À quoi ressemble la limitation de débit dans de vraies applications
La limitation de débit est simple : une API limite combien de requêtes vous pouvez envoyer dans une courte fenêtre. Les fournisseurs font cela pour garder les services stables, prévenir les abus et éviter qu'un client bruyant n'accapare la capacité partagée.
La plupart des équipes ne remarquent les limites que lors de pics : une campagne part, un partenaire lance quelque chose, ou un bot commence à frapper votre formulaire d'inscription. Si vous validez les e‑mails pendant l'inscription (par exemple en appelant Verimail pour bloquer les adresses jetables ou invalides), ces rafales peuvent vous faire dépasser le seuil.
Pour les utilisateurs, cela ressemble souvent à une application instable, pas à une « limitation de débit ». Vous verrez des inscriptions plus lentes, des erreurs aléatoires « réessayez » qui disparaissent au rafraîchissement, des e‑mails de vérification qui n'arrivent pas parce que l'adresse n'a jamais été acceptée, et des tickets de support au contenu incohérent.
Le piège vient ensuite. Un client naïf voit une erreur et relance immédiatement, parfois avec plusieurs relances en parallèle. Sous limitation de débit, cela aggrave le problème. Vous ajoutez du trafic au moment même où l'API vous demande de ralentir, et un petit incident peut se transformer en minutes de perturbation.
Un client résilient suppose que ces moments arriveront et réagit calmement : il ralentit volontairement, relance seulement quand c'est logique (et seulement quelques fois), évite le travail en double quand la même action utilisateur est relancée, et empêche qu'une dépendance en difficulté ne se transforme en incident site‑entier.
Les limites de débit sont normales. La différence entre une inscription fluide et un incident tient surtout à la façon dont votre client se comporte après le premier 429.
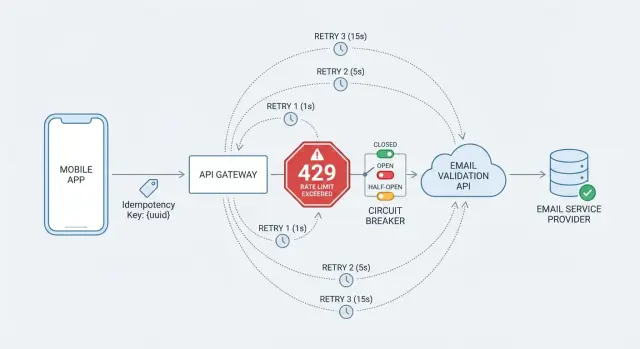
Lisez les signaux : 429, Retry-After et timeouts
Quand vous touchez une limite, le serveur vous envoie un signal de contrôle : vous envoyez des requêtes plus vite qu'il ne souhaite en accepter pour l'instant. Considérez cela comme un retour normal, pas comme une erreur générique.
Les signaux que vous verrez le plus souvent sont :
- HTTP
429 (Too Many Requests)
- Timeouts de requête
- Erreurs réseau comme des réinitialisations de connexion
Ils peuvent sembler similaires dans les tableaux de bord, mais ils demandent des traitements différents.
429 et en‑têtes utiles
Une réponse 429 est le cas le plus clair parce qu'elle est explicite. Si l'API inclut un en‑tête Retry-After, traitez‑le comme la meilleure instruction disponible pour savoir quand réessayer. Certaines API fournissent aussi des indices de quota comme le nombre de requêtes restantes ou l'heure de réinitialisation, mais n'utilisez ceux‑ci que s'ils sont documentés.
Une règle de décision qui vous protège :
429 avec Retry-After : attendez ce délai (plus un petit jitter aléatoire), puis relancez.429 sans Retry-After : relancez avec backoff exponentiel et jitter, avec un plafonnement strict du temps total d'attente.429 répétés : arrêtez de relancer et échouez rapidement pendant une courte période (un circuit breaker aide ici).
