21 окт. 2025 г.·7 мин
Метрики качества email для долгосрочного мониторинга (и зачем они нужны)
Метрики качества email показывают, откуда приходят плохие регистрации и во сколько это обходится. Отслеживайте недействительные, disposable и ошибки домена/MX и связывайте их с активацией.
Что вы на самом деле пытаетесь измерить (простыми словами)
«Качество email» — это просто: можно ли связаться с этим человеком, и выглядит ли адрес как настоящий, заинтересованный пользователь.
В форме регистрации или лид-форме качественный адрес — это тот, который может принимать почту, не является disposable или временным, и выглядит низкорисковым (не относится к знакомым ловушкам и не совпадает с шаблонами, которые часто приводят к жалобам). Вы оцениваете не человека, а пригодность адреса как надёжного канала.
Когда качество падает, это быстро проявляется:
- Больше bounce’ов, что вредит репутации отправителя и доставляемости
- Ниже активация, потому что пользователи не видят письма для подтверждения или приветствия
- CRM, заполненная «мёртвыми» лидами, тратящими время на дальнейшую работу
- Шумная аналитика (вроде «регистраций больше», но реальных пользователей нет)
Мониторинг — это не про красивые графики. Это про раннее предупреждение и быструю диагностику. Полезные метрики говорят вам два вещи: что изменилось и откуда пришло (кампания, источник трафика, страна, конкретная форма или новый партнёр).
Пример: вы запустили промо и регистрации выросли на 30%. Неделю спустя меньше пользователей активируются. Если вы отслеживаете качество почты, вы можете увидеть, что доля disposable удвоилась за это время или резко выросли ошибки домена и MX. Это указывает на ботовый трафик, сломанное поле формы или источник с низкой мотивацией пользователей.
Задайте ожидания заранее: каждая метрика должна соответствовать действию. Если число растёт, вы должны заранее знать, означает ли это ужесточение валидации, корректировку кампании, добавление трения для подозрительного трафика или расследование единичного сбоя.
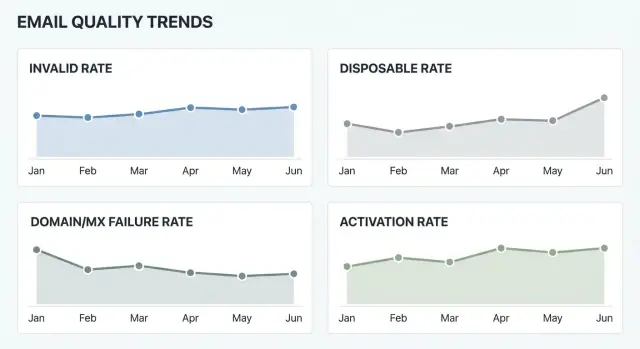
Основные метрики: недействительные, disposable и ошибки домена/MX
Если вы хотите, чтобы метрики оставались полезными со временем, держите «основную тройку» простой и чётко определённой. Эти числа показывают, собираете ли вы достижимые адреса и связано ли это с поведением пользователей или инфраструктурой.
Доля недействительных — это доля регистраций, где адрес непригоден. Как минимум, учитывайте явные ошибки: неправильный синтаксис (нет @, недопустимые символы) и несуществующие домены. Если вы также проверяете доступность почтового ящика, аккуратно интерпретируйте результаты: «ящик недостижим» может означать действительно недействительный ящик, но также временная блокировка, greylisting или ограничения со стороны провайдера.
Доля disposable — это часть регистраций от известных одноразовых сервисов почты. Такие адреса часто коррелируют с фейковыми аккаунтами, меньшей активацией, повышенным риском мошенничества и ухудшением доставляемости в дальнейшем. Disposable-адрес может быть технически «валидным», поэтому эту метрику стоит держать отдельно.
Доля ошибок домена и MX фиксирует проблемы, которые происходят ещё до попытки достучаться до почтового ящика: домена нет, не удаётся разрешить DNS или у домена нет MX-записей (то есть он не может принимать почту). По возможности отслеживайте временные DNS-сбои отдельно, они часто растут во время аутейджей.
