21 oct. 2025·8 min
Mesures de la qualité des e‑mails à suivre dans le temps (et pourquoi)
Les métriques de qualité d'e‑mail montrent d'où viennent les inscriptions problématiques et ce qu'elles coûtent. Suivez les invalides, les e‑mails jetables et les échecs domaine/MX et reliez‑les à l'activation.
Ce que vous essayez vraiment de mesurer (en termes simples)
« Qualité d'e‑mail » est simple : pouvez‑vous joindre cette personne, et l'adresse a‑t‑elle l'air d'appartenir à un utilisateur réel et intéressé.
Dans un formulaire d'inscription ou de lead, une adresse de haute qualité est celle qui peut recevoir du courrier, qui n'est pas jetable ou temporaire, et qui semble à faible risque (pas un piège connu ni un schéma qui conduit souvent à des plaintes). Vous ne jugez pas la personne. Vous jugez si l'adresse fonctionnera comme un canal fiable.
Quand la qualité baisse, ça se voit vite :
- Plus de rebonds, ce qui peut nuire à la réputation d'envoi et à la délivrabilité
- Moins d'activations parce que les utilisateurs ne voient jamais les e‑mails de vérification ou de bienvenue
- Un CRM rempli de leads morts qui gaspillent le temps des relances
- Des analytics bruyants (on dirait que « les inscriptions augmentent », mais les vrais utilisateurs n'augmentent pas)
Surveiller ce n'est pas faire de jolis graphiques. C'est avoir une alerte précoce et un diagnostic rapide. Les métriques utiles vous disent deux choses : ce qui a changé et d'où ça vient (une campagne, une source de trafic, un pays, un formulaire spécifique ou un nouveau partenaire).
Exemple : vous lancez une promo et les inscriptions bondissent de 30 %. Une semaine plus tard, moins d'utilisateurs s'activent. Si vous suivez la qualité des e‑mails, vous pourriez voir que les adresses jetables ont doublé pendant cette période, ou que les échecs domaine/MX ont grimpé. Cela pointe vers du trafic bot, un champ de formulaire cassé ou une source attirant des inscriptions à faible intention.
Fixez les attentes tôt : chaque métrique doit correspondre à une action. Si un chiffre augmente, vous devez déjà savoir si cela signifie resserrer la validation, ajuster une campagne, ajouter de la friction pour le trafic suspect ou enquêter sur une panne ponctuelle.
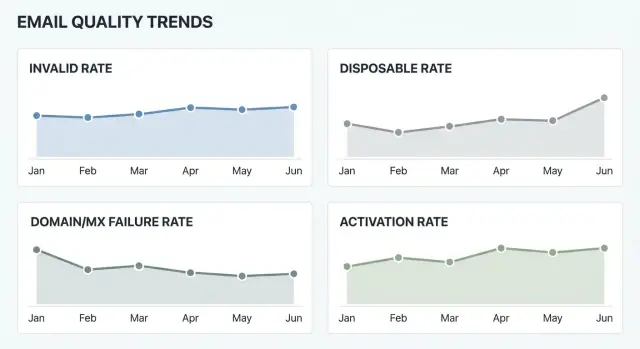
Les métriques de base : invalides, jetables et échecs domaine/MX
Si vous voulez des métriques utiles dans le temps, gardez les « trois de base » simples et bien définies. Ces chiffres vous disent si vous collectez des adresses joignables et si le problème vient du comportement utilisateur ou de l'infrastructure.
Taux d'invalides est la part des inscriptions dont l'adresse n'est pas utilisable. Au minimum, comptez les échecs évidents comme la syntaxe incorrecte (absence de @, caractères interdits) et les domaines qui n'existent pas. Si vous mesurez aussi la joignabilité de la boîte, soyez prudent dans l'interprétation : « boîte non joignable » peut signifier une vraie boîte invalide, mais aussi un blocage temporaire, du greylisting ou une limite côté fournisseur.
Taux d'e‑mails jetables est la part des inscriptions provenant de fournisseurs d'e‑mails jetables connus (services de boîte à usage unique). Ces adresses corrèlent souvent avec des comptes faux, une activation moindre, un risque de fraude plus élevé et une délivrabilité plus faible ensuite. Une adresse jetable peut rester techniquement « valide », d'où l'importance de garder cette métrique séparée.
