact significatif sur les démarrages d’essais ou l’activation. Si les rebonds d’onboarding chutent et que les essais activés restent stables, ils durcissent la politique sur les adresses jetables. Si la conversion baisse, ils assouplissent l’application et s’appuient davantage sur la confirmation jusqu’à avoir affiné les règles.
Étapes suivantes : implémenter, ajuster et continuer d’améliorer
La validation multi‑étapes ne paraît risquée que lorsque les règles sont vagues. Choisissez une première règle d’application qui soit à la fois peu risquée et à forte valeur. Pour beaucoup d’équipes, cela signifie bloquer les domaines clairement invalides (pas de DNS) et gérer les fournisseurs jetables selon la politique produit.
Rédigez une courte politique interne pour que tout le monde sache ce que « valide » signifie dans votre produit :
- Bloquer : évidents invalides (syntaxe cassée, domaine mort, domaines jetables si votre produit dépend d’une identité réelle)
- Avertir : risqué mais possible (fautes de frappe, domaines catch‑all, hôtes mail temporaires que vous n’êtes pas prêt à bloquer)
- Autoriser : tout le reste, mais étiquetez‑le pour pouvoir mesurer les résultats plus tard
Puis choisissez un validateur capable d’exécuter rapidement des contrôles multi‑étapes (syntaxe, domaine, MX et détection d’adresses jetables) et de renvoyer des codes de raison que vous pouvez logger. Si vous évaluez Verimail (verimail.co), il est conçu pour ce style de déploiement : un appel API couvre syntaxe, vérification de domaine, lookup MX et détection jetable, et vous pouvez commencer en mode shadow avant d’appliquer quoi que ce soit.
Planifiez une revue post‑déploiement (par exemple 7–14 jours après le début de l’application). Apportez un petit lot d’e‑mails contestés, cherchez des faux positifs et ajustez les seuils ou la allowlist. Un bon déploiement n’est pas un simple interrupteur : c’est un ensemble de règles vivant qui évolue avec vos schémas d’inscription.
FAQ
Pourquoi la validation par regex seule n’est-elle pas suffisante ?
Un contrôle par regex indique seulement si une saisie ressemble à une adresse e-mail. Il ne peut pas confirmer que le domaine existe, que le domaine peut recevoir du courrier, ni si l'adresse provient d'un fournisseur jetable. Les adresses problématiques passent donc toujours et réapparaissent ensuite sous forme de rebonds et de plaintes.
Que comprend généralement la « validation d’e-mails multi-étapes » ?
Commencez par des contrôles en couches qui répondent à différentes questions : syntaxe conforme aux RFC, existence du domaine via DNS, enregistrements MX (ou routage équivalent) et signaux de risque comme les fournisseurs jetables et sources connues problématiques. Traitez la sortie comme un signal de confiance, puis décidez d’autoriser, d’avertir, d’exiger une confirmation ou de bloquer.
Comment ajouter la validation multi-étapes sans nuire à la conversion à l'inscription ?
Utilisez le mode shadow : exécutez le nouveau validateur sur chaque inscription sans modifier ce que voit l’utilisateur. Enregistrez chaque résultat d’étape et comparez-le à ce que votre regex ferait aujourd’hui, afin de comprendre l’impact réel avant toute mise en application.
Quelles métriques devons‑nous surveiller pendant un déploiement ?
Au minimum, suivez la conversion aux inscriptions, le taux de livraison des e-mails de vérification, le taux de rebond initial sur vos premiers envois, le taux de plainte et les tickets support liés à l’inscription ou aux e-mails manquants. Analysez par cohorte (canal, pays, appareil, type de domaine) pour détecter les régressions affectant seulement une partie des utilisateurs.
Quelle est la meilleure première règle à appliquer après le mode shadow ?
Une première règle sûre est de bloquer les saisies clairement invalides : syntaxe cassée ou domaines inexistants, car ces utilisateurs ne peuvent pas recevoir d’e-mails. Pour les cas incertains, préférez un avertissement ou un flux « inscrivez‑vous maintenant, vérifiez avant l’accès » jusqu’à obtenir assez de données pour durcir les règles.
Devons‑nous bloquer les e-mails si un domaine n’a pas d’enregistrement MX ?
Considérez « pas de MX » comme un signal de risque, pas comme une erreur automatique. Certains domaines acceptent le courrier via d’autres configurations, et un blocage strict peut générer des faux positifs ; une option plus sûre est d’autoriser avec confirmation par e-mail requise ou un avertissement doux, sauf si vous avez des preuves solides que le domaine est injoignable.
Comment monter en charge l’application des règles en toute sécurité ?
Utilisez un déploiement progressif segmenté avec feature flags et conditions d’arrêt pré-écrites. Par exemple, appliquez la règle d’abord à un canal ou une région, augmentez progressivement les pourcentages et mettez en pause ou revenez en arrière si la conversion chute au‑delà de votre seuil ou si les tickets support explosent.
Quel plan de rollback devons‑nous avoir avant d’appliquer quoi que ce soit ?
Préparez un kill switch côté serveur qui vous ramène instantanément au comportement précédent sans déploiement. Séparez aussi les flags par type de règle (gestion MX, blocage d’adresses jetables, contrôles blocklist) pour pouvoir désactiver la règle la plus problématique en priorité au lieu d’éteindre tout le système.
Quelles solutions de contournement conviviales utiliser à la place d’un blocage strict ?
Faites avancer l’inscription tout en réduisant le risque : autorisez la création de compte mais exigez la confirmation avant la connexion ou limitez les fonctionnalités à risque jusqu’à vérification. Rédigez un message d’erreur court et précis, et offrez un moyen simple d’éditer l’adresse et de réessayer.
Que rechercher dans une API de validation d’e‑mails comme Verimail ?
Choisissez un validateur qui renvoie des codes de raison clairs à logger (syntax, DNS, MX, disposable, blocklist) et qui répond assez vite pour l’inscription. Verimail est un exemple conçu pour ce type de déploiement : un seul appel API peut couvrir syntaxe, vérification de domaine, lookup MX et détection d’adresses jetables, et permet de démarrer en mode shadow avant d’appliquer des règles.