Практичная настройка использует несколько стабильных корзин результатов. Многие команды начинают с:
- Валидный
- Недействительный
- Disposable
- Неизвестно
Корзина «неизвестно» — ваш ранний сигнал тревоги. Она ловит тайм‑аута, блоки провайдеров и неоднозначные результаты, которые не стоит насильно помещать в «валидный» или «недействительный». Какой бы инструмент вы ни использовали, стабильность важнее идеальной категоризации: держите определения постоянными и меняйте их только с пометкой и датой, чтобы тренды оставались сопоставимыми.
Как считать доли, чтобы они не вели в заблуждение
Хорошие метрики начинаются с одного скучного решения: выберите постоянный знаменатель. Для мониторинга регистраций используйте общее число попыток регистрации как базу, чтобы каждая доля отвечала: «Из всех, кто пытался присоединиться, у скольких была эта проблема?»
Формулы, которые можно переиспользовать (за сутки или неделю):
- Доля недействительных = invalid_results / total_signups
- Доля disposable = disposable_results / total_signups
- Доля ошибок домена и MX = domain_or_mx_fail_results / total_signups
- Доля покрытия валидацией = validated_signups / total_signups
Отслеживайте количества рядом с долями. Одна лишь доля может ввести в заблуждение при малых объёмах. Если в воскресенье было 20 регистраций и 2 из них недействительны, это 10%, но может быть случайностью. Количества показывают, реальный ли это сдвиг.
Для отчётности используйте и дневные, и недельные представления. День выявляет резкие изменения (например, запуск кампании). Неделя сглаживает колебания. 7‑дневное скользящее среднее — хорошая середина.
Проверки доменов и DNS требуют ещё одного правила: ретраи. Иногда lookup домена падает из‑за временной проблемы резолвера, а не потому что email плох. Решите, что вы хотите измерять, и пометьте это явно:
- Доля неудач при первой попытке (ловит инфраструктурные или DNS‑проблемы быстро)
- Конечная доля после повторных попыток (ближе к реальной достижимости адреса)
Наконец, храните сырой код результата валидации, а не только pass/fail. Когда у вас есть причина (syntax_error, no_mx, disposable_provider, blocked, timeout и т. п.), вы сможете позже объяснить изменения и точно сегментировать.
Пошагово: настройка мониторинга от регистрации до дашборда
Начните с решения, где происходят проверки. Многие команды делают быстрый форматный чек в форме регистрации, чтобы ловить опечатки, а реальное решение — на сервере, чтобы его нельзя было обойти.
Далее логируйте результат каждой попытки, даже заблокированные. Заблокированные попытки всё равно говорят о атаках, сломанных маркетинговых источниках и проблемах UX.
Простая настройка, подходящая большинству продуктов:
- Валидируйте при регистрации (и при смене email).
- Сохраняйте временную метку, ID пользователя/сессии, источник регистрации (кампания/реферер/приложение) и сырой домен email.
- Сохраняйте исход результата валидации и короткий код причины (syntax, disposable, MX missing, domain not found, blocklisted, timeout).
- Мапьте исходы в стабильные корзины для долгого хранения: valid, invalid, disposable, domain-fail, unknown.
- Агрегируйте в дневную таблицу и рисуйте по каждой доле линию тренда.
Стабильность — это разница между дашбордом, которому вы доверяете, и тем, которым пренебрегают. Держите основные корзины неизменными, даже если валидатор добавит новые коды причин позже. Можно сделать вторичный разбор, но ключевые тренд‑линии не должны меняться каждый месяц.
Для дашборда сначала хватит по одному графику на метрику. Под каждым графиком добавьте маленькую таблицу с ежедневными числами, чтобы видеть, реальный ли всплеск или это малые объёмы.
Вырабатывайте еженедельную привычку: при появлении всплеска запишите, что изменилось (новая кампания, страна, изменение текста, источник трафика, обновление валидации). Если disposable растёт сразу после розыгрыша, это может быть ожидаемо; реальное решение — блокировать, предупреждать или помечать такие регистрации.
Сегментация: где на самом деле берутся плохие адреса
Если вы отслеживаете только одно число по сайту, вы упустите причину. Плохие адреса редко распределены равномерно. Сегментация превращает метрики в действие.