Taux d'échecs domaine et MX capture les problèmes qui surviennent avant d'atteindre une boîte : le domaine est absent, le DNS ne se résout pas, ou le domaine n'a pas d'enregistrements MX (donc ne peut recevoir d'e‑mails). Si possible, suivez séparément les échecs DNS temporaires, car ils augmentent souvent lors de pannes.
Une configuration pratique utilise quelques catégories de résultat stables. Beaucoup d'équipes commencent avec :
- Valide
- Invalide
- Jetable
- Inconnu
La catégorie inconnu est votre système d'alerte précoce. Elle capte les timeouts, les blocages par des fournisseurs et les résultats ambigus qui ne doivent pas être forcés dans « valide » ou « invalide ». Quel que soit l'outil, la cohérence compte plus qu'une catégorisation parfaite : gardez des définitions stables et ne les changez qu'en laissant une note datée pour que les tendances restent comparables.
Comment calculer les taux pour qu'ils ne mentent pas
De bonnes métriques commencent par une décision ennuyeuse : choisir un dénominateur cohérent. Pour la surveillance des inscriptions, utilisez le total des inscriptions comme base afin que chaque taux réponde à « sur tous ceux qui ont essayé de s'inscrire, combien ont eu ce problème ? »
Formules réutilisables (par jour ou par semaine) :
- Taux d'e‑mails invalides = invalid_results / total_signups
- Taux d'e‑mails jetables = disposable_results / total_signups
- Taux d'échecs domaine et MX = domain_or_mx_fail_results / total_signups
- Taux de couverture de validation = validated_signups / total_signups
Suivez les comptes en plus des taux. Les taux seuls peuvent tromper quand le volume est faible. Si vous avez eu 20 inscriptions un dimanche et que 2 étaient invalides, ça fait 10 %, mais ça peut n'être que du bruit. Les comptes indiquent si vous observez un vrai changement.
Pour le reporting, utilisez des vues quotidiennes et hebdomadaires. Le quotidien aide à repérer les changements soudains (comme un lancement de campagne). L'hebdomadaire lisse les variations jour à jour. Une vue glissante sur 7 jours est un bon compromis.
Les vérifications domaine et DNS nécessitent une règle supplémentaire : les retries. Parfois une recherche de domaine échoue à cause d'un résolveur temporaire, pas parce que l'e‑mail est mauvais. Décidez ce que vous voulez mesurer et étiquetez‑le clairement :
- Taux d'échecs au premier essai (détecte rapidement les problèmes d'infrastructure ou de DNS)
- Taux d'échecs final après retries (plus proche de la joignabilité réelle)
Enfin, stockez le code brut du résultat de validation, pas seulement valide/échec. Quand vous conservez la raison (syntax_error, no_mx, disposable_provider, blocked, timeout, etc.), vous pouvez expliquer les changements plus tard et segmenter précisément.
Étape par étape : mettre en place la surveillance de l'inscription au tableau de bord
Commencez par décider où les contrôles ont lieu. Beaucoup d'équipes font un contrôle de format rapide dans le formulaire d'inscription pour attraper les fautes, puis exécutent la décision réelle côté serveur pour qu'elle ne puisse pas être contournée.
Ensuite, consignez le résultat pour chaque tentative, même celles que vous bloquez. Les tentatives bloquées renseignent sur les attaques, les sources marketing cassées et les frictions UX.
Une configuration simple qui fonctionne pour la plupart des produits :
- Valider à l'inscription (et lors des flux de changement d'e‑mail).
- Stocker l'horodatage, l'ID utilisateur/session, la source d'inscription (campagne/référent/app) et le domaine d'e‑mail brut.
- Stocker le résultat de la validation plus un court code de raison (syntax, disposable, MX missing, domain not found, blocklisted, timeout).
- Mapper les résultats dans des catégories stables à conserver long terme : valide, invalide, jetable, échec domaine, inconnu.
- Agréger dans une table quotidienne et tracer chaque taux en tant que série temporelle.