Timeouts et erreurs de connexion
Les timeouts et les erreurs de connexion signifient généralement une surcharge, des réseaux instables ou une mauvaise configuration côté client. Contrairement au 429, il n'y a pas forcément de temps d'attente « correct ». Les relances peuvent aider, mais seulement avec des limites strictes.
Consignez les événements de limitation de débit séparément des autres erreurs. Un 429 n'est pas la même chose qu'un « e‑mail invalide » ou qu'« API indisponible ». Si vous les mélangez, vous réglerez mal les relances et perdrez du temps à chercher une mauvaise cause.
Dans un flux d'inscription qui appelle une API comme Verimail, prévoyez un repli gracieux. Si la validation est temporairement bloquée, vous pouvez la mettre en file pour plus tard, afficher un message clair, ou accepter l'adresse et vérifier ensuite. Le bon choix dépend si la validation est un blocage obligatoire ou un contrôle qualité.
Fixez des objectifs avant d'ajouter des relances
Les relances semblent inoffensives : si une requête échoue, réessayez. En pratique, les relances affectent la rapidité des inscriptions, la qualité des données et la pression exercée sur le fournisseur.
Décidez ce que « succès » signifie pour votre formulaire. Pendant l'inscription, la plupart des équipes préfèrent une expérience rapide et prévisible plutôt qu'une certitude parfaite. Si la validation est lente ou limitée, vous pouvez accepter l'e‑mail et le vérifier plus tard au lieu de bloquer l'utilisateur.
Avant de modifier le code, notez quelques règles :
- Expérience utilisateur : Combien de temps la validation peut‑elle ajouter (par exemple 200–500 ms), et que se passe‑t‑il quand ce budget est dépassé ?
- Sécurité : Quelles actions ne doivent jamais se produire deux fois (création de comptes, envoi d'e‑mails de bienvenue, démarrage d'essais) ?
- Charge : Combien de tentatives de relance sont permises, et quel est le temps maximum total consacré aux relances ?
- Supportabilité : Que verra le support dans les logs, et pourra‑t‑il l'expliquer à un client ?
- Repli : Quel est le comportement sûr sous pression (bloquer, accepter, ou mettre en file) ?
Ces objectifs vous empêchent de relancer indéfiniment, ce qui transforme souvent un pic bref en une panne plus longue.
Exemple : votre formulaire d'inscription appelle Verimail pour filtrer les e‑mails jetables. Si l'API ralentit, votre règle pourrait être « ne jamais retarder l'inscription plus d'1 seconde ». Cela implique un timeout court, au plus une ou deux relances, puis un repli (par exemple accepter l'e‑mail mais le marquer pour revue ultérieure).
Étape par étape : implémenter backoff et jitter
Les relances n'aident que lorsqu'elles sont contrôlées. Si vous relancez trop vite ou trop longtemps, vous pouvez transformer un petit ralentissement en un problème plus vaste.
1) Fixez d'abord un petit budget
Choisissez deux limites : un nombre maximal de relances et un budget de temps total. Le budget temps compte davantage parce que le backoff croît rapidement.
Pour une vérification interactive lors de l'inscription, un point de départ pratique est 2–3 relances en 1–2 secondes au total. Pour des tâches en arrière‑plan, vous pouvez laisser plus de temps car l'utilisateur n'attend pas.
2) Utilisez le backoff exponentiel, puis ajoutez du jitter
Le backoff exponentiel signifie que vous attendez plus longtemps après chaque échec. Le jitter randomise cet attente pour que des milliers de clients ne relancent pas en même temps.
Un schéma simple :
- Tentez la requête.
- Si elle échoue avec une erreur réessayable (comme
429 ou un timeout transitoire), calculez le délai suivant.
- Délai = min(maxDelay, baseDelay * 2^attempt) + random(0, jitterRange).
- Attendez, puis réessayez jusqu'à consommation du budget temps.
Si le serveur envoie Retry-After, considérez‑le comme un délai minimum. Si votre backoff dit 400 ms mais Retry-After indique 2 s, attendez 2 s.
Si Verimail renvoie un 429 durant un pic d'inscriptions, respecter Retry-After plus un jitter aide à lisser le trafic au lieu de marteler l'API.