Начните с «откуда пришла регистрация?» и разбейте доли по небольшому набору надёжных источников. Простая первичная сегментация:
- Канал привлечения (реклама, SEO, партнёры, рефералы, импорт продаж)
- Поверхность регистрации (waitlist, trial, newsletter, контакт с sales)
- География или язык (только при достаточных объёмах)
- Новые vs возвращающиеся пользователи (если можно отличить)
Держите группы достаточно крупными, чтобы они значили что‑то. Страна с 12 регистрациями может скакнуть от 0% до 25% недействительных и это ничего не значит. Установите минимальный размер выборки (например, 100 регистраций), прежде чем считать сегмент сигналом.
Практический пример: вы видите недельный всплеск disposable. Общая диаграмма пугает, но сегментация показывает, что это почти весь трафик от одного партнёрского промо. Теперь понятно, что делать: проверить защиту конкретной формы, скорректировать кампанию или требовать дополнительного шага для этой ветки.
Также следите за ботами. Они обычно штурмуют самую простую форму и создают резкие всплески. Признаки: резкий рост с одного реферера, очень высокая доля ошибок домена/MX в одной форме, волны регистраций в нерабочие часы или трафик из географий, не соответствующих вашей аудитории.
Связь качества email с активацией и другими результатами
Быстро ловите ошибки доменов
Раннее обнаружение проблем с DNS и MX с согласованными результатами валидации.
Качество email — это не только доставляемость. Оно влияет на то, что происходит после регистрации: завершают ли пользователи онбординг, подтверждают ли почту и возвращаются ли. Если часть регистраций использует недействительные или disposable адреса, продуктовые метрики могут выглядеть хуже, даже если сам продукт не изменился.
Практический способ увидеть это — отслеживать уровень активации по когортам регистраций (каждый день или неделю) и сравнивать когорты с разным уровнем качества. Если у когорты выше доля недействительных или disposable, проверьте, падает ли активация в той же когорте. Тогда качество email становится бизнес‑сигналом, а не только вопросом mail ops.
Важные downstream‑показатели для отслеживания
Выберите несколько контрольных точек, значимых для вашего продукта, и разбейте их по сегментам качества email (валидный vs недействительный, disposable vs не‑disposable, ошибки домена/MX):
- Доля завершивших подтверждение email
- Доля первых входов в течение 24–72 часов
- Первое ключевое действие (ваш «aha» момент)
- Конверсия trial->paid (или лид->встреча)
- Частота обращений в поддержку на 1000 регистраций
Простой способ оценить стоимость
Даже грубые подсчёты помогают: дополнительные тикеты в поддержку, лишние продажи‑фоллоу‑апы, перекладные расходы на повторные отправки/верификацию и более мягкая, но реальная стоимость рисков для репутации из‑за bounce’ов. Если на 2% больше регистраций недействительны и каждая такая регистрация отнимает 3 минуты у поддержки, вы быстро переведёте процент в часы и деньги.
Осторожность: корреляция не всегда означает причинно‑следственную связь. Сезонность, новый источник трафика или изменение UI могут одновременно повлиять и на активацию, и на качество почты. Тем не менее, повторяющиеся паттерны по когортам обычно дают достаточно поводов для расследования.
Оповещения и пороги, которые приводят к правильным действиям
Оповещения должны ловить реальные проблемы, а не нормальный шум. Начните с изучения базовой линии за последние 2–4 недели: что нормально для доли недействительных, disposable и ошибок домена/MX. Затем ставьте пороги, соответствующие вашему трафику.
Практическое правило — «в 2 раза выше нормы», но только при достаточном объёме. Если обычно disposable = 1%, оповещение на 2% может сработать, но только после как минимум 200 регистраций в окне.
Используйте и относительные, и абсолютные триггеры, чтобы метрики не вводили в заблуждение:
- Относительный всплеск: доля в 2x (или 1.5x) выше базовой
- Абсолютный порог: доля выше фиксированного значения (например, >3%)
- Минимальный объём: не менее N регистраций (подберите N под ваш трафик)
- Минимальная длительность: устойчиво в течение 30–60 минут (или 1 дня для низкого трафика)
Держите отдельные оповещения для разных типов ошибок: владелец и способ устранения обычно разные. Всплеск disposable обычно указывает на злоупотребления, кампанию с вознаграждением или волну ботов. Всплеск ошибок домена/MX чаще указывает на баг формы, плохую автозаполнение или временную проблему DNS.