La cohérence fait la différence entre un tableau que vous regardez et un tableau que vous ignorez. Conservez les catégories de base stables même si votre validateur ajoute de nouveaux codes de raison plus tard. Vous pouvez toujours créer une ventilation secondaire, mais vos courbes principales ne doivent pas changer de définition chaque mois.
Pour le tableau de bord, un graphique par taux suffit au début. Ajoutez un petit tableau sous chaque graphique avec les comptes quotidiens pour voir si un pic est réel ou dû à un faible volume.
Créez une habitude hebdomadaire : lorsqu'un pic apparaît, notez ce qui a changé (nouvelle campagne, nouveau pays, changement de copy produit, nouvelle source de trafic, mise à jour de la config de validation). Si le taux d'e‑mails jetables augmente juste après le lancement d'un giveaway, cela peut être attendu ; la vraie décision est de bloquer, avertir ou autoriser mais marquer ces inscriptions.
Segmentation : trouver d'où viennent réellement les mauvais e‑mails
Si vous ne suivez qu'un seul chiffre global, vous manquerez la cause. Les mauvaises adresses ne sont presque jamais réparties de façon homogène. La segmentation transforme les métriques de qualité en actions possibles.
Commencez par « d'où vient cette inscription ? » et fractionnez les taux par un petit ensemble de sources fiables. Un premier niveau simple :
- Canal d'acquisition (pubs, SEO, partenaires, recommandations, imports commerciaux)
- Surface d'inscription (liste d'attente, essai, newsletter, contact commercial)
- Géographie ou langue (seulement quand les volumes sont suffisants)
- Nouveaux vs utilisateurs récurrents (si vous pouvez faire la distinction)
Gardez les groupes suffisamment grands pour avoir du sens. Un pays avec 12 inscriptions peut varier de 0 % à 25 % d'invalides du jour au lendemain et cela ne veut rien dire. Fixez une taille d'échantillon minimale (par exemple 100 inscriptions) avant de considérer un segment comme signal.
Un exemple pratique : vous observez un pic hebdomadaire du taux d'e‑mails jetables. Le chiffre site‑wide a l'air alarmant, mais la segmentation montre que c'est presque entièrement dû à une campagne partenaire envoyant du trafic vers un formulaire de newsletter. Maintenant vous savez quoi faire : revoir les protections de ce formulaire, ajuster la campagne ou exiger une étape supplémentaire pour ce chemin.
Surveillez aussi les bots. Ils frappent souvent une surface en particulier (généralement le formulaire le plus simple) et créent des sauts soudains. Indices : forte hausse depuis un seul référent, très haut taux d'échecs domaine/MX sur un seul formulaire, rafales d'inscriptions à des heures étranges, ou trafic depuis des régions qui ne correspondent pas à votre audience.
Lier la qualité d'e‑mail à l'activation et aux autres résultats en aval
Rendre visibles les résultats inconnus
Capturez les timeouts et blocages avec des codes de raison que vous pouvez suivre dans le temps.
La qualité d'e‑mail ne concerne pas seulement la délivrabilité. Elle impacte ce qui se passe après l'inscription : est‑ce que les gens terminent l'onboarding, confirment leur e‑mail et reviennent. Si une partie des inscriptions utilise des adresses invalides ou jetables, vos métriques produit peuvent empirer même si le produit n'a pas changé.
Une manière pratique de le vérifier est de suivre le taux d'activation par cohorte d'inscription (chaque jour ou semaine) et de comparer des cohortes avec différents niveaux de qualité d'e‑mail. Quand une cohorte a un taux d'invalides ou d'e‑mails jetables plus élevé, vérifiez si l'activation baisse dans la même cohorte. C'est alors que la qualité d'e‑mail devient un signal business, pas seulement un détail mail ops.