3) Adaptez les réglages selon la charge
N'utilisez pas une seule politique de relance pour tout. Le trafic d'inscription et les jobs en arrière‑plan ont des objectifs différents.
Restez simple :
- Interactif (inscription) : peu de relances, budget temps serré, repli rapide.
- Jobs en arrière‑plan : plus de relances, budget temps plus long.
- Imports par lot : cadence régulière pour éviter les rafales.
L'idée est de garder l'expérience utilisateur réactive tout en restant poli sous charge.
Idempotence et dédoublonnage pour que les relances ne créent pas de doublons
Les relances sont les plus sûres quand l'appel est en lecture seule. La validation d'e‑mail l'est généralement : vous posez une question et obtenez une réponse. Même alors, les appels en double sont problématiques. Ils gaspillent du quota, alourdissent la latence et compliquent les logs quand une action utilisateur déclenche plusieurs validations.
Si votre fournisseur supporte des clés d'idempotence, utilisez‑les pour tout endpoint qui pourrait avoir des effets de bord (par exemple, des flux « valider et stocker »). Une clé d'idempotence peut être un UUID par action utilisateur ou une empreinte stable comme le hash de l'e‑mail normalisé plus une fenêtre temporelle. Si les clés ne sont pas supportées, vous pouvez quand même obtenir la plupart des bénéfices côté client.
Une approche pratique combine trois couches :
- Normalisez et créez une empreinte de l'e‑mail (trim, minuscules, suppression des espaces évidents) pour que la même saisie corresponde à la même clé.
- Maintenez un cache court‑terme (souvent 1–10 minutes) pour que les vérifications répétées n'appellent pas l'API à nouveau.
- Dédoublez les requêtes en vol : si plusieurs parties de l'app valident le même e‑mail en même temps, elles doivent attendre la même promesse, pas déclencher plusieurs appels réseau.
Faites attention à ce que vous mettez en cache. Les résultats « valides » et « invalides » sont généralement sûrs à réutiliser brièvement. Les échecs temporaires, non. Si vous obtenez un timeout, un 429 ou une réponse « inconnue », mettez‑les en cache pour quelques secondes (ou pas du tout) pour ne pas figer un mauvais résultat.
Exemple : lors d'un pic, un utilisateur double‑clique sur « Créer un compte » et le frontend lance aussi une vérification en arrière‑plan. Avec empreinte et dédoublonnage en vol, vous n'effectuez qu'un seul appel à Verimail, et les relances ne multiplient pas le trafic.
Savoir quand relancer vs quand échouer
Les relances aident quand le problème est temporaire. Elles nuisent quand la requête ne réussira jamais.
Relancez seulement quand une nouvelle tentative pourrait fonctionner. Cela inclut typiquement les réponses 429, les timeouts réseau, les réinitialisations de connexion et beaucoup d'erreurs 5xx côté serveur. Si vous recevez un 429, respectez Retry-After s'il est présent.
Ne relancez pas les requêtes invalides. Si l'API dit que votre payload est invalide, que des paramètres manquent ou que l'auth est incorrecte, relancer répète juste la même erreur.
Un filtre de décision simple :
- Relancer :
429, timeouts, réinitialisations de connexion, 5xx (sauf cas que vous savez permanents)
- Échouer rapidement : 4xx de validation d'entrée, 401/403 erreurs d'auth, champs requis manquants
- Arrêter les relances quand votre budget temps est atteint (par exemple 2–3 secondes pour l'inscription)
Parfois, le meilleur résultat est « continuer sans réponse validée ». Lors d'un pic, vous pouvez laisser l'inscription se terminer, stocker un drapeau email_status = needs_review, et lancer une revalidation en arrière‑plan.
Soyez explicite sur les échecs partiels. Si la validation est sautée, enregistrez ce qui s'est passé (code d'erreur, horodatage, nombre de relances) et n'interprétez pas l'e‑mail comme « vérifié » plus tard.