Когда оповещение срабатывает, запишите короткий инцидентный отчёт:
- Что изменилось (релиз, кампания, источник трафика, страна)
- Какая метрика сместилась и на сколько
- Какой сегмент это вызвал (канал, форма, когорта)
- Что вы сделали (заблокировали, поменяли UI, ужесточили валидацию)
- Результат после изменения
Решите заранее владельца. Marketing ops обычно отвечает за всплески, связанные с кампаниями, продукт — за баги формы и UX, а инженеринг — за логику валидации и интеграции.
Чтение паттернов: что обычно означает каждый всплеск
Защищайте регистрации кампаний
Обрабатывайте трафик промо: фильтруйте disposable-провайдеров и сегментируйте по источнику.
Неделя за неделей именно всплески дают больше всего информации. Обычно они указывают на конкретную причину.
Всплеск доли недействительных часто связан с абузом форм (боты), простыми опечатками или изменением UI, например сломанной маской ввода.
Быстрое действие: проверьте последние изменения формы и сделайте реальные регистрации на мобильных и десктопе.
Глубже: сравните недействительные по источникам (лендинг, устройство, страна, кампания) и посмотрите логи сервера на ботовые паттерны.
Всплеск disposable часто появляется после добавления стимула (купон, бесплатный период) или покупки трафика. Он также может означать посетителей с низкой мотивацией, тестирующих продукт.
Быстрое действие: ужесточите правила вокруг оффера (одноразовые коды, лимиты, более строгая проверка на ботов).
Глубже: разбейте disposable по каналам и креативу, затем решите — блокировать, предупреждать или требовать доп. шаг для рискованных сегментов.
Всплеск ошибок домена/MX чаще указывает на проблемы с разрешением DNS, временный аутейдж крупного провайдера или сетевые изменения на вашей стороне.
Быстрое действие: перетестируйте выборку неудачных доменов через несколько минут и из другой сети.
Глубже: проверьте состояние резолвера DNS и таймауты.
Рост корзины «неизвестно» обычно означает, что интеграция тайм‑аутит, теряет поля или не классифицирует новый паттерн.
Быстрое действие: убедитесь, что ответы API логируются и корректно сохраняются end‑to‑end.
Глубже: аудит таймаутов, ретраев и того, как коды причин мапятся в корзины.
Хорошее правило: если всплеск совпадает с продуктовым изменением, подозревайте форму в первую очередь. Если совпадает с изменением трафика — подозревайте намерение пользователей и злоупотребления.
Частые ошибки, делающие метрики бесполезными
Большинство дашбордов ломаются по скучным причинам: числа выглядят точными, но данные грязные. Каждый график должен отвечать на один чёткий вопрос и оставаться сопоставимым неделя к неделе.
Один быстрый способ испортить доли — считать попытки вместо людей. Регистрации часто включают повторы (опечатки, кнопка назад, повторная отправка, мобильные таймауты). Если считать каждую попытку, доля недействительных может вырасти, даже когда те же люди в итоге поправляют адрес. Решите единицу учёта (уникальный пользователь, уникальный email или уникальная сессия регистрации) и дедупайте перед расчётом долей.
Ещё одна ловушка — менять определения незаметно. Если «disposable» расширился за счёт большего числа провайдеров или «недействительный» переключился с только синтаксиса на синтаксис + проверку домена, тренд покажет фальшивый всплеск. Фиксируйте определения, версионируйте и ведите простой change log.
Распространённые ошибки, портящие результаты:
- Смешение попыток и уникальных регистраций без явной дедупликации
- Молчаливое изменение того, что считается недействительным или disposable, с последующим сравнением месяцев
- Отслеживание только общих итогов и пропуск канала, дающего большинство плохих адресов
- Слишком агрессивная блокировка для подъёма «валидной» доли, что снижает реальные конверсии
- Обращение с временными DNS‑таймаутами как с постоянными ошибками вместо ретраев или выделения их отдельно
Пример: кампания привлекает регистрации из одного региона. В этом регионе DNS‑lookup’ы медленнее несколько часов, поэтому проверки домена таймаутят. Если вы пометите это как жёсткие ошибки, доля доменных ошибок вырастет и вы можете заблокировать хороших пользователей. Если вы отслеживаете тайм‑ауты отдельно и выполняете ретраи, всплеск становится проблемой производительности, а не кризисом качества email.