Résultats en aval à suivre
Choisissez quelques étapes importantes pour votre produit, puis ventilez‑les par segment de qualité d'e‑mail (valide vs invalide, jetable vs non‑jetable, échec domaine/MX) :
- Taux d'achèvement de la vérification d'e‑mail
- Taux de première connexion dans les 24–72 heures
- Première action clé (votre moment « aha »)
- Taux essai→payant (ou lead→rendez‑vous)
- Taux de contact support par 1 000 inscriptions
Une façon simple d'estimer le coût
Même un calcul approximatif aide : tickets support en plus, relances commerciales en plus, surcharge liée aux renvois/vérifications, plus le coût moins tangible du risque de réputation lié aux rebonds. Si 2 % d'inscriptions supplémentaires sont invalides et que chaque mauvaise inscription coûte 3 minutes au support, vous pouvez convertir un pourcentage en heures et en euros rapidement.
Une mise en garde : corrélation n'est pas toujours causalité. La saisonnalité, une nouvelle source de trafic ou un changement d'UI peuvent faire bouger l'activation et la qualité d'e‑mail en même temps. Néanmoins, des schémas répétés à travers des cohortes suffisent généralement à orienter les investigations.
Alertes et seuils qui déclenchent la bonne réponse
Les alertes doivent prendre les vrais problèmes, pas le bruit normal. Commencez par apprendre votre ligne de base sur les 2 à 4 dernières semaines : à quoi ressemble la normale pour le taux d'invalides, le taux d'e‑mails jetables et le taux d'échecs domaine/MX. Ensuite définissez des seuils adaptés à votre trafic.
Une règle pratique est le « 2× la normale », mais seulement quand le volume est suffisamment élevé. Si les e‑mails jetables tournent habituellement à 1 %, une alerte à 2 % peut être utile, mais seulement après au moins 200 inscriptions dans la fenêtre.
Utilisez à la fois des déclencheurs relatifs et absolus pour que les métriques ne trompent pas :
- Pic relatif : le taux est 2× (ou 1,5×) votre ligne de base
- Seuil absolu : le taux dépasse un nombre fixe (par exemple >3 %)
- Volume minimum : au moins N inscriptions (choisissez N selon votre trafic)
- Durée minimum : soutenu pendant 30 à 60 minutes (ou 1 jour complet pour faible volume)
Gardez des alertes séparées pour différents types d'échecs car le détenteur et la correction diffèrent souvent. Un pic d'e‑mails jetables pointe souvent vers de l'abus, une campagne incitative ou une vague de bots. Un pic d'échecs domaine/MX pointe souvent vers un bug de formulaire, un mauvais autofill ou un problème DNS temporaire.
Quand une alerte se déclenche, rédigez une courte note d'incident :
- Ce qui a changé (release, campagne, source de trafic, pays)
- Quelle métrique a bougé, et de combien
- Quel segment a conduit le changement (canal, formulaire, cohorte)
- Ce que vous avez fait (bloqué, ajusté l'UI, resserré la validation)
- Résultat après le changement
Décidez de la responsabilité en amont. Marketing ops gère généralement les pics liés aux campagnes, le produit gère les problèmes de formulaire et UX, et l'ingénierie gère la logique de validation et les intégrations.
Lire les schémas : ce que signifie chaque pic
Commencer petit, monter en charge
Utilisez 100 validations par mois sans carte bancaire, puis montez en charge quand vous êtes prêt.
Semaine après semaine, ce sont les pics qui vous apprennent le plus. Ils pointent généralement vers une cause spécifique.
Pic du taux d'invalides vient souvent d'abus de formulaire (bots), de fautes de frappe simples ou d'un changement d'UI comme un masque d'entrée cassé.
Action rapide : vérifiez les récents changements du formulaire et effectuez quelques inscriptions réelles sur mobile et desktop.
Suivi plus profond : comparez les invalides par source (landing page, appareil, pays, campagne) et examinez les logs serveur pour des rafales de type bot.
Pic du taux d'e‑mails jetables est fréquent après l'ajout d'une incitation (coupon, essai gratuit) ou l'achat de trafic. Il peut aussi signaler des visiteurs à faible intention qui testent votre produit.
Action rapide : resserrez les règles autour de l'offre (codes à usage unique, limites de taux, contrôles anti‑bot plus forts).
Suivi plus profond : ventilez les inscriptions jetables par canal et créatif, puis décidez de bloquer, avertir ou exiger une étape supplémentaire pour les segments risqués.