Ajoutez un circuit breaker pour prévenir les pannes en cascade
Les relances aident quand une panne est brève. Mais si l'API de validation est lente ou en échec pendant des minutes, les relances s'accumulent et peuvent ralentir tout votre flux d'inscription. Un circuit breaker arrête d'appeler l'API quand les échecs montent en flèche pour que votre app reste réactive.
Un breaker a trois états :
- Closed : les appels passent normalement.
- Open : vous cessez d'appeler l'API pendant une période de refroidissement parce que les appels récents ont trop échoué.
- Half‑open : vous autorisez quelques appels d'essai. S'ils réussissent, vous fermez le breaker. S'ils échouent, vous l'ouvrez à nouveau.
Seuils de départ qui fonctionnent pour beaucoup d'équipes :
- Ouvrir après 5–10 échecs consécutifs, ou un taux d'échec de 50 % sur les 20–50 derniers appels
- Temps de refroidissement de 15–60 secondes
- En half‑open, autoriser 1–5 appels d'essai avant de décider
Quand le breaker est ouvert, décidez ce que fait votre app. Pour l'inscription, vous pouvez accepter l'e‑mail mais le marquer « needs verification » et vérifier plus tard. Pour des flux à plus haut risque, affichez un message clair indiquant que la vérification est temporairement indisponible.
La limitation de débit et les circuit breakers résolvent des problèmes différents. La limitation de débit, c'est l'API qui vous dit de ralentir (souvent avec 429 et Retry-After). Un circuit breaker, c'est votre client qui choisit de faire une pause parce que les résultats récents montrent un problème, même si vous n'êtes pas explicitement limité.
Monitoring et réglage qui aident vraiment
Les relances et les breakers n'agissent que si vous voyez ce qu'ils font.
Suivez un petit ensemble de métriques qui racontent l'histoire dans le temps :
- Nombre de relances par requête (et % de requêtes qui relancent)
- Temps total de backoff ajouté par requête
- Taux de
429 (et fréquence d'apparition de Retry-After)
- Taux de succès (2xx) et taux d'échec dur (4xx non relancés)
- Latence de bout en bout (p50/p95) pour la validation, incluant les relances
Les logs comptent autant que les graphiques. Pour chaque tentative de validation, logguez un identifiant de requête et le résultat final. Si l'API renvoie son propre ID de requête, conservez‑le aussi. Gardez les logs respectueux de la vie privée : hash de l'e‑mail et vous pouvez toujours dépanner les doublons.
Les alertes doivent se concentrer sur les changements soutenus, pas sur le bruit normal. Quelques 429 pendant une heure chargée peuvent être acceptables. Un pic qui dure 10 minutes signifie généralement un changement dans les motifs de trafic, des relances trop agressives, ou un breaker qui reste ouvert.
Testez aussi sous charge. Simulez des inscriptions en rafale et des réseaux lents, pas seulement les chemins heureux. Même si votre fournisseur répond d'habitude en millisecondes, vos timeouts et limites de relance doivent supposer que l'internet peut être capricieux.
Si possible, rendez les principaux paramètres ajustables sans redeploiement : max retries, base backoff, timeout, et seuils du breaker. Cela permet d'apaiser rapidement la situation lors d'un pic.
Exemple : pic de trafic pendant les inscriptions
Une campagne payante déclenche un trafic d'inscription multiplié par 10 en une heure. Votre app valide chaque e‑mail à l'arrivée, appelant Verimail dans le flux d'inscription. Tout semble bien au départ, puis des cas limites apparaissent : plus de requêtes concurrentes, quelques timeouts, et quelques 429.
Sans protection, beaucoup de clients relancent immédiatement. Quand des centaines de requêtes échouent en même temps, elles relancent ensemble. Cela crée un thundering herd et fait échouer la vague suivante aussi, même si l'API aurait pu récupérer avec un peu d'air.