Пример: диагностика падения качества регистраций за неделю
Команда SaaS замечает в понедельник странность: trial’ы выросли на 30% после новой промо‑кампании, но доля disposable поднялась с 4% до 18%. Через два дня растёт нагрузка в поддержке — люди «не получили приветственное письмо», а продажи жалуются на низкоинициированые лиды.
Сначала подтвердите, что это реальный эффект, а не глюк трекинга. Сравните прошлую неделю с четырёхнедельным средним, используя те же определения и тот же знаменатель. Если метрики считаются по попыткам, изменения в поведении с ретраями могут скрывать или усиливать проблему. Решите, мониторите ли вы по попытке, по принятым регистрациям или по уникальным пользователям, и придерживайтесь этого.
Затем сегментируйте, чтобы найти драйвер. Разбивка по источникам показывает: всплеск почти полностью от PromoA (купон на deal‑форуме). Органика и партнёры без изменений. Доля ошибок домена/MX остаётся стабильной — значит это не DNS‑аутейдж и не баг формы. Это в основном disposable.
Простой чек корня:
- Сравните долю disposable по кампаниям, а не только в целом
- Проверьте уровень активации для новой когорты vs прошлой недели
- Просмотрите небольшую выборку адресов (не храня больше, чем нужно)
- Убедитесь, что система классифицирует те же домены последовательно
- Согласуйте цель: больше trial’ов, больше активаций или и то, и другое
Дальше — решение. Они выбирают поэтапный подход: блокировать самые частые disposable‑домены и добавить верификацию email только для трафика PromoA. Стимул остаётся, но злоупотребления ужесточаются.
Через неделю доля disposable для PromoA падает до 6%, активация растёт с 9% до 14%, нагрузка в поддержке возвращается к норме. Они документируют короткую заметку до/после (метрики, даты и точное изменение), чтобы при следующем оповещении было понятно, что делать.
Быстрый чек‑лист для здорового дашборда качества email
Снизьте процент bounce заранее
Проверяйте синтаксис, домен и MX-записи до первой отправки письма.
Хороший дашборд обычно скучен. Когда что‑то меняется, вы быстро понимаете, что и откуда.
Установите базу за последние 4–8 недель. Это достаточно долго, чтобы сгладить шум, но достаточно коротко, чтобы отражать текущий трафик и поток регистрации.
Проверьте настройки:
- Вы отслеживаете отдельно: недействительные, disposable, ошибки домена/MX и неизвестно (не один смешанный fail‑rate).
- Каждый график можно разделить по источнику привлечения и по конкретной точке входа (веб, мобайл, чек‑аут, waitlist).
- Вы смотрите активацию (или первое ключевое действие) по когортам рядом с метриками качества email.
- Оповещения требуют и изменения доли, и минимального объёма.
- Вы можете перейти от всплеска к небольшой выборке по сегменту, чтобы быстро увидеть паттерны.
Назначьте владельца и рабочую процедуру. Когда растёт disposable, кто проверяет кампании? Когда растут доменные ошибки, кто проверяет аутейдж vs баг формы?
Следующие шаги: улучшать качество, не уменьшая регистрации
Начните с одного изменения, которого вы будете придерживаться. Если одновременно добавить логирование, сегментацию и оповещения, вы не поймёте, что помогло.
Выберите первое улучшение по той боли, которая вам важнее:
- Если спорите о числах — сначала улучшите логирование.
- Если не понимаете, откуда приходят проблемы — сначала добавьте сегментацию.
- Если постоянно находите проблемы слишком поздно — сначала добавьте оповещения.
Далее решите политику для «плохих» и «возможно плохих» адресов. Недействительные и жёсткие доменные ошибки обычно безопасно блокировать — они редко превращаются в реальных пользователей. Disposable и временные ошибки сложнее, потому что ими иногда пользуются реальные люди.