Pic du taux d'échecs domaine/MX indique souvent des problèmes de résolution DNS, une panne temporaire d'un fournisseur majeur ou un changement réseau de votre côté.
Action rapide : retestez un échantillon de domaines en échec quelques minutes plus tard et depuis un second réseau.
Suivi plus profond : vérifiez la santé des résolveurs DNS et les timeouts.
Croissance de la catégorie « inconnu » signifie généralement que votre intégration timeoute, perd des champs ou ne classe pas un nouveau modèle.
Action rapide : vérifiez que les réponses API sont bien journalisées et stockées bout en bout.
Suivi plus profond : auditez les timeouts, les retries et la façon dont vous mappez les codes de raison vers les catégories.
Une bonne règle : si un pic correspond à un changement produit, suspectez d'abord votre formulaire. S'il correspond à un changement de trafic, suspectez l'intention et l'abus.
Erreurs communes qui rendent les métriques inutiles
La plupart des tableaux échouent pour des raisons ennuyeuses : les chiffres semblent précis, mais les données sont sales. Chaque graphique doit répondre à une question claire et rester comparable d'une semaine à l'autre.
Une façon rapide de casser vos taux est de compter les tentatives au lieu des personnes. Les inscriptions comprennent souvent des retries (fautes de frappe, bouton retour, resoumissions, timeouts mobiles). Si vous comptez chaque tentative, votre taux d'invalides peut augmenter même si les mêmes utilisateurs corrigent ensuite leur adresse. Décidez d'une unité (utilisateur unique, e‑mail unique, ou session d'inscription unique) et dédupliquez avant de calculer les taux.
Un autre piège est de changer les définitions en cours de route. Si « jetable » s'étend pour inclure plus de fournisseurs, ou si « invalide » passe de syntaxe seulement à syntaxe plus vérification de domaine, votre courbe montrera un faux pic. Gel des définitions, versionnez‑les et tenez un simple journal de modifications.
Erreurs courantes qui polluent les résultats :
- Mélanger tentatives et inscriptions uniques sans déduplication claire
- Changer discrètement ce qui compte comme invalide ou jetable puis comparer des mois
- Regarder seulement les totaux et manquer le canal qui génère la plupart des mauvais e‑mails
- Bloquer trop agressivement pour améliorer le « taux valide », puis réduire les conversions réelles
- Traiter les timeouts DNS temporaires comme des échecs permanents au lieu de relancer ou de les séparer
Exemple : une campagne apporte des inscriptions d'une région. Les recherches DNS y sont plus lentes pendant quelques heures, donc les vérifications de domaine expirent. Si vous étiquetez cela comme des échecs durs, votre taux d'échecs de domaine monte et vous risquez de bloquer de bons utilisateurs. Si vous suivez les timeouts séparément et retentez, le pic devient un problème de performance, pas une crise de qualité d'e‑mail.
Exemple : diagnostiquer une baisse de qualité des inscriptions en une semaine
Une équipe SaaS remarque quelque chose d'étrange lundi : les essais augmentent de 30 % après une nouvelle campagne promo, mais le taux d'e‑mails jetables passe de 4 % à 18 %. Deux jours plus tard, les tickets support augmentent car des gens « n'ont jamais reçu l'e‑mail de bienvenue », et les ventes se plaignent que les leads semblent de faible intention.
D'abord, confirmez que c'est réel et pas un bug de suivi. Comparez la semaine dernière à la moyenne des quatre semaines précédentes, en utilisant la même définition et le même dénominateur. Si les métriques sont calculées par tentative d'inscription, des changements dans le comportement de retry peuvent masquer (ou exagérer) le problème. Décidez si vous surveillez par tentative, par inscription acceptée ou par utilisateur unique, et tenez‑vous y.
Puis segmentez pour trouver le moteur. Ventiler les inscriptions par source montre que le pic vient presque entièrement de PromoA (un coupon posté sur un forum de deals). Les organiques et les referrals partenaires restent inchangés. Le taux d'échecs domaine/MX reste stable, suggérant qu'il ne s'agit pas d'une panne DNS ou d'un bug de formulaire. C'est surtout des fournisseurs jetables.