Avec backoff et jitter, les relances se répartissent. Même un plan simple aide :
- Première relance après ~200–400 ms (randomisé)
- Deuxième relance après ~800–1200 ms
- Arrêter après 2–3 relances pour le trafic d'inscription
L'idempotence et le cache réduisent encore le volume d'appels. Lors des pics, la même adresse est souvent soumise deux fois (double‑clics, resoumissions, utilisateurs sur plusieurs appareils). Une fenêtre de cache courte (par exemple 10–30 minutes) basée sur l'e‑mail normalisé vous permet de répondre aux répétitions sans frapper l'API à nouveau. Associez‑cela à une clé d'idempotence pour l'action d'inscription afin qu'une relance n'engendre pas d'enregistrements d'utilisateur en double.
Un circuit breaker garde votre site réactif quand les échecs s'accumulent. Si les 429 et les timeouts franchissent un seuil, ouvrez le breaker pour une courte période et sautez les appels de validation temporairement. L'inscription peut toujours se poursuivre en marquant l'e‑mail comme « pending verification » et en validant en arrière‑plan quand le breaker se referme.
Liste de contrôle avant mise en production
Avant d'activer les relances en production, définissez ce qu'est un « bon comportement » sous charge. Le but est de maintenir le flux d'inscription et d'éviter qu'un court ralentissement ne devienne une panne plus large.
- Respectez
Retry-After et plafonnez le temps de relance. Suivez Retry-After quand il est présent, et fixez une limite dure sur le temps total de relance pour qu'une requête ne bloque pas votre système.
- Ne relancez pas les erreurs que vous avez causées. Si l'API renvoie un 4xx clair pointant une entrée invalide, relancer est vain. Corrigez l'entrée et retournez un message utile.
- Dédupliquez les recherches répétées. Ajoutez une courte fenêtre de cache pour que les répétitions réutilisent le premier résultat.
- Fixez des règles de breaker et un repli. Choisissez des seuils et décidez ce qui se passe quand le breaker s'ouvre (accepter et marquer, mettre en file, ou bloquer les flux à haut risque).
- Facilitez le débogage des échecs. Logguez le résultat (succès,
429, timeout), le nombre de relances, le temps total d'attente, et si le breaker était ouvert.
Simulez un petit pic en staging et confirmez que le service reste réactif pendant que le client recule poliment. Si vous utilisez Verimail ou un fournisseur similaire, le même schéma s'applique : respectez les signaux, limitez les relances, et rendez le chemin d'abandon prévisible.
Étapes suivantes : faire de la résilience le comportement par défaut
Considérez la gestion des relances et des limites de débit comme une fonctionnalité produit, pas un rustine rapide. Commencez prudemment, surveillez la production, et ajustez selon les métriques. Les équipes se mettent souvent en difficulté quand les relances sont trop agressives et amplifient un ralentissement.
Un plan pratique :
- Conservez peu de relances (souvent 2–3) avec backoff exponentiel et jitter, et respectez
Retry-After.
- Ajoutez du dédoublonnage pour tout flux susceptible de créer des doublons.
- Définissez des règles d'arrêt : quelles relances, quels échecs rapides, et quand basculer sur « réessayer plus tard ».
- Écrivez le comportement en langage clair pour le produit et le support (ce que voit l'utilisateur, ce qui est loggué, et quand la validation est différée).
- Ajoutez des tableaux de bord et des alertes pour les
429 soutenus, l'augmentation des timeouts, et le temps durant lequel le breaker est ouvert.
Si les vérifications d'e‑mail sont critiques pour votre activité, il aide aussi d'utiliser un validateur conçu pour faible latence et fort volume. Verimail (verimail.co) exécute des contrôles conformes aux RFC sur la syntaxe, la vérification de domaine et MX, et la détection d'adresses jetables/blocklist en un seul appel API, ce qui réduit la probabilité que votre client entre dans le chemin « relance ».
Planifiez des revues régulières à mesure que les motifs de trafic changent. Réexaminez les seuils, mettez à jour la gestion des domaines jetables, et confirmez que votre comportement face aux limites de débit correspond toujours au comportement réel des utilisateurs et aux besoins du support.