Простая политика, подходящая многим продуктам: блокируйте очевидные недействительные, предупреждайте про disposable и ретрайте временные ошибки (или просите пользователя подтвердить). Запишите выбранную политику, чтобы поддержка и продукт реагировали последовательно.
Затем проведите небольшой эксперимент. Измените одно правило для одного сегмента на короткое время и наблюдайте и качество, и продуктовые результаты. Пример: показывайте предупреждение для disposable на мобильной регистрации неделю и сравните активацию по когортам с предыдущей неделей. Если активация не упала, а доля disposable снизилась — оставьте изменение. Если упала — откатите.
Если хотите согласованную классификацию при регистрации, API валидации email поможет метить invalid, disposable и domain/MX одинаково во всех формах и сервисах. Например, Verimail (verimail.co) предоставляет single‑call validation API с проверками синтаксиса, домена и MX, а также сопоставлением disposable‑провайдеров.
Устраивайте ежемесячный ревью с единственным решением в конце. Достаточно одной страницы: ключевые метрики, самое большое изменение, что пробовали, что измените в следующем месяце и что не будете менять.
Частые вопросы
Что на самом деле означает «качество email» для регистраций?
Качество email означает, что адрес вероятно достижим и низкорисков для вашего продукта. «Хороший» адрес может принимать почту, не относится к disposable-провайдеру и не совпадает с шаблонами, которые часто приводят к bounce или жалобам.
Какие 3 метрики качества email стоит отслеживать в первую очередь?
Начните с трёх метрик: доля недействительных адресов, доля disposable и доля ошибок домена/MX. Вместе они показывают, допускаются ли опечатки, привлекаете ли вы пользователей с низкой мотивацией и мешают ли инфраструктурные или DNS-проблемы доставке.
Что использовать в знаменателе при расчёте долей?
Используйте общее число попыток регистрации как знаменатель, чтобы каждая метрика отвечала: «Из всех, кто пытался зарегистрироваться, у кого была эта проблема?» Держите знаменатель постоянным между неделями, чтобы сравнения оставались корректными.
Зачем нужна корзина «неизвестно»?
«Неизвестно» — это корзина для тайм-аутов, блокировок провайдера и неоднозначных проверок. Она полезна, потому что выделяет проблемы интеграции и временные состояния, которые не стоит тихо помечать как валидные или невалидные.
Стоит ли повторять проверки домена/MX или фиксировать ошибки сразу?
DNS и сетевые проверки могут временно падать, хотя адрес в порядке. Частый подход — фиксировать ошибки при первой попытке (чтобы быстро заметить сбои) и отдельную конечную ошибку после повторных попыток (чтобы оценить реальную достижимость).
Как понять, откуда приходят плохие адреса?
Если смотреть только на общее число по сайту, вы не увидите причину. Сегментируйте сначала по источнику привлечения и месту регистрации, затем добавляйте географию или устройство только при достаточном объёме данных.
Как связать качество email с активацией и другими последствиями?
Отслеживайте уровень активации или подтверждения почты по когортам регистраций и сравнивайте когорты с разным уровнем качества адресов. Если когорты с большим числом disposable или недействительных адресов систематически активируются хуже, это влияет на продуктовые метрики.
Какие пороги ставить для оповещений, чтобы не захламлять команду?
Установите оповещения на основе базовой линии за последние недели и требуйте достаточного объёма, чтобы избежать шума. Практически полезный триггер — когда доля значительно превышает норму и остаётся повышенной достаточно долго, чтобы исключить краткий всплеск.
Какие ошибки чаще всего делают метрики бесполезными?
Главная ошибка — считать попытки вместо уникальных регистраций или сессий, что раздувает долю недействительных адресов при повторных попытках. Ещё одна — менять определения со временем: это создаёт фальшивые всплески; фиксируйте версии и записывайте изменения с датой.
Стоит ли блокировать disposable-адреса или просто предупреждать пользователей?
Блокируйте явно недействительные адреса и жёсткие ошибки домена/MX — они редко становятся реальными пользователями. К disposable и временным ошибкам применяйте более мягкую политику: предупреждение, дополнительная верификация или усиленная проверка для рискованных сегментов, чтобы не повредить легитимным конверсиям.