Une vérification simple des causes racines :
- Comparez le taux jetable par campagne, pas seulement globalement
- Vérifiez le taux d'activation pour la nouvelle cohorte vs la cohorte de la semaine précédente
- Passez en revue un petit échantillon d'adresses (sans en stocker plus que nécessaire)
- Confirmez que le système classe les mêmes domaines de façon cohérente
- Alignez l'objectif : plus d'essais, plus d'activations, ou les deux
Ensuite vient la décision. Ils choisissent une réponse progressive : bloquer les domaines jetables les plus courants et ajouter une vérification d'e‑mail uniquement pour le trafic PromoA. L'incitation reste, mais l'abus est limité.
En une semaine, le taux jetable pour PromoA tombe à 6 %, l'activation passe de 9 % à 14 % et la charge support revient à la normale. Ils documentent une courte note avant/après (métriques, dates et changement exact) pour que la prochaine alerte mène à une réponse confiante.
Checklist rapide pour un tableau de bord qualité sain
Protéger les inscriptions de campagne
Gérez le trafic promotionnel en filtrant les fournisseurs jetables et en segmentant par source.
Un bon tableau est ennuyeux la plupart du temps. Quand quelque chose change, vous pouvez rapidement dire ce qui a bougé et d'où c'est parti.
Fixez une ligne de base sur les 4 à 8 dernières semaines. C'est assez long pour lisser le bruit, mais assez court pour refléter le trafic actuel et votre flux d'inscription.
Vérifiez la configuration :
- Vous suivez invalides, jetables, échecs domaine/MX et inconnu comme résultats séparés (pas un taux d'échec agrégé).
- Chaque graphique peut être ventilé par source d'acquisition et par point d'entrée exact (web, mobile, checkout, liste d'attente).
- Vous passez en revue l'activation (ou la première action clé) par cohorte d'inscription à côté des taux de qualité d'e‑mail.
- Les alertes exigent à la fois un changement de taux et un volume minimum.
- Vous pouvez passer d'un pic à un petit échantillon pour ce segment afin d'identifier des motifs rapidement.
Attribuez un propriétaire et un playbook. Quand le taux jetable augmente, qui vérifie les campagnes ? Quand les échecs de domaine augmentent, qui vérifie panne vs bug de formulaire ?
Prochaines étapes : améliorer la qualité sans nuire aux inscriptions
Commencez par un changement que vous pouvez tenir. Si vous ajoutez en même temps logs, segmentation et alertes, vous ne saurez pas ce qui a aidé.
Choisissez votre première amélioration selon la douleur ressentie :
- Si vous vous disputez sur les chiffres, améliorez d'abord le logging.
- Si vous ne savez pas d'où viennent les problèmes, ajoutez d'abord la segmentation.
- Si vous découvrez les problèmes trop tard, ajoutez d'abord les alertes.
Ensuite, décidez d'une politique pour les e‑mails « mauvais » et « peut‑être mauvais ». Les invalides et les échecs domaine/MX durs sont généralement sûrs à bloquer car ils deviennent rarement de vrais utilisateurs. Les jetables et les échecs temporaires sont plus délicats car certaines personnes légitimes les utilisent.
Une politique simple qui marche pour beaucoup de produits : bloquez les invalides évidents, avertissez pour les jetables, et relancez les échecs temporaires (ou demandez une confirmation à l'utilisateur). Quelle que soit votre approche, écrivez‑la pour que le support et le produit répondent de manière cohérente.
Puis lancez une petite expérience. Changez une règle pour un segment pendant une courte période et observez qualité et résultats. Exemple : affichez un avertissement (pas un blocage) pour les e‑mails jetables sur les inscriptions mobiles pendant une semaine, puis comparez l'activation par cohorte avec la semaine précédente. Si l'activation reste stable mais que le taux jetable baisse, conservez la mesure. Si l'activation chute, revenez en arrière.
Si vous voulez une classification cohérente à l'inscription, une API de validation d'e‑mail peut vous aider à étiqueter invalide, jetable et les résultats domaine/MX de la même façon sur tous les formulaires et services. Par exemple, Verimail (verimail.co) fournit une API de validation à appel unique avec des vérifications comme la syntaxe, la vérification domaine et MX, et la détection des fournisseurs jetables.
Mettez en place une revue mensuelle qui se termine par une décision. Une page suffit : métriques principales, plus grand changement, ce que vous avez essayé, ce que vous changerez le mois prochain et ce que vous ne changerez pas.
FAQ
Que signifie réellement la « qualité d'e‑mail » pour les inscriptions ?
La qualité d'un e‑mail signifie que l'adresse est vraisemblablement joignable et présente peu de risques pour votre produit. Un « bon » e‑mail peut recevoir du courrier, ne provient pas d'un fournisseur jetable et ne correspond pas à des modèles qui entraînent souvent des rebonds ou des plaintes.
Quelles 3 métriques de qualité d'e‑mail dois‑je suivre en premier ?
Commencez par trois métriques : le taux d'invalides, le taux d'e‑mails jetables et le taux d'échecs domaine/MX. Ensemble, elles indiquent si les utilisateurs font des fautes de frappe, si vous attirez des inscriptions à faible intention et si des problèmes d'infrastructure ou DNS bloquent la délivrabilité.
Que dois‑je utiliser comme dénominateur pour calculer les taux ?
Utilisez le nombre total de tentatives d'inscription comme dénominateur par défaut afin que chaque taux réponde à la question « sur tous ceux qui ont essayé de s'inscrire, combien ont eu ce problème ? » Ensuite, gardez ce dénominateur cohérent d'une semaine à l'autre pour que les tendances restent comparables.
Pourquoi ai‑je besoin d'une catégorie « inconnu » ?
La catégorie « inconnu » accueille les timeouts, les blocages par des fournisseurs et les contrôles ambigus. Elle est utile parce qu'elle met en évidence des problèmes d'intégration et des conditions temporaires que vous ne devriez pas étiqueter silencieusement comme valides ou invalides.
Dois‑je relancer les vérifications domaine/MX ou compter les échecs immédiatement ?
Les recherches DNS et réseau peuvent échouer temporairement alors qu'un e‑mail est pourtant valide. Une approche courante consiste à suivre le taux d'échecs au premier essai (pour détecter rapidement les pannes) et le taux final après tentatives de retry (pour estimer la joignabilité réelle).
Comment déterminer d'où proviennent les mauvais e‑mails ?
Si vous ne regardez qu'un seul chiffre global, vous passerez à côté de la cause. Segmentez d'abord par source d'acquisition et par point d'inscription, puis ajoutez la géographie ou l'appareil seulement quand la taille d'échantillon est suffisante pour être fiable.
Comment relier la qualité d'e‑mail à l'activation et aux autres résultats ?
Suivez le taux d'activation ou l'achèvement de la vérification par cohorte d'inscription, et comparez les cohortes selon la qualité d'e‑mail. Si les cohortes avec plus d'e‑mails jetables ou invalides s'activent moins souvent, vous avez identifié un levier qui affecte les métriques produit, pas seulement la délivrabilité.
Quels seuils utiliser pour les alertes sans être submergé ?
Basez les alertes sur une ligne de base des dernières semaines, et exigez un volume suffisant pour éviter le bruit. Une alerte pratique se déclenche quand un taux dépasse significativement la normale et reste élevé assez longtemps pour écarter un pic bref.
Quelles sont les erreurs les plus courantes qui rendent ces métriques trompeuses ?
Le principal écueil est de compter les tentatives au lieu des inscriptions uniques ou des sessions, ce qui gonfle le taux d'invalides quand les utilisateurs réessaient. Un autre est de changer les définitions dans le temps, ce qui crée des pics artificiels : conservez des catégories stables et consignez toute modification avec des dates.
Dois‑je bloquer les e‑mails jetables ou simplement avertir les utilisateurs ?
Bloquez par défaut les évidents invalides et les échecs durables domaine/MX, car ils se convertissent rarement. Traitez les e‑mails jetables et les échecs temporaires plus prudemment : avertissement, vérification supplémentaire ou friction ciblée sur les segments à risque afin de ne pas nuire aux conversions légitimes.